hive笔记
hive笔记
动态分区和静态分区的区别
静态分区SP(static partition)
动态分区DP(dynamic partition)
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。详细来说,静态分区的列实在编译时期,通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
配置环境
SET hive.exec.compress.intermediate = TRUE; --设置启用压缩
SET mapreduce.job.queuename=root.tdata.data-mining;--设置队列的优先级
SET hive.merge.mapredfiles = TRUE;--合并小文件
SET hive.map.aggr=TRUE; --提高聚合性能
SET hive.groupby.skewindata=TRUE;--有数据倾斜的时候进行负载均衡
SET hive.merge.size.per.task = 256000000; --合并后每个文件的大小
SET hive.merge.smallfiles.avgsize=64000000; --当输出文件的平均大小小于64M时,启动一个独立的map-reduce任务进行文件merge
SET hive.warehouse.subdir.inherit.perms=FALSE; --hive权限问题
SET hive.exec.dynamic.partition=TRUE; --开启动态分区
SET hive.exec.dynamic.partition.mode=nonstrict; -- 可以执行动态和静态分区
SET hive.exec.max.dynamic.partitions.pernode=600000; --动态分区属性:每个mapper或reducer可以创建的最大动态分区个数
SET hive.exec.max.dynamic.partitions=6000000; --动态分区属性:一个动态分区创建语句可以创建的最大动态分区个数
SET hive.exec.max.created.files=6000000;--动态分区属性:全局可以创建的最大文件个数
insert overwrite
是删除原有数据然后在新增数据,如果有分区那么只会删除指定分区数据,其他分区数据不受影响。
join
hive中的几个join
inner join
内关联([inner] join):只返回关联上的结果,可以理解为取并集
举个栗子
这个例子参考:cnblogs
hive> select * from rdb_a;
OK
1 lucy
2 jack
3 tony
hive> select * from rdb_b;
OK
1 12
2 22
4 32
inner join 可以理解为两个集合取交集,不保留不其他项
select a.id,a.name,b.age from rdb_a a inner join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 2 seconds 560 msec
OK
1 lucy 12
2 jack 22
Time taken: 47.419 seconds, Fetched: 2 row(s)
left [outer] join
左关联(left [outer] join):以左表为主,保留左边的表格都存在的,右表中没有的通通为null
select a.id,a.name,b.age from rdb_a a left join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 1 seconds 240 msec
OK
1 lucy 12
2 jack 22
3 tony NULL
Time taken: 33.42 seconds, Fetched: 3 row(s)
right [outer] join
右关联(right [outer] join):以右表为主,与左链接正相反,右表中没有字段,都补null
full [outer] join
全关联(full [outer] join):以两个表的记录为基准,返回两个表的记录去重之和,关联不上的字段为NULL。可以理解为去并集。
select a.id,a.name,b.age from rdb_a a full join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 5 seconds 540 msec
OK
1 lucy 12
2 jack 22
3 tony NULL
NULL NULL 32
Time taken: 42.938 seconds, Fetched: 4 row(s)
还有笛卡尔积链接,剩余的操作请参考cnblogs
博主写的例子通俗易懂。我直接🐎了
concat链接操作
CONCAT()函数用于将多个字符串连接成一个字符串。
使用数据表Info作为示例,其中SELECT id,name FROM info LIMIT 1;的返回结果为
使用示例:
SELECT CONCAT(id, ‘,’, name) AS con FROM info LIMIT 1;返回结果为
+----------+
| con |
+----------+
| 1,BioCyc |
+----------+
语法及使用特点:
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。可以有一个或多个参数。
CONCAT_WS函数
如何指定参数之间的分隔符
使用函数CONCAT_WS()。使用语法为:CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
```r
如SELECT CONCAT_WS('_',id,name) AS con_ws FROM info LIMIT 1;返回结果为
+----------+
| con_ws |
+----------+
| 1_BioCyc |
+----------+
Hive中collect相关的函数有collect_list和collect_set。
它们都是将分组中的某列转为一个数组返回,不同的是collect_list不去重而collect_set去重。
### GROUP_CONCAT()函数
GROUP_CONCAT函数返回一个字符串结果,该结果由分组中的值连接组合而成。
使用表info作为示例,其中语句SELECT locus,id,journal FROM info WHERE locus IN('AB086827','AF040764');的返回结果为
collect_set
具体的例子可以参考cnblogs
CONCAT_WS(SEPARATOR ,collect_set(column))
等价于===>GROUP_CONCAT()函数
在我们公司cnblogs](https://www.cnblogs.com/cc11001100/p/9043946.html)的hive(华为集群FunctionInsight)因为hive版本问题,并没有GROUP_CONCAT函数。只能用concat_ws和collect_set函数代替
但是排序性丧失。
partition by
创建分区的操作
1)创建表(DDL操作)
建表语法如下所示:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] ----指定表的名称和表的具体列信息。
[COMMENT table_comment] ---表的描述信息。
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] ---表的分区信息。
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] ---表的桶信息。
[ROW FORMAT row_format] ---表的数据分割信息,格式化信息。
[STORED AS file_format] ---表数据的存储序列化信息。
[LOCATION hdfs_path] ---数据存储的文件夹地址信息。
创建数据表解释说明:
1、 CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。hive中的表可以分为内部表(托管表)和外部表,区别在于,外部表的数据不是有hive进行管理的,也就是说当删除外部表的时候,外部表的数据不会从hdfs中删除。而内部表是由hive进行管理的,在删除表的时候,数据也会删除。一般情况下,我们在创建外部表的时候会将表数据的存储路径定义在hive的数据仓库路径之外。hive创建表主要有三种方式,第一种直接使用create table命令,第二种使用create table ... as select...(会产生数据)。第三种使用create table tablename like exist_tablename命令。
2、 EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、 LIKE 允许用户复制现有的表结构,但是不复制数据。
4、 ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive通过 SerDe 确定表的具体的列的数据。
5、 STORED AS
SEQUENCEFILE | TEXTFILE | RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用STORED AS SEQUENCEFILE。
6、CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
7、create table命令介绍2
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name] table_name LIKE existing_table_orview_name ---指定要创建的表和已经存在的表或者视图的名称。
[LOCATION hdfs_path] ---数据文件存储的hdfs文件地址信息。
8、CREATE [EXTERNAL] TABLE [IF NOT EXISTS]
[db_Name] table_name ---指定要创建的表名称
...指定partition&bucket等信息,指定数据分割符号。
[AS select_statement] ---导入的数据
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS SEQUENCEFILE;
hive中存储数据
Hive的数据存储一脸懵逼学hive
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
(1):db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
(2):table:在hdfs中表现所属db目录下一个文件夹
(3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
(4): partition:在hdfs中表现为table目录下的子目录
(5):bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
窗口函数
窗口函数是一个非常重要的函数,还是得好好的理解一下
参考猴子数据分析
窗口函数有什么用?
