

matlab libsvm工具箱,svm回归与分类
一、回归
1、例子:拟合曲线: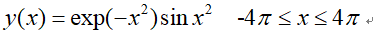
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | close all;clear;clc;%% 生成待回归的数据clear;X=-4*pi:0.05:4*pi;%X=1:100;Y=[];P=length(X);for i=1:P %Y(i)=1/X(i)^0.5; %Y(i)=sin(X(i)); %Y(i)=(sin(X(i))/X(i))^2; Y(i)=exp(-X(i)^2)*sin(X(i)^2);endscatter(X',Y',10,'b');hold on;model = svmtrain(Y',X','-s 3 -t 2 -c 2.2 -g 2.8 -p 0.01');% 利用建立的模型看其在训练集合上的回归效果[py,accuracy,decision_values] = svmpredict(Y',X',model);plot(X',py,'r'); |
结果:
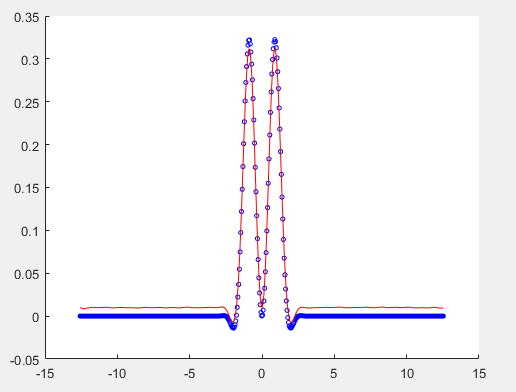
这里用了libsvm工具箱,函数model = svmtrain(Y',X','-s 3 -t 2 -c 2.2 -g 2.8 -p 0.01') 与 [py,accuracy,decision_values] = svmpredict(Y',X',model);
-s 3 表示回归
参考了:http://www.matlabsky.com/thread-12390-1-1.html,注意这里输入参数的形式。
2、svmtrain中输入参数:
-s svm类型:SVM设置类型(默认0)
- 0 -- C-SVC:C-支持向量分类机;参数C为惩罚系数,C越大表示对错误分类的惩罚越大,适当的参数C对分类Accuracy很关键。
- 1 --v-SVC:v-支持向量分类机;由于C的选取比较困难,用另一个参数v代替C。C是“无意义”的,v是有意义的。(与C_SVC其实采用的模型相同,但是它们的参数C的范围不同,C_SVC采用的是0到正无穷,该类型是[0,1]。)
- 2 – 一类SVM:单类别-支持向量机,不需要类标号,用于支持向量的密度估计和聚类。
- 3 -- e -SVR:ε-支持向量回归机,不敏感损失函数,对样本点来说,存在着一个不为目标函数提供任何损失值的区域。
- 4 -- v-SVR:n-支持向量回归机,由于EPSILON_SVR需要事先确定参数,然而在某些情况下选择合适的参数却不是一件容易的事情。而NU_SVR能够自动计算参数。
-t 核函数类型:核函数设置类型(默认2)
0 – 线性:u'v
1 – 多项式:(r*u'v + coef0)^degree
2 – RBF函数:exp(-r|u-v|^2)
3 –sigmoid:tanh(r*u'v + coef0)
-g r(gama):核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数)
-c cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1)
-p p:设置e -SVR 中损失函数p的值(默认0.1)
二、分类
例子:
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | clear;XA=ones(1,500);YA=ones(1,500); %初始化A类的输入数据XB=ones(1,500);YB=ones(1,500); %初始化B类的输入数据for i=1:500 XA(i)=cos(2*pi*(i+8)/25-0.25*pi)*(i+8)/25; YA(i)=sin(2*pi*(i+8)/25-0.25*pi)*(i+8)/25-0.25; XB(i)=sin(2*pi*(i+8)/25+0.25*pi)*(i+8)/-25; YB(i)=cos(2*pi*(i+8)/25+0.25*pi)*(i+8)/25-0.25;endscatter(XA,YA,20,'b');hold on;scatter(XB,YB,20,'k');hold off;X1=cat(1,XA,YA);X2=cat(1,XB,YB);X=cat(2,X1,X2); %得到训练数据集X,YY=zeros(1,1000);Y(1,1:500)=1;k=rand(1,1000);[m,n]=sort(k); %对k按照升序排列X=X(:,n(1:1000));%目的:打乱数据集的顺序Y=Y(:,n(1:1000));model = svmtrain(Y',X','-s 0 -t 2 -c 1.2 -g 2.8');[py,accuracy,decision_values] = svmpredict(Y',X',model);fprintf('使用多项式核函数,正确率:%f%%\n' ,100*sum(py==Y')/size(Y',1)); |
-s 0 表示分类 ;这里用的是 C-SVC:C-支持向量分类机。
(2)svmsvmpredict解析:
[predicted_label, accuracy/mse, decision_values]=svmpredict(test_label, test_matrix, model, ['libsvm_options']);
其中:
test _label 表示测试集的标签(这个值可以不知道,因为作预测的时候,本来就是想知道这个值的,这个时候,随便制定一个值就可以了,只是这个时候得到的accuracy就没有意义了)。
test _matrix 表示测试集的属性矩阵。
model 上面训练得到的模型。
libsvm_options 需要设置的一系列参数。
predicted_label 表示预测得到的标签。
accuracy/mse 是一个3*1的列向量,其中第1个数字用于分类问题,表示分类准确率;后两个数字用于回归问题,第2个数字表示mse;第三个数字表示平方相关系数(也就是说,如果分类的话,看第一个数字就可以了;回归的话,看后两个数字)。
decision_values 表示决策值(一般好像不怎么用)。
分类:
machine learning


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下