特征工程
特征工程
- select_dtypes
可以选择指定类型的数据
# Create subset of only the numeric columns
so_numeric_df = so_survey_df.select_dtypes(include=['int', 'float'])
处理分类特征
- pd.get_dummies()
- values_counts()
统计每个特征的不相同的样本个数(之和)
datacamp的栗子
# Create a series out of the Country column
countries = so_survey_df['Country']
# Get the counts of each category
country_counts = countries.value_counts()
# Print the count values for each category
print(country_counts)
<script.py> output:
South Africa 166
USA 164
Spain 134
Sweeden 119
France 115
Russia 97
UK 95
India 95
Ukraine 9
Ireland 5
Name: Country, dtype: int64
- isin()
结果返回一个bool型的mask
接受一个列表,判断该列中元素是否在列表中
# Create a series out of the Country column
countries = so_survey_df['Country']
# Get the counts of each category
country_counts = countries.value_counts()
# Create a mask for only categories that occur less than 10 times
mask = countries.isin(country_counts[country_counts < 10].index)
# Print the top 5 rows in the mask series
print(mask.head())
<script.py> output:
0 False
1 False
2 False
3 False
4 False
Name: Country, dtype: bool
- 创建一个mask筛选出我们不需要的类别
比如datacamp的栗子
可以把创建出来的
# Create a series out of the Country column
countries = so_survey_df['Country']
# Get the counts of each category
country_counts = countries.value_counts()
# Create a mask for only categories that occur less than 10 times
mask = countries.isin(country_counts[country_counts < 10].index)
# Label all other categories as Other
countries[mask] = 'Other'
# Print the updated category counts
print(pd.value_counts(countries))
<script.py> output:
South Africa 166
USA 164
Spain 134
Sweeden 119
France 115
Russia 97
UK 95
India 95
Other 14
Name: Country, dtype: int64
处理数值特征
Numeric variables
binning Numeric variables二进制数值变量
- pd.['列名']=vaule
创建一个新列 - 可以筛选一些特征,但是我总是想不到简单的写法,应该还是基础不太牢固
- pandas.cut
用来把一组数据分割成离散的区间。比如有一组年龄数据,可以使用pandas.cut将年龄数据分割成不同的年龄段并打上标签cnblog
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise')
- x:被切分的类数组(array-like)数据,必须是1维的(不能用DataFrame);cnblog
- bins:bins是被切割后的区间(或者叫“桶”、“箱”、“面元”),有3中形式:一个int型的标量、标量序列(数组)或者pandas.IntervalIndex 。
- 一个int型的标量
- 当bins为一个int型的标量时,代表将x平分成bins份。x的范围在每侧扩展0.1%,以包括x的最大值和最小值。
- 标量序列:标量序列定义了被分割后每一个bin的区间边缘,此时x没有扩展。
- pandas.IntervalIndex:定义要使用的精确区间。
- right:bool型参数,默认为True,表示是否包含区间右部。比如如果bins=[1,2,3],right=True,则区间为(1,2],(2,3];right=False,则区间为(1,2),(2,3)。
- labels:给分割后的bins打标签,比如把年龄x分割成年龄段bins后,可以给年龄段打上诸如青年、中年的标签。labels的长度必须和划分后的区间长度相等,比如bins=[1,2,3],划分后有2个区间(1,2],(2,3],则labels的长度必须为2。如果指定labels=False,则返回x中的数据在第几个bin中(从0开始)。
- retbins:bool型的参数,表示是否将分割后的bins返回,当bins为一个int型的标量时比较有用,这样可以得到划分后的区间,默认为False。
- precision:保留区间小数点的位数,默认为3.
