xgb小结
感觉这里还是应该好好弄弄,真正的理解才能更好的使用,学长说xgb的论坛要更火爆一些,一般提了bug会有很多的大佬回复,但是lgb,哈哈,没人回复。。
比谁好用,那就比谁的论坛更加火爆,来啊,比 啊,xgb秒杀全场啊~
树的复杂度可以用如树的深度,内部节点个数,叶节点个数等 来衡量。** XGBoost中正则项用来衡量树的复杂度:树的叶子节点个数T和每棵树的叶子节点输出分数W的平方和(相当于L2正则化):**
\(\Omega\left(f_{t}\right)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}\)
目标函数化简:
\[O b j^{(t)}=\underbrace{\sum_{i=1}^{N}\left(g_{i} f_{t}\left(\mathbf{x}_{\mathbf{i}}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(\mathbf{x}_{\mathbf{i}}\right)\right)}_{\text {对样本累加 }}+\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}
\]
上式中第一部分是对样本的累加,而后面的部分是正则项,是对叶子节点的累加。
因此目标函数就是两部分的累加和样本的累加和以及叶子节点的累加和。。
定义q函数将输入x映射到某个叶子节点上(就是输入一个样本然后告诉你样本在哪个节点上,\(q_x{i}就是第i个样本所对应的叶子节点\)),则有:
\[f_{t}(x)=w_{q(x)}, \quad w \in \mathbf{R}^{T}, q: \mathbf{R}^{d} \rightarrow\{1,2, \cdots, T\}
\]
有了每个样本在叶子节点上面的表示,因此可以把样本累加变为叶子节点的累加,也就是下面的公式

