BYOL&SwAV学习笔记
笔者把两篇论文放一起了,快速过下idea
第一篇:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
在讲这篇论文之前,先从自监督训练的崩塌问题开始说起。我们知道现在大部分的自监督训练都是通过约束同一张图的不同形态之间的特征差异性来实现特征提取,不同形态一般通过指定的数据增强实现,那么如果只是这么做的话(只有正样本对),网络很容易对所有输入都输出一个固定值,这样特征差异性就是0,完美符合优化目标,但这不是我们想要的,这就是训练崩塌了。因此一个自然的想法是我们不仅仅要拉近相同数据的特征距离,也要拉远不同数据的特征距离,换句话说就是不仅要有正样本对,也要有负样本对,这确实解决了训练崩塌的问题,但是也带来了一个新的问题,那就是对负样本对的数量要求较大,因为只有这样才能训练出足够强的特征提取能力,因此我们可以看到这方面的代表作如SimCLR系列都需要较大的batch size才能有较好的效果。「AI之路」
BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network.
BYOL有两个网络,一个online network一个target network,两个网络互相学习对方,利用图像的数据增强来训练网络去预测同一图像在不同数据增强下的target network的表示。同时,用online network的慢移动平均值来更新target网络。
稍微有点蒸馏的赶脚,继续看~
While state-of-the art methods rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches \(74.3 \%\) top-1 classification accuracy on ImageNet using a linear evaluation with a ResNet-50 architecture and \(79.6 \%\) with a larger ResNet.
BYOL并没有依赖于大量的负例,在ResNet-50上做土图像分类能达到\(74.3 \%\)的准确率,在更大的ResNet上能达到\(79.6 \%\)的准确率。
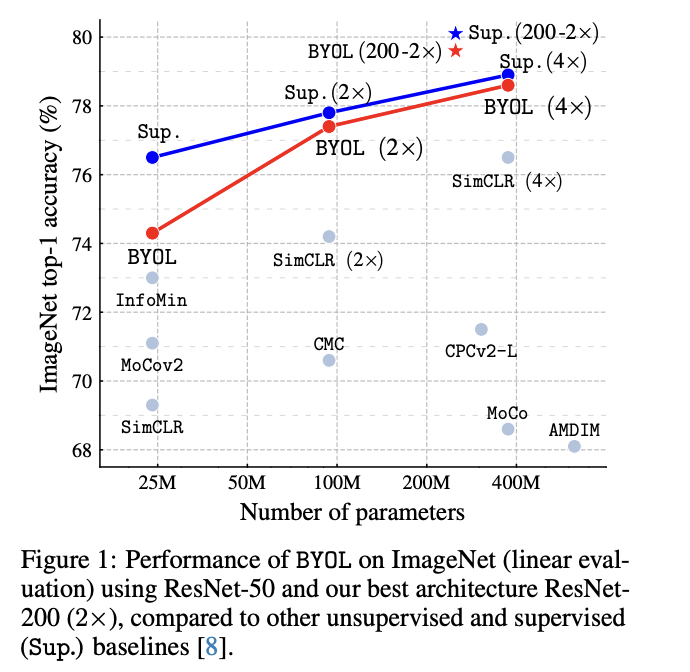
ResNet-50和ResNet-200+的对比效果,参数量级越大的时候越接近监督学习的效果。
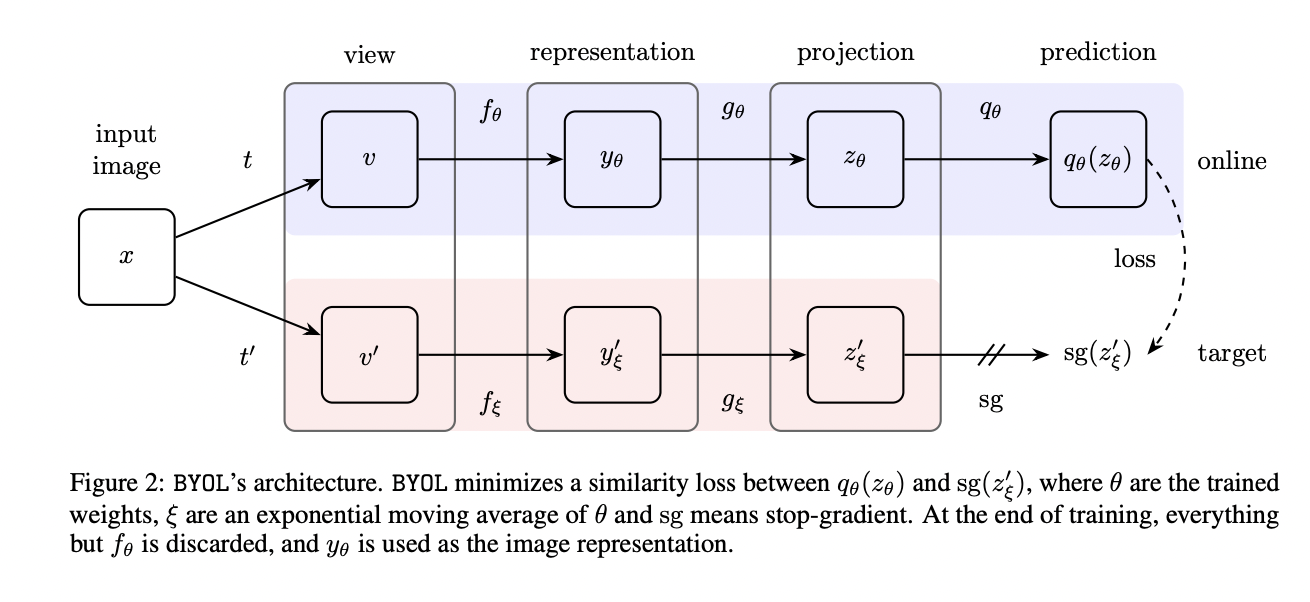
BYOL的整体结构
通过约束这2个网络输出特征的均方误差(MSE)来训练online network,而target network的参数更新取决于当前更新后的online network和当前的target network参数,这也就是论文中提到的slow-moving average做法,灵感来源于强化学习。