- include_lowest:bool型的参数,表示区间的左边是开还是闭的,默认为false,也就是不包含区间左部(闭)。
- duplicates:是否允许重复区间。有两种选择:raise:不允许,drop:允许。
这个datacamp的栗子可以划分不同的区间,完事儿给不同的列贴labels,不过要注意labels的取值
# Import numpy
import numpy as np
# Specify the boundaries of the bins
bins = [-np.inf, 10000, 50000, 100000, 150000, np.inf]
# Bin labels
labels = ['Very low', 'Low', 'Medium', 'High', 'Very high']
# Bin the continuous variable ConvertedSalary using these boundaries
so_survey_df['boundary_binned'] = pd.cut(so_survey_df['ConvertedSalary'],
bins, labels=labels)
# Print the first 5 rows of the boundary_binned column
print(so_survey_df[['boundary_binned', 'ConvertedSalary']].head())
<script.py> output:
boundary_binned ConvertedSalary
0 Very low 0.0
1 Medium 70841.0
2 Very low 0.0
3 Low 21426.0
4 Low 41671.0
缺失值的处理
我先补充一个小的知识点,就是我突然发现so_survey_df[['Gender']].info()==so_survey_df.loc['Gender'],[[]]的奇效,哈哈哈哈
- info()特征的非缺失值等信息
- isna()查看缺失值信息
- notnull()查看非缺失值的信息
- dropna() 删除缺失值,其中有一个subset argument,可以指定删除某一列的缺失值
- filna() 可以使用指定字符串填充缺失值:so_survey_df['Gender'].fillna('Not Given', inplace=True)
- round() 方法返回浮点数x的四舍五入值。
在删除缺失值的时候是不能删除训练集里面的缺失值的
特殊符号的处理
- replace()
替换
# Remove the commas in the column
# 这里注意要先变为字符串型
so_survey_df['RawSalary'] = so_survey_df['RawSalary'].str.replace(',', '')
so_survey_df['RawSalary'] = so_survey_df['RawSalary'].str.replace('$','')
-
pd.to_numeric()
可以直接转化为数值型
numeric_vals = pd.to_numeric(so_survey_df['RawSalary'], errors='coerce') -
astype('类型')
强制类型转化
一般展示输出结果的时候,都会看到dtype的类型
可以同时替换多个值
# Use method chaining
so_survey_df['RawSalary'] = so_survey_df['RawSalary']\
.str.replace(',', '')\
.str.replace('$', '')\
.str.replace('£', '')\
.astype('float')
# Print the RawSalary column
print(so_survey_df['RawSalary'])
np.clip()
也就是说clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min。
这个也就是学长说的,当遇到情感分为1或者0 的时候,需要替换掉0和1.那就可以把结果限制在(0.0001,0.9999),这样可以防止在计算损失函数logloss的时候inf的出现,也算是一个近似求解,这里我先整理一下
x=np.array([[1,2,3,5,6,7,8,9],[1,2,3,5,6,7,8,9]])
np.clip(x,3,8)
Out[90]:
array([[3, 3, 3, 5, 6, 7, 8, 8],
[3, 3, 3, 5, 6, 7, 8, 8]])
数据分布
探索性数据分析(EDA)
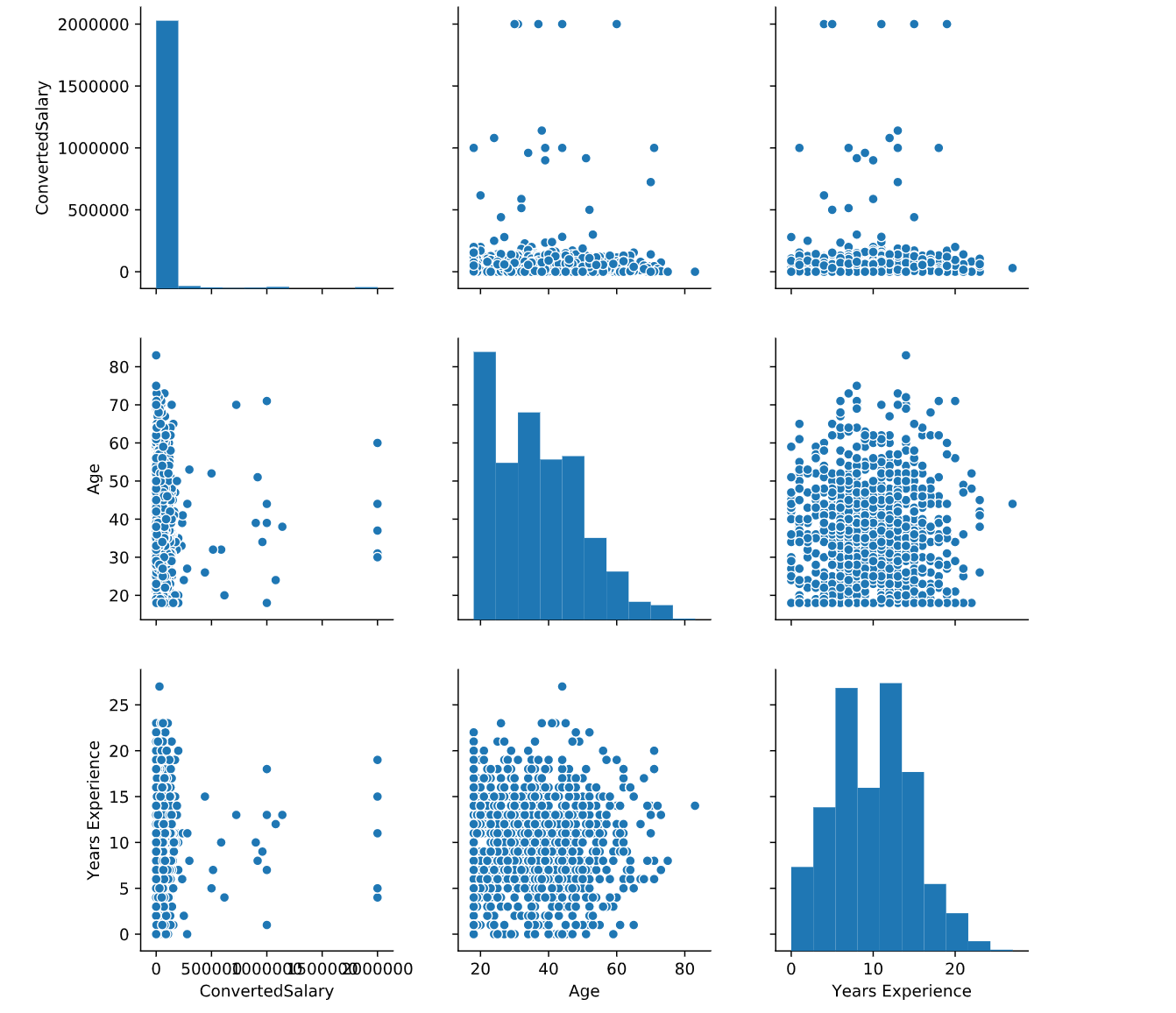
一旦你有了一个很好的被清理过的数据集,下一步就是探索性数据分析(EDA)。EDA是确定数据可以告诉我们的过程,我们使用EDA来查找模式、关系或异常情况,以便指导我们后续的工作。然而在EDA中有很多的方法,但最有效的工具之一是对图(也称为散点图矩阵)。散点图矩阵让我们看到了两个变量之间的关系。阿里云云栖号散点图矩阵建立在两个基本图形上,直方图和散点图。对角线上的直方图允许我们看到单个变量的分布,而上下三角形上的散点图显示了两个变量之间的关系,啊啊啊啊,python好神奇的一行代码搞定了
查看数据的分布可以使用可视化进行展示
可以使用
- hist() 查看数据分布
- boxplot() 可以查看方差的分布,之前还说不会这个,哈哈哈,还是看的太少知乎箱线图的解释
- seaborn()的pairplot(),hue参数可以指定特征进行上色
- describe()可以直接计算描述统计信息
# Import packages
import matplotlib.pyplot as plt
import seaborn as sns
# Plot pairwise relationships
sns.pairplot(so_numeric_df)
# Show plot
plt.show()
print(so_numeric_df.describe())