计算增益的方法
选择增益最大的。类似于在ID3中的信息增益,和CART树中的 基尼指数,那XGBoost中怎么计算增益呢?损失函数是:
\[O b j^{(t)}=-\frac{1}{2} \sum_{j=1}^{T}\left(\frac{G_{j}^{2}}{H_{j}+\lambda}\right)+\gamma T
\]
其中红色部分衡量了叶子节点对总体损失的贡献,目标函数越 小越好,则红色部分就越大越好,在XGBoost中增益计算方法是:
Gain值越大,说明分裂后能使目标函数减小的越多,也就是越 好
xgb如何进行节点的分裂
换句话说,什么情况下节点才分裂
就像CART树一样,校举所有曾特征和特征值,计算树的分裂方
It :
\[\begin{array}{l}\text { Algorithm 1: Exact Greedy Algorithm for Split Finding } \\ \text { Input: } I, \text { instance set of current node } \\ \text { Input: } d \text { , feature dimension } \\ \text { gain } \leftarrow 0 \\ G \leftarrow \sum_{i \in I} g_{i}, H \leftarrow \sum_{i \in I} h_{i}\end{array}
\]
\[\begin{array}{l}
\text { for } k=1 \text { to } m \text { do } \\
\qquad \begin{array}{l}
G_{L} \leftarrow 0, H_{L} \leftarrow 0 \\
\text { for } j \text { in sorted }\left(I, b y \mathbf{x}_{j k}\right) \text { do } \\
\quad \mid \quad G_{L} \leftarrow G_{L}+g_{j}, H_{L} \leftarrow H_{L}+h_{j} \\
G_{R} \leftarrow G-G_{L}, H_{R} \leftarrow H-H_{L} \\
\quad \text { score } \leftarrow \max \left(\text { score, } \frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}-\frac{G^{2}}{H+\lambda}\right) \\
\text { end }
\end{array}
\end{array}
\]
Split with max score
计算树的复杂度
假设枚举年龄特征xj,考虑划分点a,计算枚举xj<a 和 a\leqxj的 导数和 :
对于一个特征,对特征取值排完序后,枚举所有的分裂点a,只 要从左到右扫描就可以枚举出所有分割的梯度GL和GR,计算增 益。假设树的高度为H,特征数d,则复杂度为 O(Hdnlogn) 其中,排序为O(nlogn),每个特征都要排序乘以d,每一层都要 这幸一遍,所以乘以高度H。
近似算法
当数据量庞大,无法全部存入内存中时,精确算法很慢,央此弓|入 近似算法。 根据特征k的分布确定 l个候选切分 点 \(S_{k}=\left\{s_{k 1}, s_{k 2}, \cdots s_{k l}\right\}\) 然后根据候选切分点把相应的样本放入对应的桶中,对每个桶的G, H进行累加, 在候选切分点集合上进行精确今心杏找。算法描述如
Algorithm 2: Approximate Algorithm for Split Finding
for \(k=1\) to \(m\) do
\[\begin{array}{l}\text { Propose } S_{k}=\left\{s_{k 1}, s_{k 2}, \cdots s_{k l}\right\} \text { by percentiles on feature } k \\ \text { Proposal can be done per tree (global), or per split(local). }\end{array}
\]
end for \(k=1\) to \(m\) do
\[\begin{aligned} G_{k v} & \leftarrow=\sum_{j \in\left\{j \mid s_{k, v} \geq \mathbf{x}_{j k}>s_{k, v-1}\right\}} g_{j} \\ H_{k v} & \leftarrow=\sum_{j \in\left\{j \mid s_{k, v} \geq \mathbf{x}_{j k}>s_{k, v-1}\right\}} h_{j} \end{aligned}
\]
end Follow same step as in previous section to find max score only among proposed splits.
根据分位数给出对应的候选切分点,分桶。
xgb缺失值处理
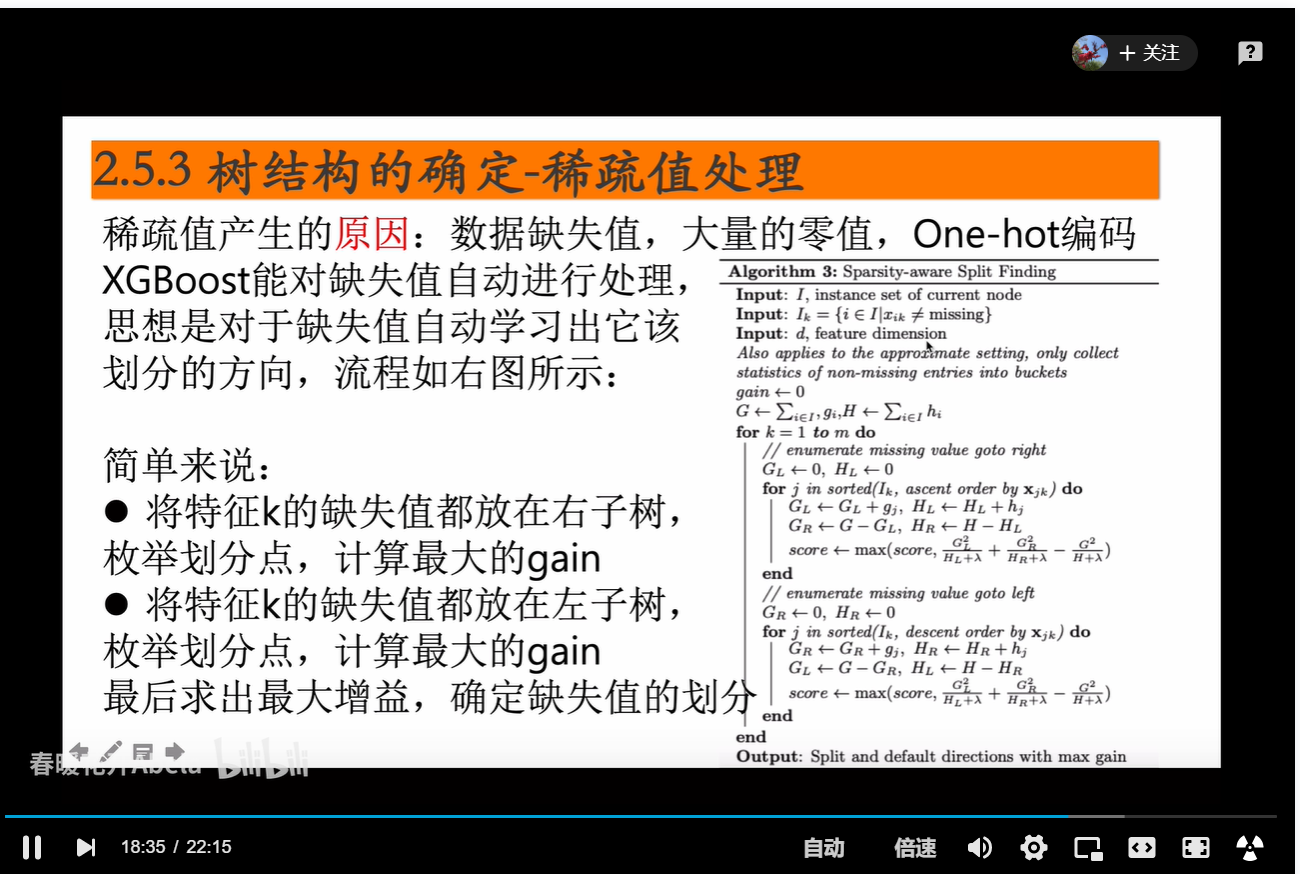
继承了rf的两个采样

