sentence-bert学习笔记
sentence-bert学习笔记
入职以来忙上加忙,少了很多看paper的时间,于是乎笔者决定,可以fellow一些写论文解析补充的文章,然后直接跑代码,看效果~
工程上的东西不能落下,前沿的东西也不能落下,感觉笔者此处有那么一丢丢的对抗网络的感觉了有木有。
本文可以说是一篇摘抄笔记
参考刘聪nlp
一个没啥废话的知乎博主
Bert模型已经在NLP各大任务中都展现出了强者的姿态。在语义相似度计算(semantic textual similarity)任务上也不例外,但是,由于bert模型规定,在计算语义相似度时,需要将两个句子同时进入模型,进行信息交互,这造成大量的计算开销。例如,有10000个句子,我们想要找出最相似的句子对,需要计算(10000*9999/2)次,需要大约65个小时。Bert模型的构造使得它既不适合语义相似度搜索,也不适合非监督任务,比如聚类。刘聪nlp
在实际应用中,例如:在问答系统任务中,往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。如果使用bert模型,那么每一次一个用户问题过来,都需要与标准问库计算一遍。在实时交互的系统中,是不可能上线的。
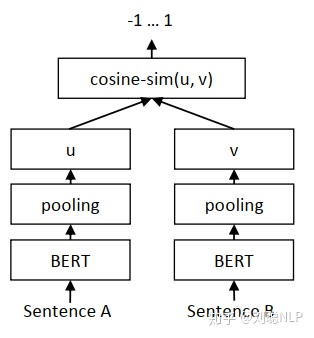
Sentence-BERT网络结构来解决bert模型的不足。简单通俗地讲,就是借鉴孪生网络模型的框架,将不同的句子输入到两个bert模型中(但这两个bert模型是参数共享的,也可以理解为是同一个bert模型),获取到每个句子的句子表征向量;而最终获得的句子表征向量,可以用于语义相似度计算,也可以用于无监督的聚类任务。对于同样的10000个句子,我们想要找出最相似的句子对,只需要计算10000次,需要大约5秒就可计算完全。
[孪生网络可以参考这篇](http://www.cs.utoronto .ca/~hinton/csc2535_06/readings/chopra-05.pdf)
孪生网络一开始提出是在图像识别领域(例如人脸识别),来求解两张图片(两张人脸图像)相似度,判断两张图片是否相似。如下图所示1,输入两张图片,将两张图片经过同一个卷积神经网络,得到每张图片的向量表示,最后求解两个向量的编辑距离(可以是余弦距离,欧式距离,等等),根据得到的编辑距离判断两张图片是否相似。
Sentence-BERT主要从以下三个方面进行改进的
- CLS向量
CLS向量策略,就是将bert模型中,开始标记【cls】向量,作为整句话的句向量。
这个和bert中的CLS是一致的,作为每句分类的标记
- 平均池化
平均池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求均值操作,最终将均值向量作为整句话的句向量。
- 最大值池化
最大值池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求最大值操作,最终将最大值向量作为整句话的句向量。
两个池化操作感觉并不是创新点
并且作者在对bert模型进行微调时,设置了三个目标函数,用于不同任务的训练优化;
-
Classification Objective Function
-
Regression Objective Function
计算两句话的余弦相似度
-
Triplet Objective Function
这个是常用的对比学习中的损失函数,巧妙的融入了对比学习,有内味了
在这个目标函数下,将模型框架进行修改,将原来的两个输入,变成三个句子输入。给定一个针定 句 \(a\), 一个肯定句 \(p\) 和一个否定句 \(n\), 模型通过使 \(a\) 与 \(p\) 的距离小于 \(a\) 与 \(n\) 的距离,来优化 模型。使其目标函数o最小,即
\(\mathbf{o}=\max \left(\left\|s_{a}-s_{p}\right\|-\left\|s_{a}-s_{n}\right\|+\epsilon, 0\right)\)
其中, \(s_{a}, s_{p}\) 和 \(s_{n}\) 表示句子 \(a, p\) 和 \(n\) 的向量, \(\|\cdot\|\) 表示距离度量, \(\epsilon\) 表示边距。在论文中, 距离度量为欧式距离,边距大小为1。
这个可以与unlim进行比较了,unlim既包含生成又包含分类,但是最终的损失函数只有一个,而sentence-bert是三个
stentence-bert网络结构利用孪生网络和三胞胎网络结构生成具有语义意义的句子embedding向量,语义相近的句子其embedding向量距离就比较近,从而可以用来进行相似度计算(余弦相似度、曼哈顿距离、欧式距离)。该网络结构在查找最相似的句子对,从上述的65小时大幅降低到5秒(计算余弦相似度大概0.01s),精度能够依然保持不变。这样SBERT可以完成某些新的特定任务,例如相似度对比、聚类、基于语义的信息检索。
作者也开源了,笔者要拿来试试
代码地址:https://github.com/UKPLab/sentence-transformers