To prevent collapse, a straightforward solution is to use a fixed randomly initialized network to produce the targets for our predictions. While avoiding collapse, it empirically does not result in very good representations. Nonetheless, it is interesting to note that the representation obtained using this procedure can already be much better than the initial fixed representation. In our ablation study (Section 5), we apply this procedure by predicting a fixed randomly initialized network and achieve \(18.8 \%\) top-1 accuracy (Table 5a) on the linear evaluation protocol on ImageNet, whereas the randomly initialized network only achieves \(1.4 \%\) by itself. This experimental finding is the core motivation for BYOL: from a given representation, referred to as target, we can train a new, potentially enhanced representation, referred to as online, by predicting the target representation. From there, we can expect to build a sequence of representations of increasing quality by iterating this procedure, using subsequent online networks as new target networks for further training. In practice, BYOL generalizes this bootstrapping procedure by iteratively refining its representation, but using a slowly moving exponential average of the online network as the target network instead of fixed checkpoints.
为了防止模型坍塌,首先有一个网络参数随机初始化且固定的target network,target network的top1准确率只有1.4%,target network输出feature作为另一个叫online network的训练目标,等这个online network训练好之后,online network的top1准确率可以达到18.8%,这就非常有意思了,假如将target network替换为效果更好的网络参数(比如此时的online network),然后再迭代一次,也就是再训练一轮online network,去学习新的target network输出的feature,那效果应该是不断上升的,类似左右脚踩楼梯不断上升一样。BYOL基本上就是这样做的,并且取得了非常好的效果。这里也就搞明白了,并没有蒸馏的思想。
BYOL's goal is to learn a representation \(y_{\theta}\) which can then be used for downstream tasks. As described previously, BYOL uses two neural networks to learn: the online and target networks. The online network is defined by a set of weights \(\theta\) and is comprised of three stages: an encoder \(f_{\theta}\), a projector \(g_{\theta}\) and a predictor \(q_{\theta}\), as shown in Figure 2 and Figure 8 .** The target network has the same architecture as the online network,** but uses a different set of weights \(\xi\). The target network provides the regression targets to train the online network, and its parameters \(\xi\) are an exponential moving average of the online parameters \(\theta[54] .\) More precisely, given a target decay rate \(\tau \in[0,1]\), after each training step we perform the following update,
