


网页内容爬取:如何提取正文内容
创建一个新网站,一开始没有内容,通常需要抓取其他人的网页内容,一般的操作步骤如下:
根据url下载网页内容,针对每个网页的html结构特征,利用正则表达式,或者其他的方式,做文本解析,提取出想要的正文。
为每个网页写特征分析这个还是太耗费开发的时间,我的思路是这样的。
Python的BeautifulSoup包大家都知道吧,
import BeautifulSoup soup = BeautifulSoup.BeautifulSoup(html)
利用这个包先把html里script,style给清理了:
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
清理完成后,这个包有一个prettify()函数,把代码格式给搞的标准一些:
soup.prettify()
然后用正则表达式,把所有的HTML标签全部清理了:
reg1 = re.compile("<[^>]*>")
content = reg1.sub('',soup.prettify())
剩下的都是纯文本的文件了,通常是一行行的,把空白行给排除了,这样就会知道总计有多少行,每行的字符数有多少,我用excel搞了一些每行字符数的统计,如下图:
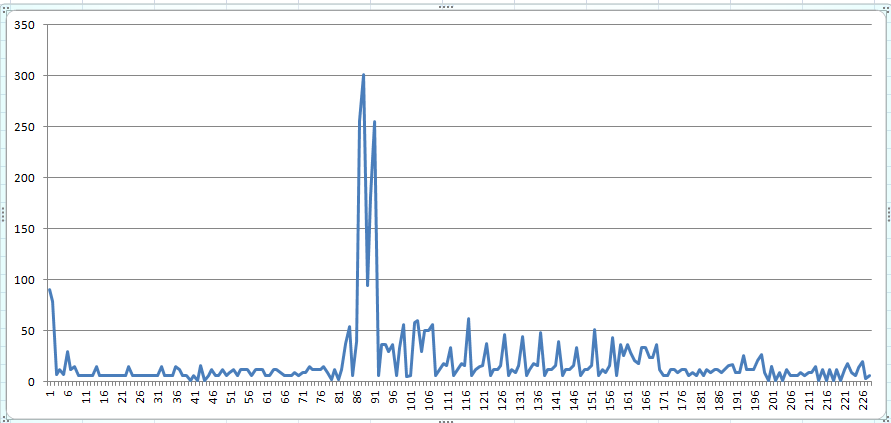
x坐标为行数,y坐标为该行的字符数
很明显,会有一个峰值,81~91行就应该是这个网页的正文部分。我只需要提取81~91行的文字就行了。
问题来了,照着这个思路,有什么好的算法能够通过数据分析的方式统计出长文本的峰值在哪几行?
附带一个开源的提取文本的python包,https://github.com/xgdlm/python-goose

