SQL基础
一、查询
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
SQL示例: SELECT COUNT(*) as num, role_main, role_assist FROM heros GROUP BY role_main, role_assist HAVING num > 5 ORDER BY num DESC
笛卡尔积(直接交叉连接):select * from t_player,t_team
join=inner join只返回两张表都存在的记录
SELECT player.player_id, player.team_id, player.player_name FROM player inner join player_score on player.player_id = player_score.player_id;
left join返回左边表全部记录,如果右表没有,显示为null
SELECT player_name, height, team_id FROM player WHERE height > (SELECT avg(height) FROM player)
exists记录必须存在
SELECT player_id, team_id, player_name FROM player WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id);
二、事务
幻读(Phantom Read)是一种数据库并发问题,发生在一个事务在执行过程中,看到另一个事务提交的对数据集合的变化(例如新增或删除的行),从而导致数据不一致,参考 https://www.jb51.net/database/292896rte.htm 。
mysql中repeatable read模式下使用间隙锁可以防止幻读,如sql语句加for update或者lock in share mode。
insert、update、delete也会自动加独占锁。
独占锁:其他事务不能加锁读或者写。
共享锁:其他事务可以加锁读,但是不能写。
repeatable read:它确保在同一个事务中,多次读取相同的记录时,读取到的数据内容是一致的。也就是说,在一个事务中,如果你在开始时读取了某个数据,那么在整个事务的生命周期中,你再次读取该数据时,应该会得到相同的结果。
三、索引
聚集索引:聚集索引是一种特殊的索引类型,其中数据行的物理存储顺序与索引的键值顺序相同。每张表只能有一个聚集索引,因为数据只能按照一种顺序进行存储。聚集索引的叶节点直接包含了数据行。所有键值都出现在叶子节点。所以数据文件和聚集索引是同一个文件,它们没有分开存储。
非聚集索引存储在单独的索引结构中,叶子节点包含键值和指向数据行的指针。
InnoDB非聚簇索引行指针实际存储的是聚簇索引键值,通过聚簇索引键再次查找到具体的数据行。
B+树索引结构如下图
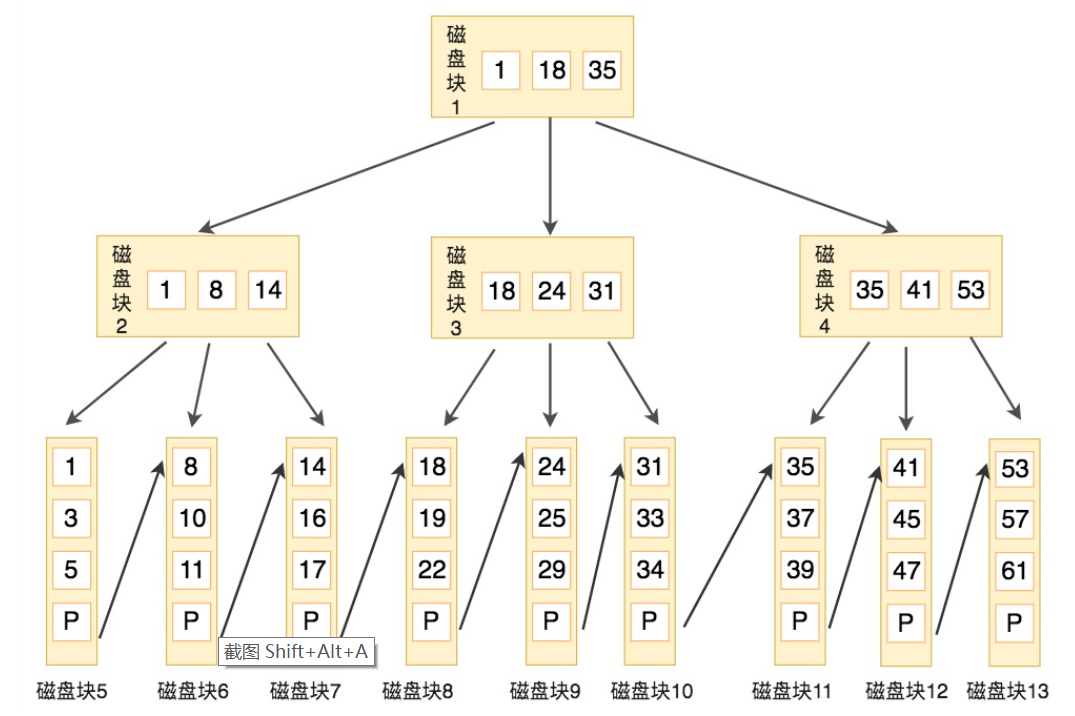
索引失效的常见情形:对索引进行表达式计算,对索引使用函数,like,where子句or前用了索引而后没有用索引导致or前索引失效
数据根据索引查询过程:从B+树结构索引根节点开始查询到叶节点,找到记录后把对应的数据页(mysql默认16KB)加载到内存,数据叶中数据以链表形式存在,数据页维护有页目录,方便进行二分查找。插入一条新记录时,InnoDB 会根据记录的键值(Key Value)在链表中找到合适的位置进行插入,而不是直接插入到链表的末尾。
唯一索引是找到一条就结束,普通索引需要在数据页中多几次查询,此时数据页已经加载到内存中,查询耗时基本可以忽略。
mysql的顺序读取,通过尽量减少磁盘I/O操作和有效利用磁盘预读机制,来提高数据库查询的效率,数据库在进行顺序读取时,会尝试一次性读取多个连续的数据页。