在日常工作中,经常会遇到需要在每组内排名,比如下面的业务需求:
排名问题:每个部门按业绩来排名
topN问题:找出每个部门排名前N的员工进行奖励
面对这类需求,就需要使用sql的高级功能窗口函数了。
什么是窗口函数?
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
那么语法中的<窗口函数>都有哪些呢?
<窗口函数>的位置,可以放以下两种函数:
-
专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
-
聚合函数,如sum. avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
insert into table 与 insert overwrite table 区别
也就是into和overwrite的区别
也就是说 overwrite会覆盖现有的数据,而into是直接将数据写入库。
如果需要的是去重的数据,那么应该选择overwrite作为插入的方式。
insert into 与 insert overwrite 都可以向hive表中插入数据,但是insert into直接追加到表中数据的尾部,而insert overwrite会重写数据,既先进行删除,再写入。如果存在分区的情况,insert overwrite会只重写当前分区数据。
REGEXP_REPLACE
这个sql中的函数可以等价于python中的replace
hive中传入参数
这里重点介绍-e,-f,–hiveconf,–hivevar这四个的用法
都是啥意思呢
hive -e
用于执行查询类的语句,-e 后的后就是代码
hive -e "SELECT * FROM MYTABLE LIMIT 10"
hive -e "SELECT * FROM MYTABLE LIMIT 10" > /tmp/mytable/data.csv
hive -f
用于执行sql文件
hive -f data.hql
传递参数
这里介绍两种方法:hiveconf 和 hivevar,hiveconf属于hive-site.xml下面配置的环境变量,hivevar为临时变量。在运行时hiveconf必须带上命名空间,如\({hiveconf:key},hivevar直接使用\){key}即可。
hiveconf 案例介绍
hive --hiveconf pt_dt=2018-07-25 -e "SELECT * FROM MYTABLE WHERE pt_dt = "${hiveconf:pt_dt}" LIMIT 10" > /tmp/mytable/data.csv
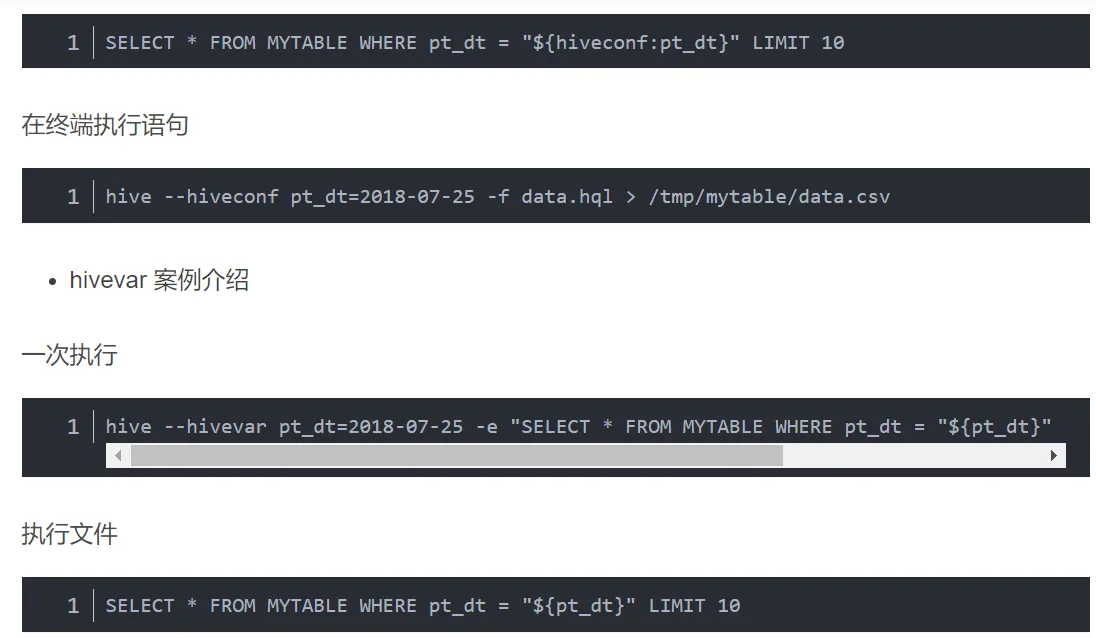
一次执行代码
