
Spark的job调优(1)
本文翻译之cloudera的博客,本系列有两篇,第二篇看心情了
概论
当我们理解了transformation,action和rdd后,我们就可以写一些基础的spark的应用了,但是如果需要对应用进行调优就需要了解spark的底层执行模型,理解job,stage,task等概念。
本文你将会了解spark程序是怎么在机器上执行的,同时也学到一些实用的建议关于什么样的执行模型可以提高程序效率
Spark如何执行应用
一个spark程序包括一个driver进程和多个分散在集群节点上的executor进程,driver负责工作流程,executor负责以task方式执行工作同时也会存储一些数据,在程序运行的整个生命周期里driver和executor会一直存活,尽管后期动态资源分配可能会改变这种情况,每个executor都有一些任务槽用于并发运行task,部署这些进程到集群中依赖所选的集群部署方式(standalone,mesos,yarn),但是driver和executor存在每一个spark程序中
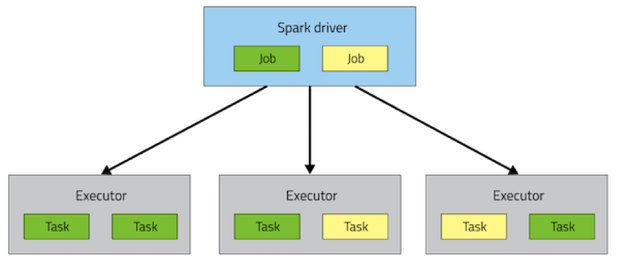
当在spark中执行一个action会触发一个spark的job的提交,为了了解该job是什么样的,spark会通过RDD的DAG来确定该action依赖什么,同时生成一个执行计划,该计划从一个最远的RDD开始,通常该RDD不依赖别的RDD或者是一个缓存的数据到一个生成Action结果的最终的RDD
执行计划包含了一些stages,stage是由tranformation组装生成的,一个stage对应一组执行相同代码的task,每一个task处理不同的数据,每个stage包含一系列的transformation,这些transformation执行的时候不需要shuffler数据
什么决定哪些数据需要进行shuffle, 一个RDD由固定数量的partition组成,每个partition是由许多记录组成的,对于哪些通过窄依赖的transformation(比如map,filter)返回的RDD,它的partition中的一个记录是从
它父RDD中一个parition的一个记录计算得到的,子RDD一个partition只依赖父RDD中的一个partition,像coalesce这种的操作会导致一个task计算父RDD中多个partition,但是仍把他看做窄依赖,因为只依赖一部分的partition.
spark还支持像groupbyke和reducebykey这样的宽依赖,这样计算子RDD中一个partition的一条记录依赖父RDD中许多partition中的记录,具有相同key的所有tuple最终会放到在同一个partition中,然后被同一个task处理,为了满足这种操作,spark必须进行shuffle,通过在集群的节点间传输数据最终生成一个新的stage和新的partition集合。(同一个stage中所有的RDD的partition数据应该不一致)
例如
sc.textFile("someFile.txt").map(mapFunc).flatMap(flatMapFunc).filter(filterFunc).count()
该代码最后执行了一个action的操作,它依赖对数据源是一个文本文件的RDD一系列的转换,该代码会在一个stage中执行,因为他们只窄依赖。
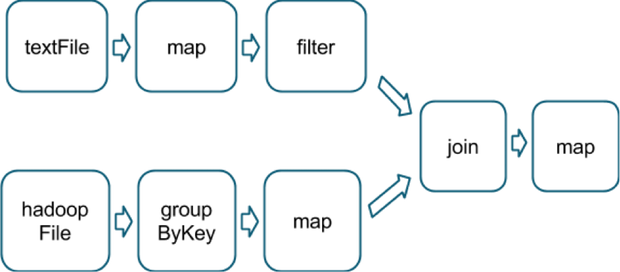
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))val wordCounts = tokenized.map((_,1)).reduceByKey(_ + _)val filtered = wordCounts.filter(_._2 >=1000)val charCounts = filtered.flatMap(_._1.toCharArray).map((_,1)).reduceByKey(_ + _)charCounts.collect()