online network 和target network网络结构是一样的,但是网络参数不共享,online network包括三个部分encoder,projector和一个predictor,损失函数也不同,target network受用mse更新online network
Given a set of images \(\mathcal{D}\), an image \(x \sim \mathcal{D}\) sampled uniformly from \(\mathcal{D}\), and two distributions of image augmentations \(\mathcal{T}\) and \(\mathcal{T}^{\prime}\), BYOL produces two augmented views \(v \triangleq t(x)\) and \(v^{\prime} \triangleq t^{\prime}(x)\) from \(x\) by applying respectively image
augmentations \(t \sim \mathcal{T}\) and \(t^{\prime} \sim \mathcal{T}^{\prime}\). From the first augmented view \(v\), the online network outputs a representation \(y_{\theta} \triangleq f_{\theta}(v)\) and a projection \(z_{\theta} \triangleq g_{\theta}(y) .\) The target network outputs \(y_{\xi}^{\prime} \triangleq f_{\xi}\left(v^{\prime}\right)\) and the target projection \(z_{\xi}^{\prime} \triangleq g_{\xi}\left(y^{\prime}\right)\) from the second augmented view \(v^{\prime} .\) We then output a prediction \(q_{\theta}\left(z_{\theta}\right)\) of \(z_{\xi}^{\prime}\) and \(\ell_{2}\) -normalize both \(q_{\theta}\left(z_{\theta}\right)\) and \(z_{\xi}^{\prime}\) to \(\overline{q_{\theta}}\left(z_{\theta}\right) \triangleq q_{\theta}\left(z_{\theta}\right) /\left\|q_{\theta}\left(z_{\theta}\right)\right\|_{2}\) and \(\bar{z}_{\xi}^{\prime} \triangleq z_{\xi}^{\prime} /\left\|z_{\xi}^{\prime}\right\|_{2}\). Note that this predictor is only applied to the
online branch, making the architecture asymmetric between the online and target pipeline. Finally we define the following mean squared error between the normalized predictions and target projections,
定义的mse损失函数
其他的具体推到,笔者略
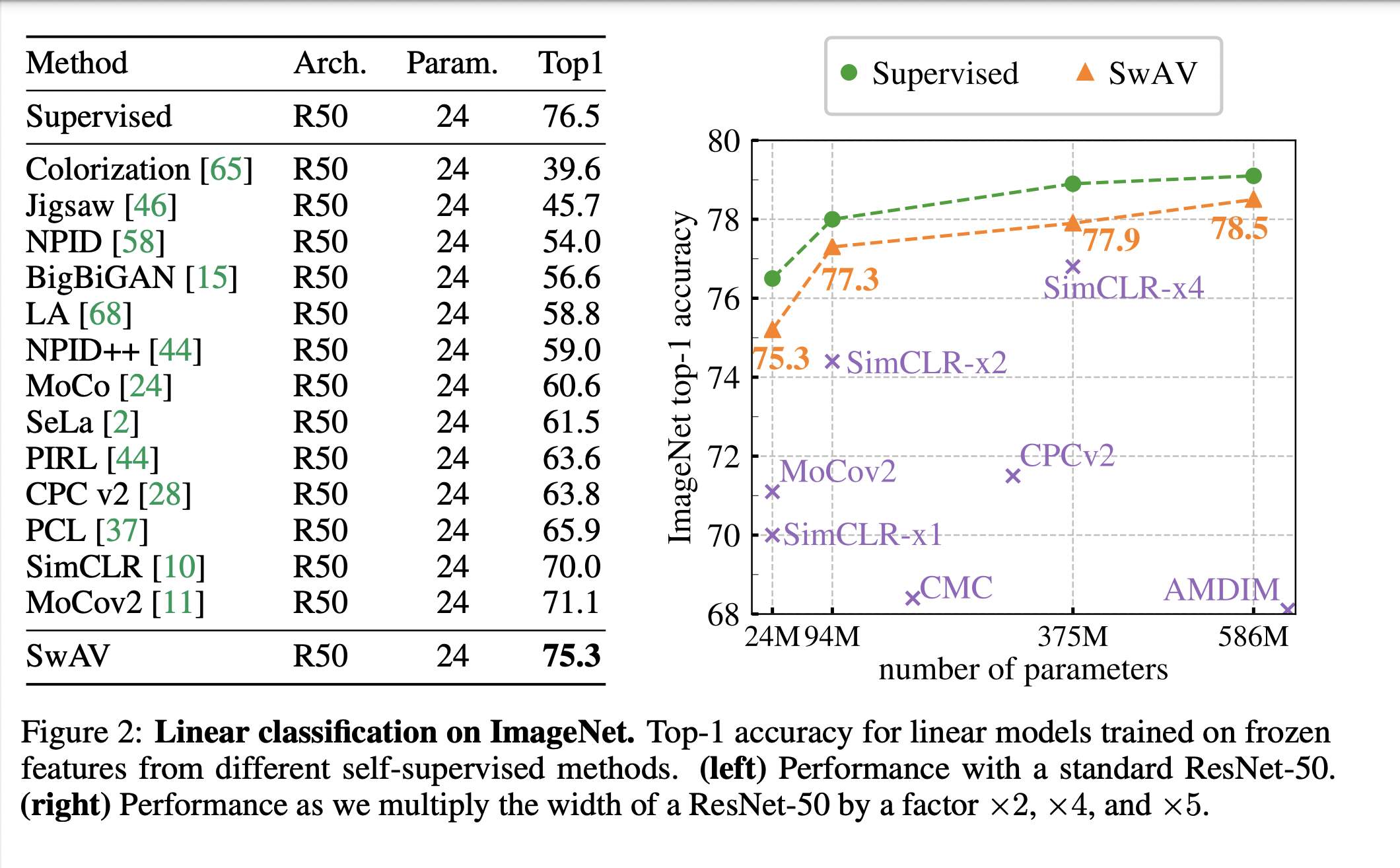
实验效果
-
线性分类集上分别使用50层的参数和50+层的残差,效果都超过了simclr和moco,甚至有任务上超过了moco_v2
-
半监督学习
效果也是优于simclr的
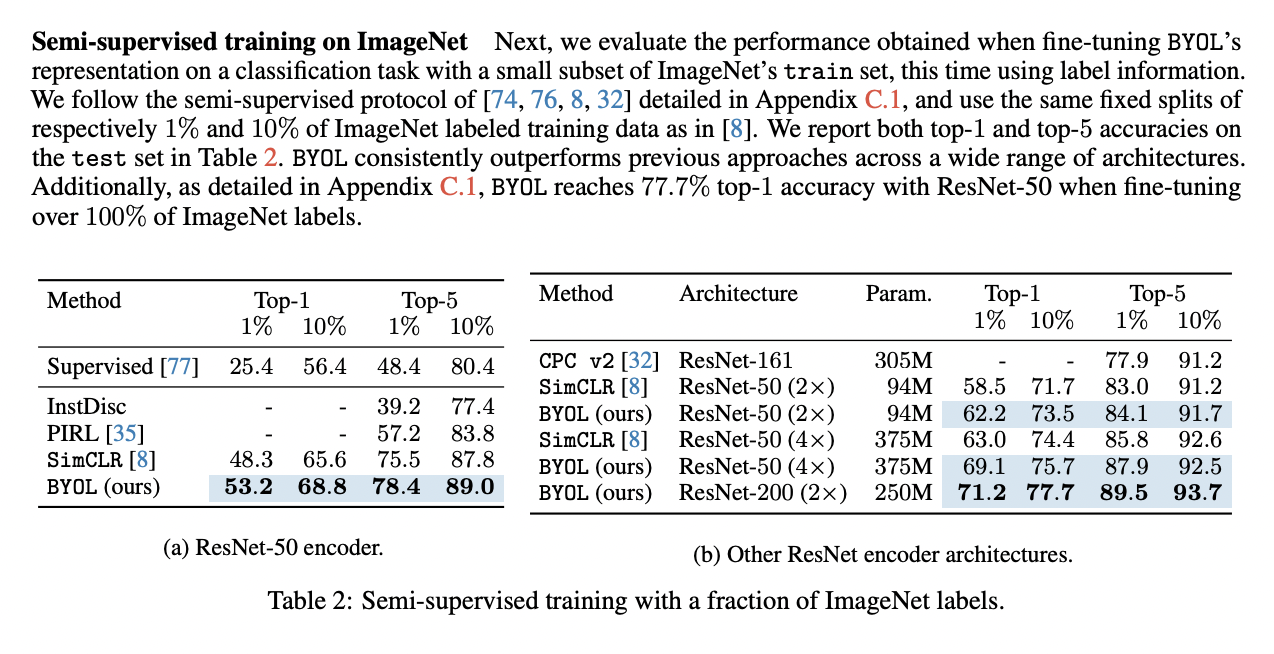
- 迁移学习的下游任务
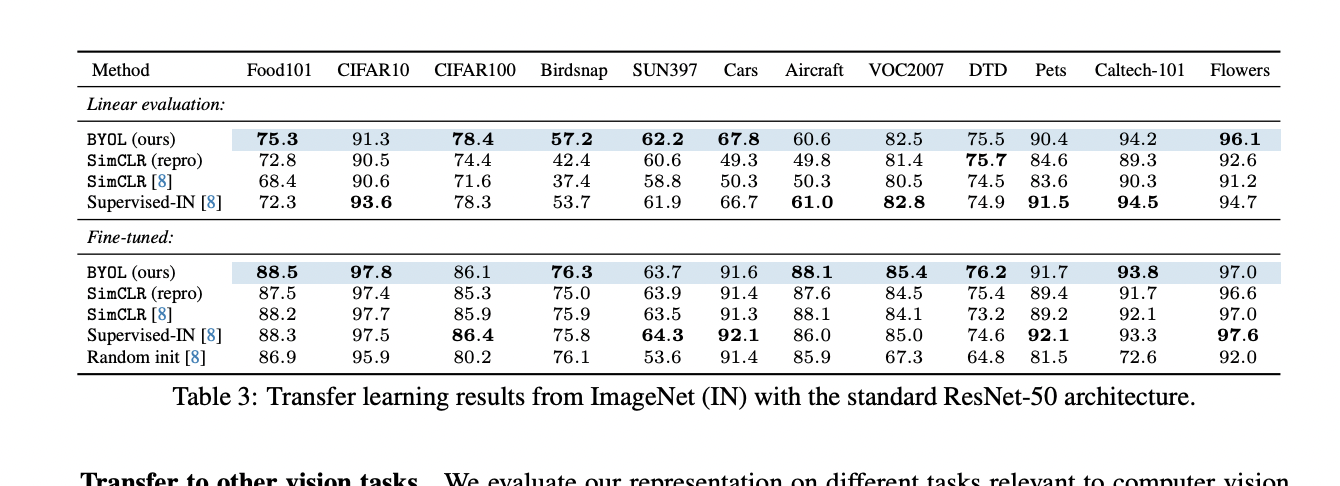
在table5(b)中做了关于predictor、target network和是否有负样本对的充分对比实验,在beta=0时表示没有负样本对,可以看到此时的SimCLR不管是增加predictor还是target network,效果都非常差,注意看(b)中第一行和倒数第二行的对比,差别只在于有没有predictor,此时效果差异是巨大的,这说明Predictor的存在,是BYOL模型不坍塌的最关键因素,但是要配置大的学习率。此外,有其它研究[参考:Understanding self-supervised and contrastive learning with bootstrap your own latent (BYOL).]指出,Predictor中的BN在其中起到了主要原因,因为BN中采用的Batch内统计量,起到了类似负例的作用。但是很快,BYOL的作者在另外一篇文章里[参考:BYOL works even without batch statistics]对此进行了反驳,把Predictor中的BN替换成Group Norm+Weight standard,这样使得Predictor看不到Batch内的信息,同样可以达到采用BN类似的效果,这说明并非BN在起作用。