<script.py> output:
ConvertedSalary Age Years Experience
count 9.990000e+02 999.000000 999.000000
mean 6.161746e+04 36.003003 9.961962
std 1.760924e+05 13.255127 4.878129
min 0.000000e+00 18.000000 0.000000
25% 0.000000e+00 25.000000 7.000000
50% 2.712000e+04 35.000000 10.000000
75% 7.000000e+04 45.000000 13.000000
max 2.000000e+06 83.000000 27.000000
** As decision trees split along a singular point, they do not require all the columns to be on the same scale.**
归一化处理这里,缺失在做树模型的时候是不需要的,这个要记得
标准化转化处理
Normalization scales all points linearly between the upper and lower bound
- MinMaxScaler 最值标准化处理
- StandardScaler 均值标准化
- PowerTransformer 取log对数标准化
处理离群值
quantile:分位数
deviation:偏差
- quantile(0.95) 分位数函数
- 避免数据流失
文本特征处理
个人感觉这里还是晕乎乎的,额居然还不知道哪里晕乎乎的
- 正则表达式
- len()可以统计字符串中字符的长度
- split()分割
# Replace all non letter characters with a whitespace
#用空格代替所有非字母的字符
speech_df['text_clean'] = speech_df['text'].str.replace('[^a-zA-Z]', ' ')
# Change to lower case
speech_df['text_clean'] = speech_df['text_clean'].str.lower()
# Print the first 5 rows of the text_clean column
print(speech_df['text_clean'].head())
额,我总是会忘记只有字符串才会有统计长度和进行划分的方法
# Find the length of each text
speech_df['char_cnt'] = speech_df['text_clean'].str.len()
# Count the number of words in each text
speech_df['word_cnt'] = speech_df['text_clean'].str.split().str.len()
# Find the average length of word
speech_df['avg_word_length'] = speech_df['char_cnt'] / speech_df['word_cnt']
# Print the first 5 rows of these columns
print(speech_df[['text_clean', 'char_cnt', 'word_cnt', 'avg_word_length']])
<script.py> output:
text_clean char_cnt word_cnt avg_word_length
0 fellow citizens of the senate and of the house... 8616 1432 6.016760
1 fellow citizens i am again called upon by th... 787 135 5.829630
2 when it was first perceived in early times t... 13871 2323 5.971158
3 friends and fellow citizens called upon to u... 10144 1736 5.843318
4 proceeding fellow citizens to that qualifica... 12902 2169 5.948363
5 unwilling to depart from examples of the most ... 7003 1179 5.939779
6 about to add the solemnity of an oath to the o... 7148 1211 5.902560
7 i should be destitute of feeling if i was not ... 19894 3382 5.882318
8 fellow citizens i shall not attempt to descr... 26322 4466 5.893865
9 in compliance with an usage coeval with the ex... 17753 2922 6.075633
10 fellow citizens about to undertake the arduo... 6818 1130 6.033628
11 fellow citizens the will of the american peo... 7061 1179 5.988974
12 fellow citizens the practice of all my predec... 23527 3912 6.014059
13 called from a retirement which i had supposed ... 32706 5585 5.856043
14 fellow citizens without solicitation on my p... 28739 4821 5.961211