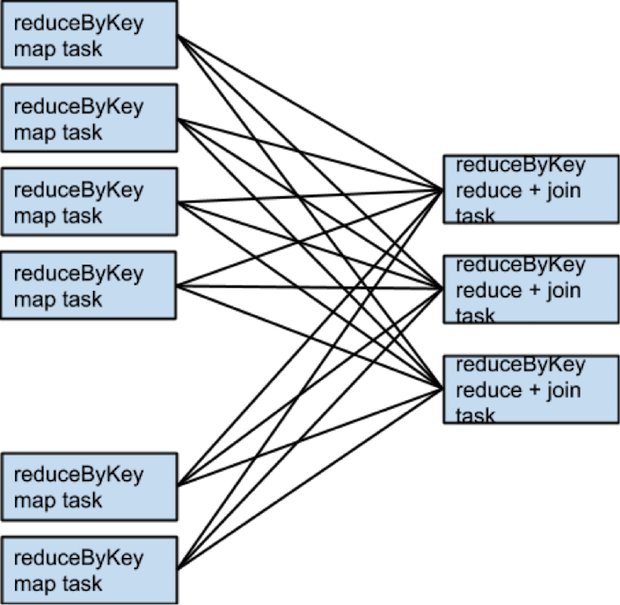
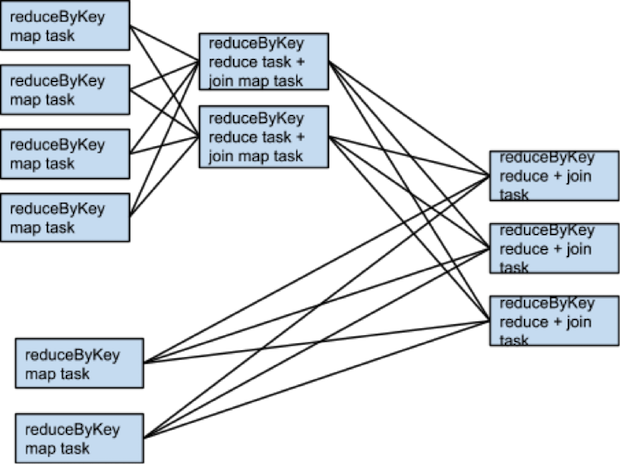
上面代码将会分成3个stage进行执行,reduceByKey操作会产生一个stage边界,因为计算它的输出需要数据按key进行重新分区。下图是一个RDD的转换图。
下面粉色的线划分出需要执行的stage
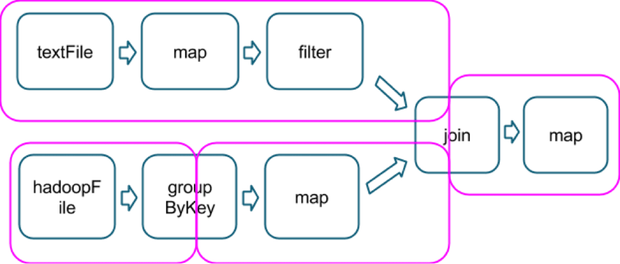
在每一个stage的边界,父stage中的task会把数据写入到磁盘上,子stage中的task会通过网络去获取数据,因为这样会加重磁盘和网络的负担,stage边界代价太高应该尽可能的避免,父stage中数据的partition可能和子stage中的partition的数据不一致。那么会导致stage边界的转换函数都会接受一个numPartition的参数用于确定子stage中数据的partition个数。
对于mapreduce应用来说reducer的个数是一个重要的参数,调整stage边界中partition的个数通常可以提高或降低spark应用的性能,下面讲下如何有效调整该参数。
选择正确的操作
当使用spark编写应用时,开发者可以组装不同的transformation和action生成相同的结果,但是不是所有组装的性能都是一样的,选择正常的组装方式可以大大提供应用的性能,一些规则和观点可以帮助做出正确的选择。
ShemaRDD正慢慢稳定下,它将开放Spark的catalyst优化器给使用spark core的开发者使用,它将spark可以做一些高级的选择:哪些操作可以使用,当ShemaRDD变成一个稳定模块后,用户就可以避免做这样的选择了。
选择操作的组装方式的目标为了减少shuffle的数量和shuffler数据的数量,这是因为shuffler是一个很昂贵的操作,所有的数据必须落盘然后再通过网络传输,repatition,join,cogroup和别的一些以*key和*bykey结尾的transformation操作都会导致shuffle, 但是性能是不一样的,初学者遇到的最大问题就是不明白他们的操作成本,
- 当执行一个associative reductive 操作时不要使用groupbykey,例如。 rdd.groupbykey().mapValues(_.sum)和rdd.reduceBykey(_+_)的结果一样,但是前面的操作会导致所有的数据进行网络传输,后者只会先在本地计算每个patition相同key的和,然后通过shuffler合并所有本地计算的和(都会有shuffle,但是传输的数据减少了很多)
- 当输入和输出的类型不一样时不要使用reduceByKey,例如
当写一个transformation用来找到每一个key对应唯一的一个字符串是,一种方式如下:rdd.map(kv => (kv._1, new Set[String]() + kv._2)).reduceByKey(_ ++ _),该操作会导致大量的不必要的set对象,每个key都会创建一个,这里最好使用aggregateBykey,它会执行map端的聚集更有效val zero =new collection.mutable.Set[String]()rdd.aggregateByKey(zero)((set, v)=> set += v,(set1, set2)=> set1 ++= set2)
3. 不要使用flatMap-join-groupBy的模式。当两个数据集已经groupbykey后,如果想join后继续分组,可以使用cogroup,这将建少很多That avoids all the overhead associated with unpacking and repacking the groups.