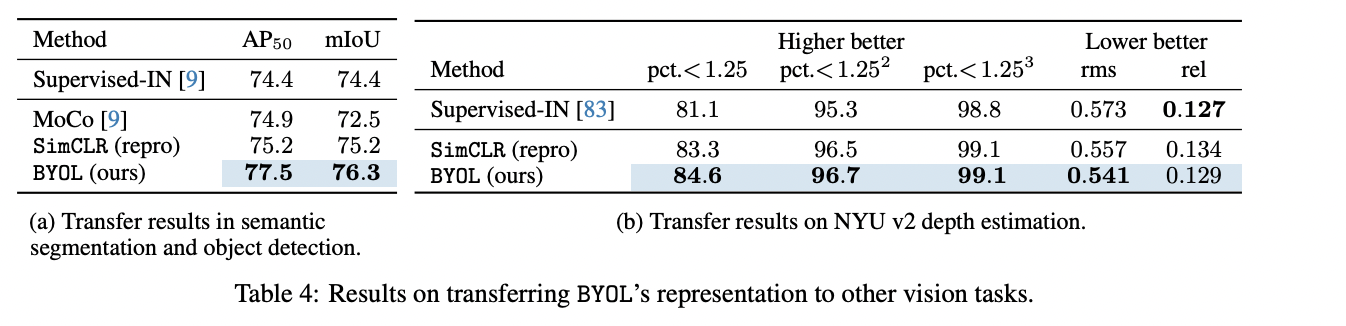
- 对batch size的需求
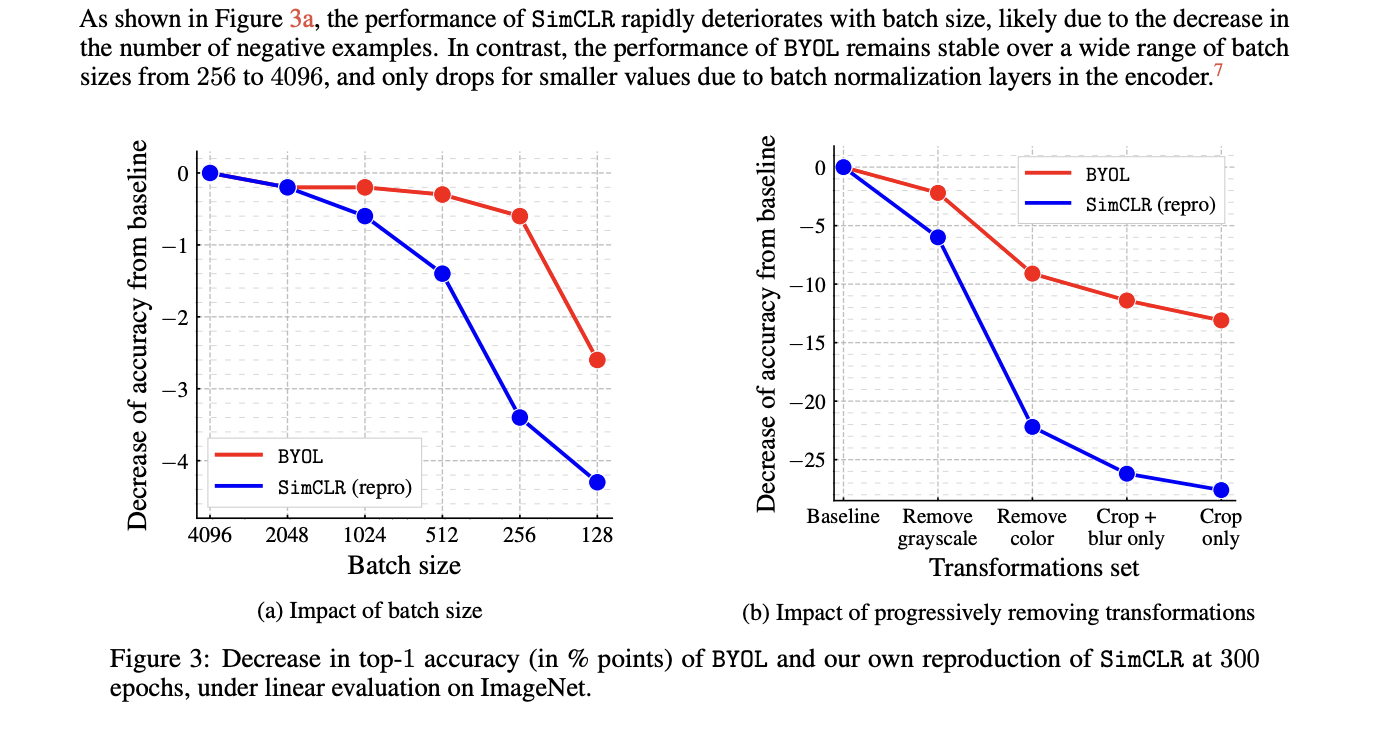
BYOL相比SimCLR系列优势在于前者对batch size和数据增强更加鲁棒,论文中也针对这2个方面做了对比实验,如Figure3所示。大batch size对于训练机器要求较高,在SimCLR系列算法中主要起到提供足够的负样本对的作用,而BYOL中没有用到负样本对,因此更加鲁棒。数据增强也是同理,对对比学习的影响比较大,因此这方面BYOL还是很有优势的。
SwAV
题目:Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
论文地址:https://arxiv.org/abs/2006.09882
这篇论文正文10页,附录也10页
从题目中就可以看出这篇文章是讲聚类对比学习的
In this paper, we propose an online algorithm, SwAV, that takes advantage of contrastive methods without requiring to compute pairwise comparisons. Specifically, our method simultaneously clusters the data while enforcing consistency between cluster assignments produced for different augmentations (or "views") of the same image, instead of comparing features directly as in contrastive learning. Simply put we use a "swapped" prediction mechanism where we predict the code of a view from the representation of another view. Our method can be trained with large and small batches and can scale to unlimited amounts of data. Compared to previous contrastive methods, our method is more memory efficient since it does not require a large memory bank or a special momentum network.