15 elected by the american people to the highest ... 6599 1092 6.043040
16 my countrymen it a relief to feel that no he... 20089 3348 6.000299
17 fellow citizens i appear before you this day... 16820 2839 5.924621
18 fellow citizens of the united states in comp... 21032 3642 5.774849
19 fellow countrymen at this second appearing... 3934 706 5.572238
20 citizens of the united states your suffrages... 6521 1138 5.730228
21 fellow citizens under providence i have been... 7736 1342 5.764531
22 fellow citizens we have assembled to repeat ... 14969 2498 5.992394
23 fellow citizens we stand to day upon an emin... 17774 2990 5.944482
24 fellow citizens in the presence of this vast... 10155 1695 5.991150
25 fellow citizens there is no constitutional o... 26175 4399 5.950216
26 my fellow citizens in obedience of the manda... 12340 2028 6.084813
27 fellow citizens in obedience to the will of ... 23691 3980 5.952513
28 my fellow citizens when we assembled here on... 13426 2216 6.058664
29 my fellow citizens no people on earth have mo... 5565 991 5.615540
30 my fellow citizens anyone who has taken the ... 32160 5439 5.912852
31 there has been a change of government it bega... 9554 1712 5.580607
32 my fellow citizens the four years which have... 8402 1535 5.473616
33 my countrymen when one surveys the world abo... 20294 3348 6.061529
34 my countrymen no one can contemplate current... 23937 4055 5.903083
35 my countrymen this occasion is not alone the... 22961 3771 6.088836
36 i am certain that my fellow americans expect t... 10910 1888 5.778602
37 when four years ago we met to inaugurate a pre... 10629 1831 5.805025
38 on each national day of inauguration since ... 7674 1371 5.597374
39 mr chief justice mr vice president my frie... 3086 573 5.385689
40 mr vice president mr chief justice and fel... 13707 2292 5.980366
41 my friends before i begin the expression of t... 14003 2475 5.657778
42 the price of peace mr chairman mr vice pres... 9277 1688 5.495853
43 vice president johnson mr speaker mr chief... 7706 1390 5.543885
44 my fellow countrymen on this occasion the oa... 8242 1502 5.487350
45 senator dirksen mr chief justice mr vice p... 11701 2152 5.437268
46 mr vice president mr speaker mr chief jus... 10048 1835 5.475749
47 for myself and for our nation i want to thank... 6934 1238 5.600969
48 senator hatfield mr chief justice mr presi... 13787 2457 5.611315
49 senator mathias chief justice burger vice pr... 14601 2586 5.646172
50 mr chief justice mr president vice preside... 12536 2342 5.352690
51 my fellow citizens today we celebrate the myst... 9119 1608 5.671020
52 my fellow citizens at this last presidential i... 12374 2201 5.621990
