

作业2:java爬虫
package test;
import java.io.*;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.Vector;
public class Test{
public static Vector<String> titles=new Vector<String>();//存放文章标题
public static Vector<String> t_contents=new Vector<String>();//存放文章内容
public static void getTitleAndUrl(String url) {
try {
Vector<String> t_urls=new Vector<String>();
Document doc = Jsoup.connect(url).get();
Elements links=doc.getElementsByClass("zx-tl");//由于每篇文章标题都是在类名为zx-tl的div块里面,Java可以直接用getElementsByClass,当然这里也可以用select来写,select("div.zx-tl")
Elements urls=links.select("a");//再缩短,标题和链接都在a标签里面
for (Element link : urls){
t_urls.add(link.attr("href"));//将每篇文章链接加入t_urls
titles.add(link.text());//将每篇文章标题加入titles
}
for(String t_url:t_urls) {
Document doc2=Jsoup.connect(t_url).get();
Elements contents=doc2.getElementsByClass("artical-content");
t_contents.add(contents.text());
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String arg[]) {
try {
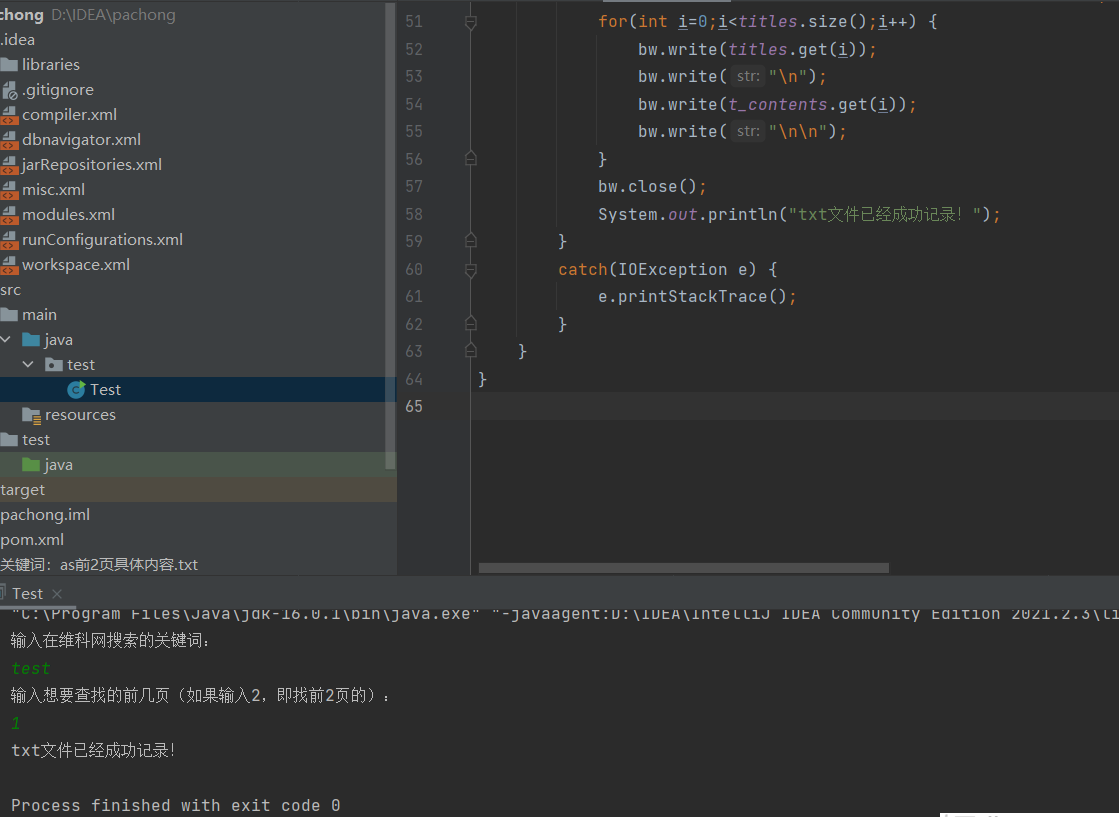
Scanner input=new Scanner(System.in);
System.out.println("输入在维科网搜索的关键词:");
String keyword=input.next();
System.out.println("输入想要查找的前几页(如果输入2,即找前2页的):");
String pagenumber=input.next();
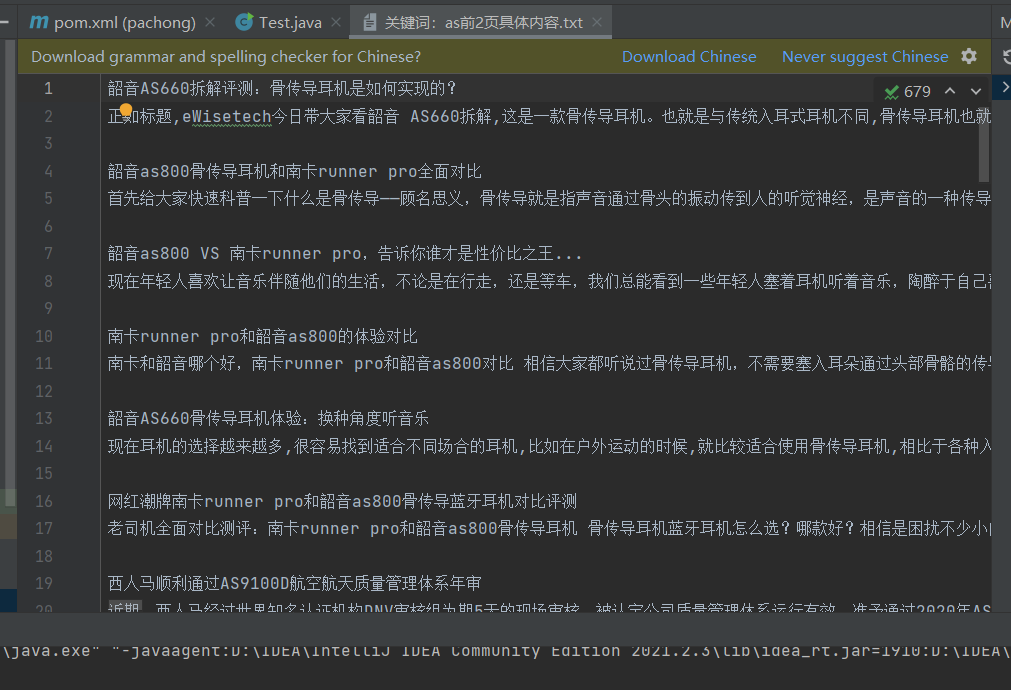
String txt_name="关键词:"+keyword+"前"+pagenumber+"页具体内容.txt";
File file=new File(txt_name);
int pagenum=Integer.parseInt(pagenumber);
for(int i=1;i<=pagenum;i++) {
String page=Integer.toString(i);
String url="http://www.ofweek.com/newquery.action?keywords="+keyword+"&type=1&pagenum="+page;
getTitleAndUrl(url);
}
if(!file.exists()){
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file.getAbsoluteFile());
BufferedWriter bw = new BufferedWriter(fileWriter);
for(int i=0;i<titles.size();i++) {
bw.write(titles.get(i));
bw.write("\n");
bw.write(t_contents.get(i));
bw.write("\n\n");
}
bw.close();
System.out.println("txt文件已经成功记录!");
}
catch(IOException e) {
e.printStackTrace();
}
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通