catboost学习笔记
原文链接
优势对比
CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现。
正如其名字所说那样,CatBoost主要是在类别特征上的处理上做了很多的改进。
从用户使用角度来看,相比XGBoost和LightGBM,CatBoost具有如下特点。
模型精度:XGBoost和LightGBM相当,CatBoost往往略好一些,无需调参即可获取很好的结果。
训练速度:LightGBM远快于XGBoost,CatBoost快于XGBoost但比LightGBM慢。
预测速度:LightGBM与XGBoost相当,CatBoost远快于LightGBM与XGBoost,是它们的几十分之一。
内存消耗:LightGBM远小于XGBoost,CatBoost小于XGBoost,但大于LightGBM。
类别特征:XGBoost不支持类别特征,需要OneHot编码预处理。LightGBM支持类别特征,需转换成整数编码。CatBoost提供更强大的对类别特征的支持,直接支持字符串类型的类别特征,无需预处理。
缺失值特征:XGBoost和LightGBM都可以自动处理特征缺失值,CatBoost不能自动处理缺失值(或者将缺失值视为最小值/最大值)。
GPU支持:LightGBM与CatBoost支持GPU训练,XGBoost不支持GPU训练。
可视化:CatBoost还自带一套可视化工具,可以在Jupyter Notebook或者TensorBoard中实时看到指标变化。
创新点
CatBoost主要创新点如下:
1.类别特征的 Ordered Target Statistics 数值编码方法。
其次,它用特殊的方式处理categorical features。
首先他们会计算一些数据的statistics。计算某个category出现的频率,加上超参数,生成新的numerical features。这一策略要求同一标签数据不能排列在一起(即先全是0之后全是1这种方式),训练之前需要打乱数据集。
第二,使用数据的不同排列(实际上是4个)。在每一轮建立树之前,先扔一轮骰子,决定使用哪个排列来生成树。
第三,考虑使用categorical features的不同组合。例如颜色和种类组合起来,可以构成类似于blue dog这样的feature。当需要组合的categorical features变多时,catboost只考虑一部分combinations。在选择第一个节点时,只考虑选择一个feature,例如A。在生成第二个节点时,考虑A和任意一个categorical feature的组合,选择其中最好的。就这样使用贪心算法生成combinations。