53 president clinton distinguished guests and my... 9084 1606 5.656289
54 vice president cheney mr chief justice pres... 12199 2122 5.748822
55 my fellow citizens i stand here today humb... 13637 2452 5.561582
56 vice president biden mr chief justice membe... 12174 2151 5.659693
57 chief justice roberts president carter presi... 8555 1488 5.749328
Counting words
- CountVectorizer()
文本特征提取
本特征提取:
将文本数据转化成特征向量的过程
比较常用的文本特征表示法为词袋法
词袋法:
不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征
这些不重复的特征词汇集合为词表
每一个文本都可以在很长的词表上统计出一个很多列的特征向量
如果每个文本都出现的词汇,一般被标记为 停用词 不计入特征向量
主要有两个api来实现 CountVectorizer 和 TfidfVectorizer
-
CountVectorizer
会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获得所有文本的关键词,通过toarray()可看到词频矩阵的结果。
TfidfTransformer用于统计vectorizer中每个词语的TFIDF值。 -
TfidfVectorizer
将原始文档的集合转化为tf-idf特性的矩阵,相当于CountVectorizer配合TfidfTransformer使用的效果。
即TfidfVectorizer类将CountVectorizer和TfidfTransformer类封装在一起。卷心菜呀
相比之下,文本条目越多,Tfid的效果会越显著
-
get_feature_names()
获取特征名
input:string如果'filename',作为参数传递的顺序适合,预计将是需要读取以获取原始内容进行分析的文件名列表。
如果'file',序列项必须有一个'read'方法(类文件对象),被调用来获取内存中的字节。
否则,输入将被预期是顺序字符串或字节项预期直接分析。
encoding:string,'utf-8'。
如果要分配字节或文件,则使用该编码进行解码。
decode_error:{'strict','ignore','replace'}
如果给出分析字节序列包含不是给定编码的字符,该怎么做。默认情况下,它是'strict',这意味着将会引发一个UnicodeDecodeError。其他值是“忽略”和“替换”。
strip_accents:{'ascii','unicode',无}
在预处理步骤中删除口音。'ascii'是一种快速的方法,只适用于具有直接ASCII映射的字符。'unicode'是一种稍慢的方法,适用于任何字符。无(默认)不起作用。
analyzer:string,{'word','char'}或可调用
该功能是否应由字符或字符n-gram组成。
如果传递了一个可调用函数,它将用于从原始未处理的输入中提取特征序列。
预处理器:可调用或无(默认)
覆盖预处理(字符串转换)阶段,同时保留令牌化和n-gram生成步骤。
tokenizer:可调用或无(默认)
覆盖字符串标记化步骤,同时保留预处理和n-gram生成步骤。仅适用如果。analyzer == 'word'
ngram_range:tuple(min_n,max_n)
不同n值的n值范围的下边界和上边界被提取。将使用所有n值,使得min_n <= n <= max_n。
stop_words:string {'english'},list或None(默认)
如果是字符串,则将其传递给_check_stop_list,并返回相应的停止列表。'english'是目前唯一支持的字符串值。
如果一个列表,该列表被假定为包含停止词,所有这些都将从生成的令牌中删除。仅适用如果。analyzer == 'word'
如果没有,将不会使用停止的单词。max_df可以设置为[0.7,1.0]范围内的值,以根据术语的语料库文档频率自动检测和过滤停止词。
小写:布尔值,默认值为True
在标记化之前将所有字符转换为小写。
token_pattern:string
表示什么构成“令牌”的正则表达式,仅用于。默认正则表达式选择2个或更多字母数字字符的标记(标点符号被完全忽略,并始终作为令牌分隔符处理)。analyzer == 'word'
max_df:float in range [ 0.0,1.0 ]或int,default = 1.0
当构建词汇时,忽略文档频率严格高于给定阈值(语料库特定停止词)的术语。如果为float,则该参数代表一定比例的文档,整数绝对计数。如果词汇不是无,则忽略此参数。
min_df:float in range [ 0.0,1.0 ]或int,default = 1
当构建词汇时,忽略文档频率严格低于给定阈值的术语。这个值在文献中也被称为截止值。如果为float,则该参数代表一定比例的文档,整数绝对计数。如果词汇不是无,则忽略此参数。
max_features:int或None,default = None
如果不是无,建立一个词汇,只考虑由词汇频率排序的顶级max_feature。
如果词汇不是无,则忽略此参数。
词汇表:映射或迭代,可选
键是术语和值的映射(例如,dict)是特征矩阵中的索引,或者可迭代的术语。如果没有给出,则从输入文档确定词汇表。
binary:boolean,default = False
如果为True,则所有非零项计数都设置为1.这并不意味着输出将只有0/1值,只有tf-idf中的tf项是二进制的。(将idf归一化为False,得到0/1输出。)
dtype:type,可选
由fit_transform()或transform()返回的矩阵的类型。
