


scrapy爬虫小案例
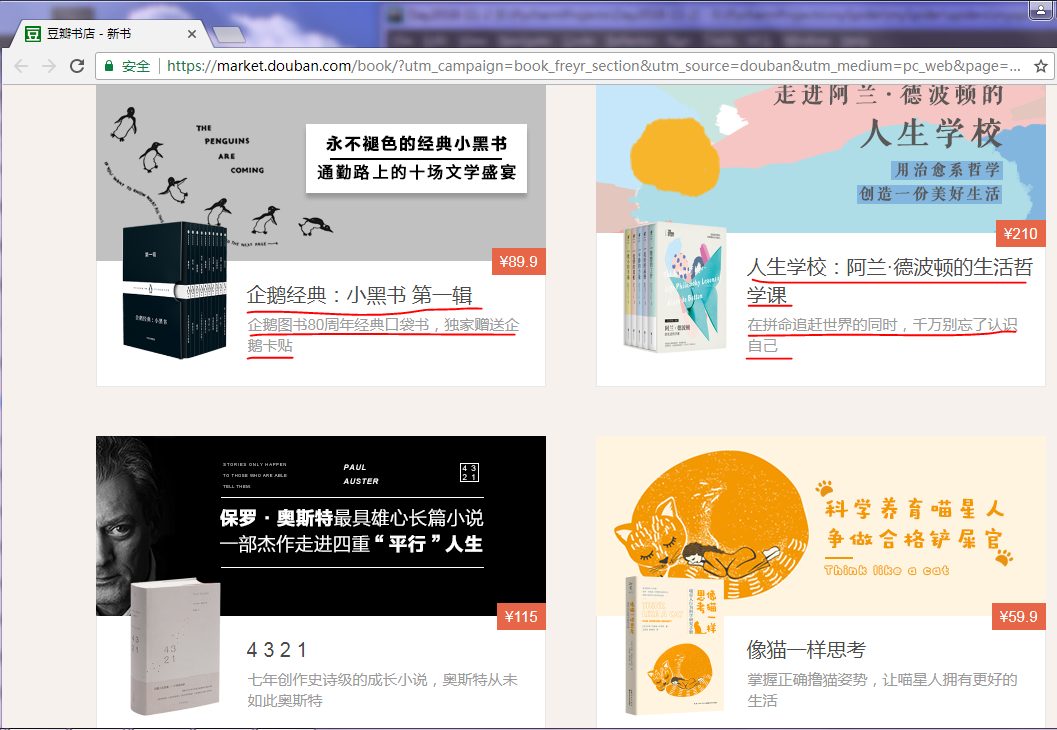
在豆瓣图书爬取书籍信息为例(爬取下面划红线的信息)
1.先创建一个mySpider项目(如何创建项目上面已经说过了)
2.打开mySpider目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据(因为要爬取的是两行信息,下面定义两个变量来存取字符串)
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class MyspiderItem(scrapy.Item): brief = scrapy.Field() quote = scrapy.Field()
2.在Terminal终端创建爬虫

3.重写myspider.py
# -*- coding: utf-8 -*- import scrapy from mySpider.items import MyspiderItem # 创建一个爬虫类 class MyspiderSpider(scrapy.Spider): # 爬虫名 name = 'myspider' # 允许爬虫作用的范围(只能在你输入的这个网址爬取信息) allowed_domains = ['https://market.douban.com/'] # 爬虫起始url start_urls = ['https://market.douban.com/book/?utm_campaign=book_freyr_section&utm_source=douban&utm_medium=pc_web&page=1&page_num=18&'] def parse(self, response): # with open('book.html', 'w') as f: # f.write(response.body) # 通过scrapy自带的xpath匹配出所有书的根节点 book_list = response.xpath('//div[@class="book-brief"]') bookItem = [] # 遍历根节点集合 xpath返回的一定是列表 for each in book_list: item = MyspiderItem() # extract() 将匹配出来的结果转换为Unicode字符串 # 无extract() 结果为xpath匹配对象 brief = each.xpath('./h3/text()').extract() quote = each.xpath('./div[@class="book-quote"]/p/text()').extract() item['brief'] = brief[0] item['quote'] = quote[0] # print(brief[0]) # print(quote[0]) bookItem.append(item) return bookItem
-
name = "":爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。 -
allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。 -
start_urls = ():爬取的URL元组/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。 -
parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
4.在终端输入
scrapy crawl myspider -o book.json (爬取结果以json文件形式输出)
scrapy crawl myspider -o book.csv (爬取结果以excel文件形式输出)
文件输出可能出现乱码情况,就要修改上面代码的编码情况
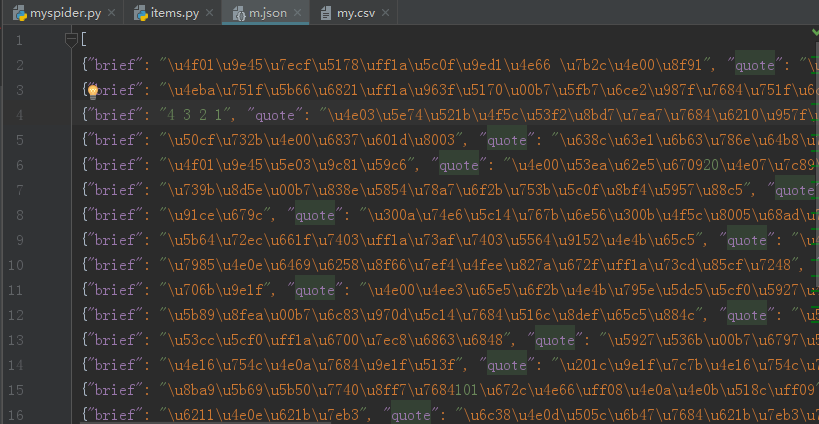
5.进去http://www.bejson.com/可以查看json文件输出内容
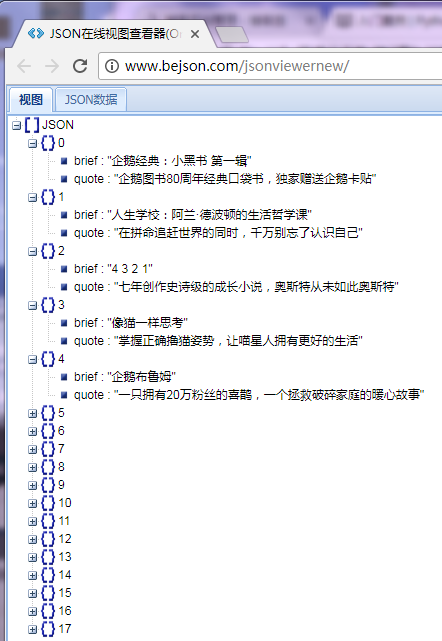
爬取成功
代码过程中主要的问题一是不能手动创建scrapy文件,必须使用终端,二是输出结果有时是乱码
我这次爬取的主要是一页的内容,还不会爬取多页的情况,继续学习。