什么时候shuffle不会发生
需要注意哪些场景下上面的transformation不会有shuffle,spark知道怎么避免shuffle当前面的transformation时数据被同一个patitioner分区过。
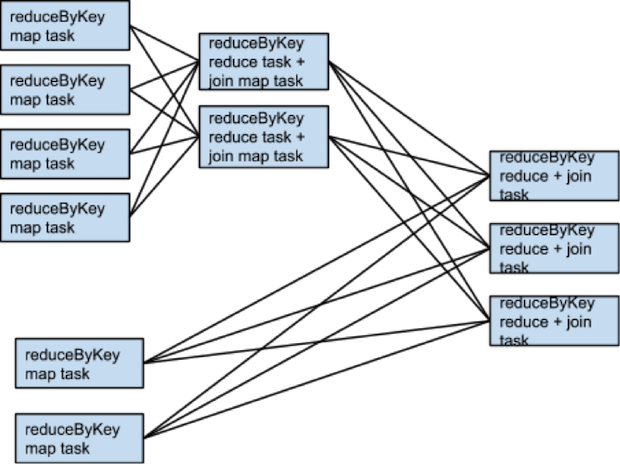
rdd1 = someRdd.reduceByKey(...)rdd2 = someOtherRdd.reduceByKey(...)rdd3 = rdd1.join(rdd2)
该例子中reduceByKey使用默认的patitioner,所有rdd1和rdd2都是哈希分区的,两个RDD会有两次的shuffler,如果两个RDD的parttion的个数相同,join就不需要额外的shuffle了,因为两个RDD被同一个partitioner分区,相同key的数据都落在两个RDD上的单独的一个parition上。所有rdd3的一个partition只依赖rdd1和rdd2中的单独的partition
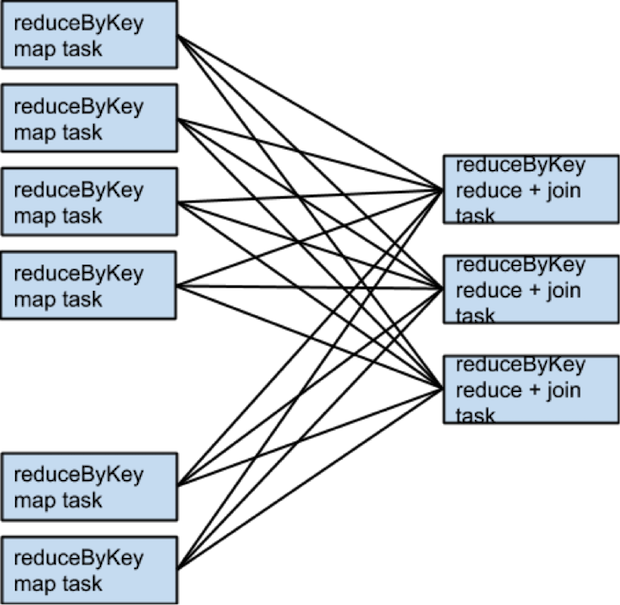
注意,这里是任务的执行模型,不是parition的模型,
如果两个RDD的parition使用不同的partitioner,那么join可能需要shuffle
当两个数据集做join时避免shuffle的另一种方式就是使用广播变量,当一个数据集小的足够塞到一个executor内存中,它可以被加载到driver的一个hashtable中然后广播到每一个executor中。一个map的transformation引用该hashtable做join
什么时候需要更多的shuffle
多数情况下shuffle对性能有消耗,但是有时候额外的shuffle可以增大并发而提高性能,例如,数据存储在一个不可切分的文件中(压缩文件),InputFormat进行分区是可能会导致大量的记录在一个partition中,parition的个数少不能有效利用集群计算资源,这种情况下,当数据加载完成后执行repatition操作,它会导致shuffle但是可以利用集群更多的计算资源
还一种情况就是使用reduce和aggregate等action在driver上进行数据聚集,当聚集大量数目的partition时,
driver上由于使用一个线程用来合并这些结果将成为性能的瓶颈,为了减轻driver的压力,可以调用reduceBykey和aggregateByKey执行一个分布式聚集操作,把数据切分中更小的parition, 每个partion并行的合并数据,然后把结果返回给driver执行最终的聚集,
二次排序
还一个需要注意的就是repartitionAndSortWithinPartitions这个transformation,该transformation在shuffler的时候就行排序,这样大量数据落盘的时候可以进行排序然后方便后面的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号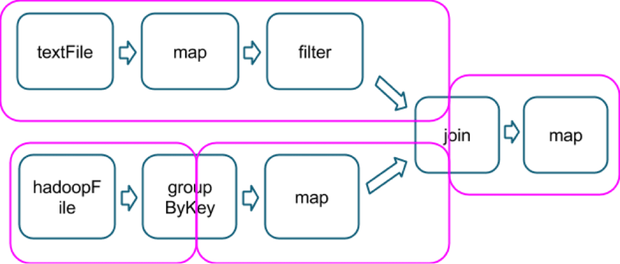{kind=link}
{kind=link}
{kind=link}