- 通过聚类的方式,得到每个类别的聚类簇,对比学习去对比每个聚类类别的关系
- 可以使用大batch size 也可以使用小batchsize
主要内容
- We propose a scalable online clustering loss that improves performance by \(+2 \%\) on ImageNet and works in both large and small batch settings without a large memory bank or a momentum encoder.
可以在大批量和小批量设置下工作,而无需大型内存库或动量编码器。提升了2%个点
- We introduce the multi-crop strategy to increase the number of views of an image with no computational or memory overhead. We observe a consistent improvement of between \(2 \%\) and \(4 \%\) on ImageNet with this strategy on several self-supervised methods.
引入multi-crop 策略进行数据增强,在几个自监督的测试中提升了2%-4%
- Combining both technical contributions into a single model, we improve the performance of selfsupervised by \(+4.2 \%\) on ImageNet with a standard ResNet and outperforms supervised ImageNet pretraining on multiple downstream tasks. This is the first method to do so without finetuning the features, i.e., only with a linear classifier on top of frozen features.
两种技术?合并到一个模型中,在自监督学习中提升了\(+4.2 \%\)
主要方法
In this section, we describe an alternative where we enforce consistency between codes from different augmentations of the same image. This solution is inspired by contrastive instance learning [58] as we do not consider the codes as a target, but only enforce consistent mapping between views of the same image. Our method can be interpreted as a way of contrasting between multiple image views by comparing their cluster assignments instead of their features.
在对比学习中进行数据增强的方法,主要是对比特征的差异,本文的方法主要是比较多个图像的聚类分配而不是特征来对比多个图像的方法。
先对图像进行聚类,然后再对每个聚类簇进行对比学习
More precisely, we compute a code from an augmented version of the image and predict this code from other augmented versions of the same image. Given two image features \(\mathbf{z}_{t}\) and \(\mathbf{z}_{s}\) from two different augmentations of the same image, we compute their codes \(\mathbf{q}_{t}\) and \(\mathbf{q}_{s}\) by matching these
features to a set of \(K\) prototypes \(\left\{\mathbf{c}_{1}, \ldots, \mathbf{c}_{K}\right\}\). We then setup a "swapped" prediction problem with the following loss function:
where the function \(\ell(\mathbf{z}, \mathbf{q})\) measures the fit between features \(\mathbf{z}\) and a code \(\mathbf{q}\), as detailed later. Intuitively, our method compares the features \(\mathbf{z}_{t}\) and \(\mathbf{z}_{s}\) using the intermediate codes \(\mathbf{q}_{t}\) and \(\mathbf{q}_{s}\). If these two features capture the same information, it should be possible to predict the code from the other feature. A similar comparison appears in contrastive learning where features are compared directly [58]. In Fig. 1, we illustrate the relation between contrastive learning and our method.
两种方法
-
Online clustering
-
Multi-crop: Augmenting views with smaller images
感觉有点肝不动了,cv块的知识有点少。
直接看下这篇解析吧https://zhuanlan.zhihu.com/p/162707381
先看下效果