优化的方法

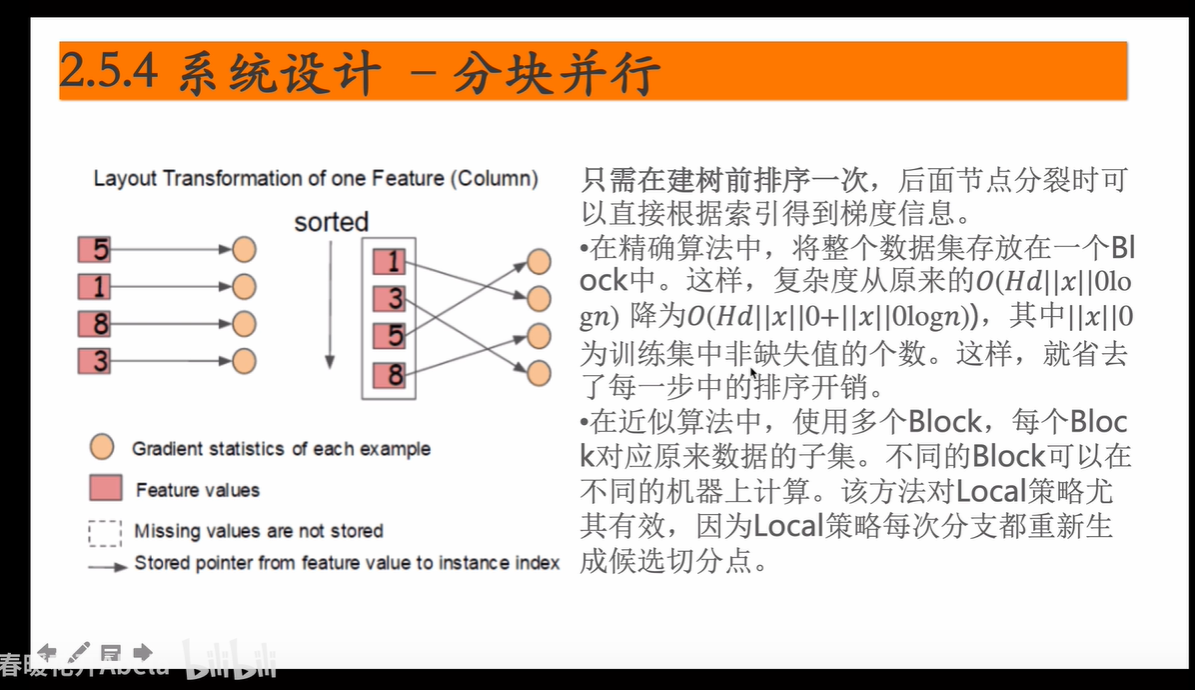
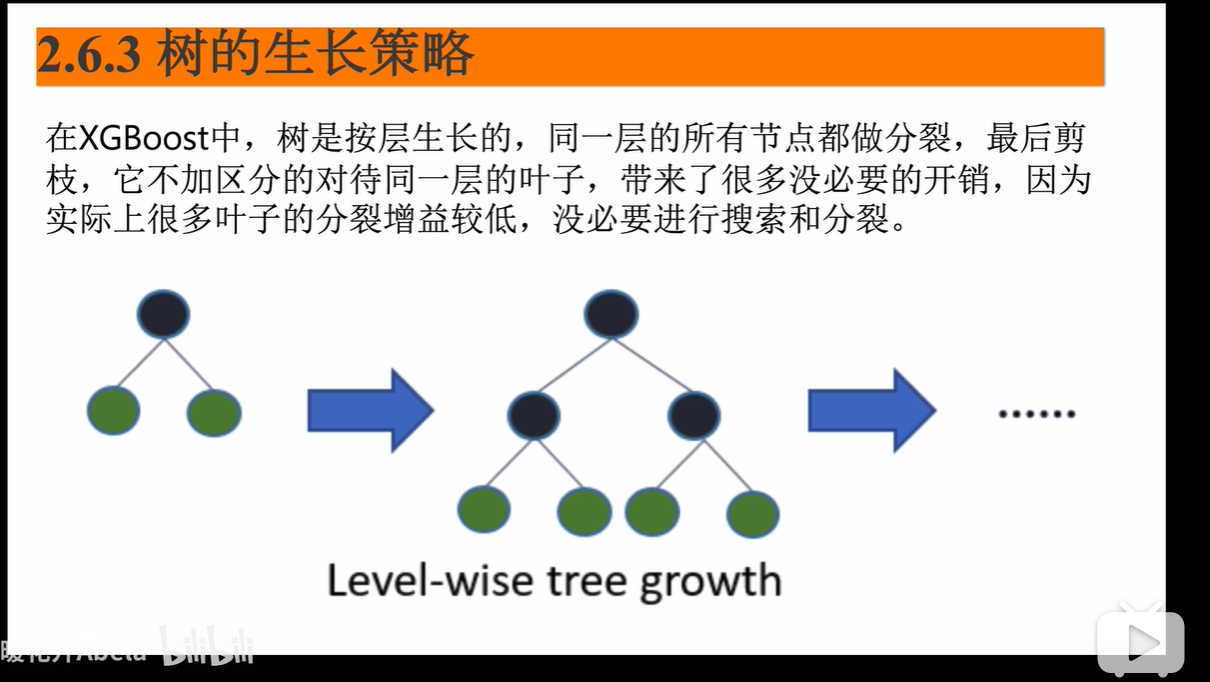
xgb的树的生长策略
是level wise的,因此每层的树会非常的饱满,多线程的一个并行化,因为很多的无用开销,因此效率有时候不高