第四,除非向gender这种维数很小的情况,不建议自己生成one-hot vectors,最好交给算法来处理。参考
target statistic详解
1.1 什么是预测偏移?
在GBDT一类模型中,弱学习器模型均在同一完整训练集上训练,然后不断提升成强学习器,但如果训练集和测试集存在分布不一致,模型就会过拟合训练集而在测试集上表现不好 (即预测偏移到训练集上),预测偏移也算是目标泄露 (Target Leakage)的一种。
预测偏移发生在哪里?
预测偏移发生在两个地方:类别特征编码和梯度提升方法。
(1) 类别特征编码中的预测偏移
-
GBDT:直接把类别型当作连续型数据对待。
-
XGBoost:建议提前对类别特征One-hot编码后再输入模型。
-
LightGBM:在每步梯度提升下,将类别特征转为GS (梯度统计Gradient Statistics)。注:很对不起,【务实基础】LightGBM 中 “5. 支持类别特征” 这块存在错误,LGBM不是采用TS编码 (目标统计Target Statistics,即平均值sum(y)count(y),而是GS编码,将类别特征转为累积值sum( gradient )sum( hessian ), (一阶偏导数之和/二阶偏导数之和)再进行直方图特征排序 [2]。
虽然LGBM用GS编码类别特征看起来挺厉害的,但是存在两个问题:
计算时间长:因为每轮都要为每个类别值进行GS计算。
内存消耗大:对于每次分裂,都存储给定类别特征下,它不同样本划分到不同叶节点的索引信息。
为了克服以上问题,LGBM将长尾特征聚集到一类,但也因此丢失了部分信息。对此,Catboost作者认为,LGBM的GS没有TS好,因为TS省空间且速度快,每个类别存一个数就好了。但TS不是完美的,因为它存在预测偏移。这很明显,因为TS是依赖训练集的目标标签进行类别特征编码(算是目标泄露),如果训练集和测试集分布过大,那么类别编码就会偏移向训练集,导致模型的通用性差。
如果我们要了解“预测偏移是怎么发生在TS类别特征编码 (也称目标编码Target Encoding) 过程当中?”,我们得先了解下TS的编码机制。
一个有效且高效处理类别型特征的方法是用一个 TS编码的数值型变量 ˆxki 来替代第 k 个训练样本的 类别 xki 。通常来说, TS是基于类别的目标变量 y 的期望来进行估算: ˆxik≈E(y∣xi=xik) 。 直白来说, ˆxik 是 TS 编码值, E(y∣xi=xik) 是基于目标变量y估算函数。
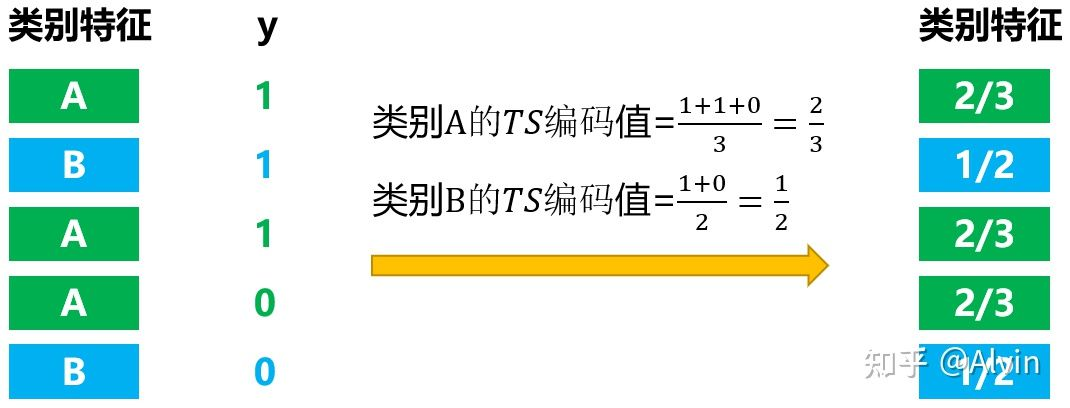
图1: Greedy TS编码方式
估算函数最直接方式就是采用训练集中相同类别的 xki 样本的目标变量y的平均值, 如上图所示。 这种估算方式在低基类别上有噪声, 因此常常会加先验概率p进行平滑:
i指示类别i, k 指示样本 k 。而 I{xji=xik} 的意思是判断:当前样本j是否与样本 k 是同一类别i, 如果是则为 1 , 反之则为 0 。而先验概率 p 为数据集所有目标值的均值, α 是控制先验参与编码的 权重。
现在, 我们举个具体的例子, 看下预测偏移是怎么影响模型通用性。假设特征为类别型且它的值 都是独特的 (unique)。那么如果TS编码就会发生严重的目标泄露, 如下图所示:
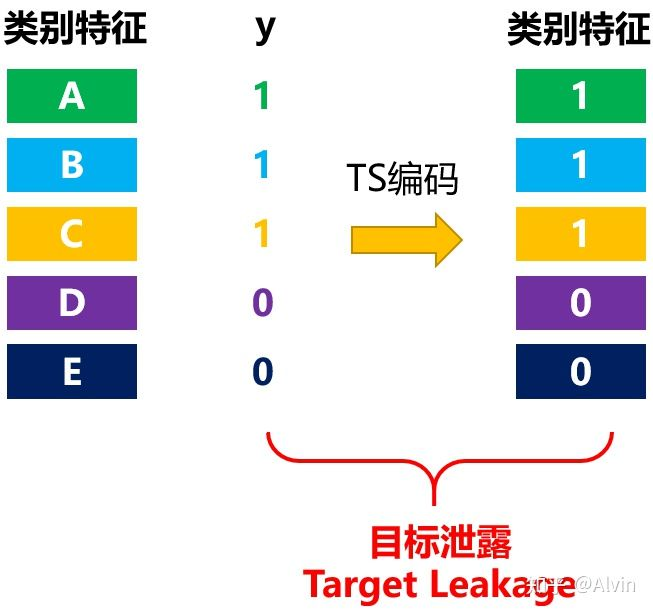
图2: Greedy TS编码出现目标泄露的样例
有几种方法可以避免条件偏移 (Conditional shift)。其中一个通用的想法是为x_k计算其TS时, 用 除去 xk 后的样本集 Dk 去计算, Dk⊂D∖{xk} 。
(2) 梯度提升方法中的预测偏移
我们已经知道TS因目标泄露带来预测偏移。那接下来, 我们来看下GBDT一类模型中, 它们梯度提 升方法里的预测偏移是在哪发生的。我们先简单回顾下GBDT的梯度提升方法。假设我们上一轮获 得强学习器 Ft−1, 那么, 当前第 t 轮下的强学习器为: Ft=Ft−1+αht。ht 为第t轮的弱 学习器, α 为学习率。 ht 目标是使损失函数最小化:
最小化问题可通过牛顿法或梯度下降求解。在梯度下降中, GBDT是用损失函数的负梯度去帮助拟 合, 负梯度如下:
还记得我在之前文章里说过, GBDT当前轮的弱学习器是拟合上一轮的负梯度值, 因此, ht 可以 为:
如果训练集和测试集分布不一致, 那么用训练集得到的梯度值分布就跟测试集的梯度值分布不一 致, 那么便会有预测偏移, 最终影响了模型的通用性。
order taget statistic
Catboost针对类别特征TS编码时发生的预测偏移采用了Ordered TS方法,针对梯度提升方法中的偏移采用Ordered Boosting方法。
a: Ordered TS
之前在背景里有讲Greedy TS的编码思路,但其实还有其它TS编码方式。这里,我根据论文整理了下Greedy TS、Holdout TS和Leave-one-out TS的编码思路对比图如下:
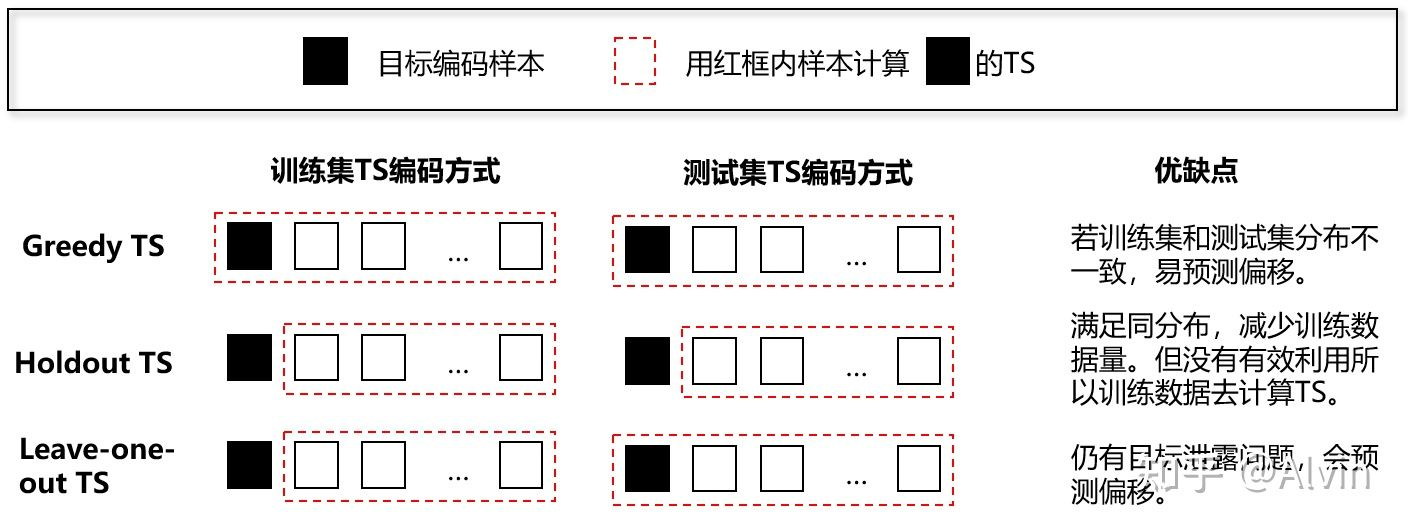
图3:其它常见TS编码方式对比图
我们发现, 常见的TS的编码方式没有平衡好"充分利用数据集“和"目标泄露“。Catboost作者受到 在线学习算法 (即随时间变化不断获取训练集) 的启发, 提出了Ordered TS。Ordered TS是基于排 序原则, 对于每个样本的TS编码计算式依赖于可观测的样本。为了使这个想法符合标准线下设 定, 作者人为构造了"时间"。具体步骤如下:
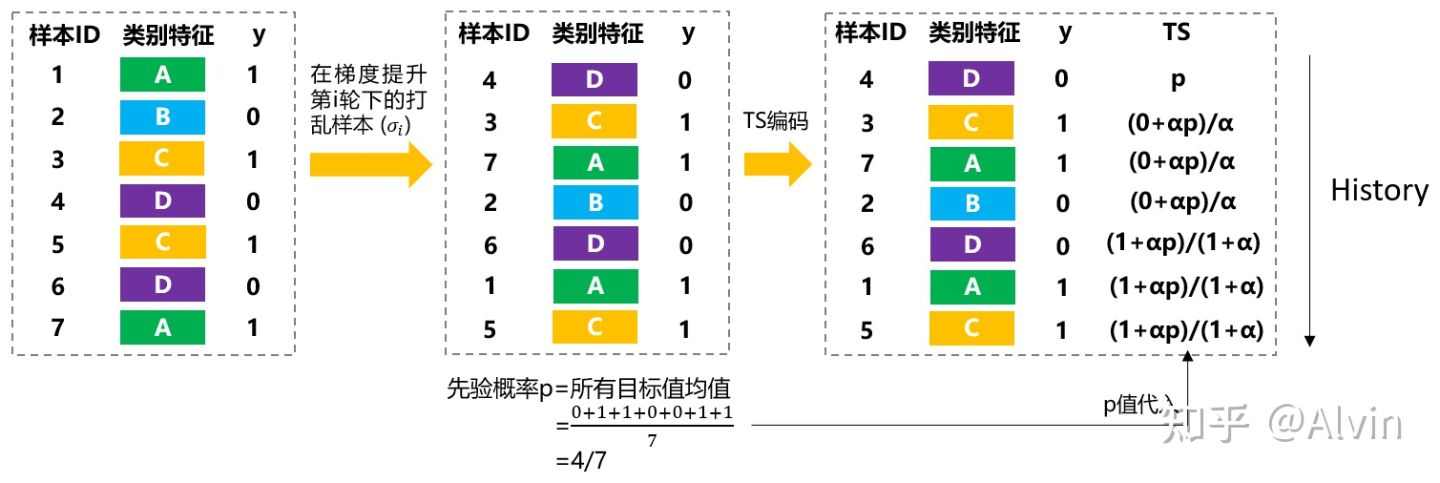
(1) 随机打乱训练集, 获取一个随机排列顺序 σ 。
(2) 在训练集中, 用 xk 的"历史"样本去计算样本 xk 的TS, 即训练集采用 Dk={xj:σ(j)<σ(k)} 。
(3) 在测试集中, 用全测试集数据去计算 xk 的 TS 。
该方法既充分利用了数据集, 又避免了目标泄露。 Dk=D 注意如果只用一个随机排列顺序, 那 么最高进行 TS 编码的样本会比后面才TS编码的样本具有更高方差 (即先编码比后编码更欠拟合), 因此, Catboost在不同梯度提升轮数中采用不同的排列顺序去计算 TS, 这样模型的方差会变低, 利于拟合。
为了方便理解,我画了个Ordered TS的计算样例图:
其余参考推断参考:https://zhuanlan.zhihu.com/p/346420728
2.基于贪心策略的特征组合方法。
3.避免预测偏移的 Ordered Boosting 方法。
4.使用对称二叉树作为基模型,有正则作用且预测极快。
Catboost使用对称树。XGboost一层一层地建立节点,lightGBM一个一个地建立节点,而Catboost总是使用完全二叉树。它的节点是镜像的。Catboost称对称树有利于避免overfit,增加可靠性,并且能大大加速预测等等。
具体可以参考这篇文章:https://www.zhihu.com/question/311641149/answer/593286799
原理推导
个人觉得这个写的很详细,看上去是读过原文的https://zhuanlan.zhihu.com/p/102570430?utm_source=qq
代码实现
https://catboost.ai/en/docs/concepts/python-installation
参考文章
Anna Veronika Dorogush, Andrey Gulin, Gleb Gusev, Nikita Kazeev, Liudmila Ostroumova Prokhorenkova, Aleksandr Vorobev "Fighting biases with dynamic boosting". arXiv:1706.09516, 2017
Anna Veronika Dorogush, Vasily Ershov, Andrey Gulin "CatBoost: gradient boosting with categorical features support". Workshop on ML Systems at NIPS 2017

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步