规范:'l1','l2'或无,可选
用于规范化术语向量的规范。没有没有规范化。
use_idf:boolean,default = True
启用逆文档频率重新加权。
smooth_idf:boolean,default = True
通过将文档频率添加一个平滑的idf权重,就好像一个额外的文档被看到包含一个集合中的每个术语一次。防止零分。
sublinear_tf:boolean,default = False
应用子线性tf缩放,即用1 + log(tf)替换tf。
# Import CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# Specify arguements to limit the number of features generated
cv = CountVectorizer(min_df=0.2,max_df=0.8)
# Fit, transform, and convert into array
cv_transformed =cv.fit_transform(speech_df['text_clean'])
cv_array = cv_transformed.toarray()
# Print the array shape
print(cv_array.shape)
- add_prefix
给字符串增加前缀标签
pd.concat()
可以将数据根据不同的轴进行合并
- tf-idf
首先明确一点是相乘使用,越高,证明这个词在这篇文章中的重要性越高
定义
- 统计所有文章常见的词,比如“是 的 了。。”这样的词把它们过滤掉,tf可以统计这样的词
- 找出比较一般常见的词,IDF赋给它们较小的权重,它的大小与一个词常见的程度成反比
当有TF(词频)和IDF(逆文档频率)后,将这两个词相乘,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。zhihu
- TF:词频:某个词在文章中出现的次数
考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
TF:词频:某个词在文章中出现的次数/文章总次数,因此是一个权重
这时,需要一个语料库(corpus),用来模拟语言的使用环境
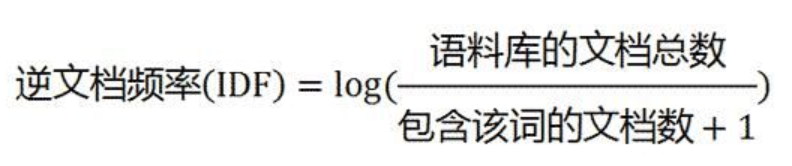
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
于是tf-idf=tfidf=词频逆文档频率
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
但是有时候用一个词频衡量文章中一个词的重要性不够全面,需要体现词上下文的结构。
后面可以继续了解word2vc
给出一个datacamp的小栗子
# Import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
# Instantiate TfidfVectorizer
tv = TfidfVectorizer(max_features=100, stop_words='english')
# Fit the vectroizer and transform the data
tv_transformed = tv.fit_transform(speech_df['text_clean'])
# Create a DataFrame with these features
tv_df = pd.DataFrame(tv_transformed.toarray(),
columns=tv.get_feature_names()).add_prefix('TFIDF_')
print(tv_df.head())
<script.py> output:
TFIDF_action TFIDF_administration TFIDF_america TFIDF_american TFIDF_americans ... TFIDF_war TFIDF_way TFIDF_work TFIDF_world TFIDF_years
0 0.000000 0.133415 0.000000 0.105388 0.0 ... 0.000000 0.060755 0.000000 0.045929 0.052694
1 0.000000 0.261016 0.266097 0.000000 0.0 ... 0.000000 0.000000 0.000000 0.000000 0.000000
2 0.000000 0.092436 0.157058 0.073018 0.0 ... 0.024339 0.000000 0.000000 0.063643 0.073018
3 0.000000 0.092693 0.000000 0.000000 0.0 ... 0.036610 0.000000 0.039277 0.095729 0.000000
4 0.041334 0.039761 0.000000 0.031408 0.0 ... 0.094225 0.000000 0.000000 0.054752 0.062817
[5 rows x 100 columns]
然后打印出tf-idf
# Isolate the row to be examined
sample_row = tv_df.iloc[0]
# Print the top 5 words of the sorted output
print(sample_row.sort_values(ascending=False).head())
<script.py> output:
TFIDF_government 0.367430
TFIDF_public 0.333237
TFIDF_present 0.315182
TFIDF_duty 0.238637
TFIDF_citizens 0.229644
Name: 0, dtype: float64
- N-grams
参考cnblog先了解一下
大概的意思是指定拼接词,形成句子。