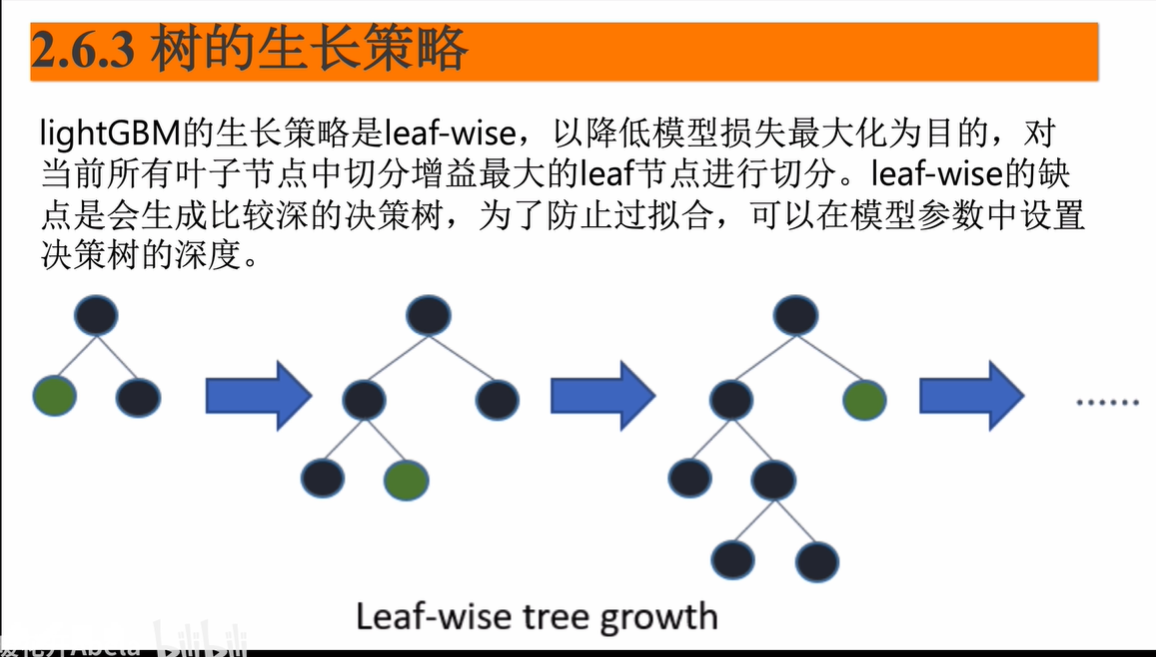
lightGBM的生长策略
leaf wise的,对所有叶子损失降低最大的进行分割,想防止过拟合就要限制树的生长的
lightGBM的并行策略

提高训练速度

提高训练精度

防止过拟合的方式

catboost
待补充
