

深入解析当下大热的前后端分离组件django-rest_framework系列一
Nodejs的逐渐成熟和日趋稳定,使得越来越多的公司开始尝试使用Nodejs来练一下手,尝一尝鲜。在传统的web应用开发中,大多数的程序员会将浏览器作为前后端的分界线。将浏览器中为用户进行页面展示的部分称之为前端,而将运行在服务器,为前端提供业务逻辑和数据准备的所有代码统称为后端。
前后端分离是web应用的一种架构模式。在开发阶段,前后端工程师约定好数据交互接口,实现并行开发和测试;在运行阶段前后端分离模式需要对web应用进行分离部署,前后端之间使用HTTP或者其他协议进行交互请求。在前后端分离架构中,后端只需要负责按照约定的数据格式向前端提供可调用的API服务即可。前后端之间通过HTTP请求进行交互,前端获取到数据后,进行页面的组装和渲染,最终返回给浏览器。

从目前应用软件开发的发展趋势来看,主要有两方面需要注意:
-
越来越注重用户体验,随着互联网的发展,开始多终端化。
-
大型应用架构模式正在向云化、微服务化发展。
我们主要通过前后端分离架构,为我们带来以下四个方面的提升:
-
为优质产品打造精益团队
通过将开发团队前后端分离化,让前后端工程师只需要专注于前端或后端的开发工作,是的前后端工程师实现自治,培养其独特的技术特性,然后构建出一个全栈式的精益开发团队。 -
提升开发效率
前后端分离以后,可以实现前后端代码的解耦,只要前后端沟通约定好应用所需接口以及接口参数,便可以开始并行开发,无需等待对方的开发工作结束。与此同时,即使需求发生变更,只要接口与数据格式不变,后端开发人员就不需要修改代码,只要前端进行变动即可。如此一来整个应用的开发效率必然会有质的提升。 -
完美应对复杂多变的前端需求
如果开发团队能完成前后端分离的转型,打造优秀的前后端团队,开发独立化,让开发人员做到专注专精,开发能力必然会有所提升,能够完美应对各种复杂多变的前端需求。 -
增强代码可维护性
前后端分离后,应用的代码不再是前后端混合,只有在运行期才会有调用依赖关系。
应用代码将会变得整洁清晰,不论是代码阅读还是代码维护都会比以前轻松。
rest_framework的简单了解
在Django中,有一个个的应用(app),比如admin、form、contenttype等,rest_framework也是一个应用,只不过这个应用是基于restful协议实现的。通过一些接口实现对数据快速的增删改查。这套应用主要是通过发送不同的请求方式,来实现对数据的增删改查。
以book为例:
url 请求方式 相关操作
/books/ get 查看书籍
/books/ post 添加书籍
/books/1/ put/patch 修改书籍
/books/1/ delete 删除书籍
备注:put与patch请求的区别:都是编辑修改,put是整体修改,patch是局部的修改。
这样的设计风格是应用于CBV的(class based view),所以在了解rest_framework之前,我们先了解Django中是如何通过CBV实现路由的分发。
Django中CBV的内部实现流程
首先,从路由出发,在每一个url后面,对应的会执行一个as_view()的类方法,在Django启动的时候 ,会直接执行,返回一个视图函数。
#cbv形式的url
urlpatterns = [
url(r'^login/',views.Login.as_view()),
]
首先,从Login这个类中找as_view()方法,没有就从父类中找,继承View,在父类中有一个as_view()的类方法。

class View(object):
"""
Intentionally simple parent class for all views. Only implements
dispatch-by-method and simple sanity checking.
"""
http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
def __init__(self, **kwargs):
"""
Constructor. Called in the URLconf; can contain helpful extra
keyword arguments, and other things.
"""
# Go through keyword arguments, and either save their values to our
# instance, or raise an error.
for key, value in six.iteritems(kwargs):
setattr(self, key, value)
@classonlymethod
def as_view(cls, **initkwargs):
"""
Main entry point for a request-response process.
"""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view
我们看看as_view()中都实现了什么?返回一个view,view是as_view()内部的一个函数,所以当用户访问url时,直接执行这个view(),返回一个self.dispatch(request, *args, **kwargs),首先在本类中找,没有这样一个方法,从父类View中找,
class View(object):
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
我们来瞅瞅这个dispatch方法中都干了什么?
首先,先判断请求方式在不在http_method_names这个列表中,如果在,就通过反射,得到一个handler(以请求方式小写的形式的函数),然后调用这个handler(),所以,在View函数中,dispatch方法实现了按照请求方式分发的功能。
我们发送get请求,对应的就执行类中的get()方法,也就是发送什么请求,就对应执行对应的方法。通过这种方式,我们直接在对应的方法下实现对应的视图函数即可。
这就是django内部的视图类的路由分发的实现方式,说这么多,对于我们的rest_framework有什么用呢?很直白的告诉你,rest_framework就是基于这种方式二次封装,从而实现通过请求方式来对对应数据的增删改查。
rest_framework的准备工作
了解rest_framework之前,首先,要下载rest_framework:
pip install djangorestframework
既然是Django的一个应用,就要先将这个应用添加到settings.py中的INSTALLED_APPS中:
INSTALLED_APPS = (
...
'rest_framework',
)
使用rest_framework快速实现一个简单的增删改查
在深入了解rest_framework之前,我们先快速实现一个基于rest_framework的示例:
urls.py
from django.conf.urls import url, include
from rest_framework import routers
from framework import views
# Routers provide an easy way of automatically determining the URL conf.
router = routers.DefaultRouter()
router.register(r'users', views.UserViewSet)
router.register(r'books',views.BookViewSet)
# Wire up our API using automatic URL routing.
# Additionally, we include login URLs for the browsable API.
urlpatterns = [
url(r'^', include(router.urls)),
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]
app下的models.py
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
app下的views.py
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets
from framework import models
# Serializers define the API representation.
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ('url', 'username', 'email', 'is_staff')
# ViewSets define the view behavior.
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# Book 模型
class BookSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = models.Book
fields = ['url','title']
class BookViewSet(viewsets.ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BookSerializer
这样,我们就实现了一个书籍的增删改查,启动Django,访问http://127.0.0.1:8000/,就会出现下面这个页面:
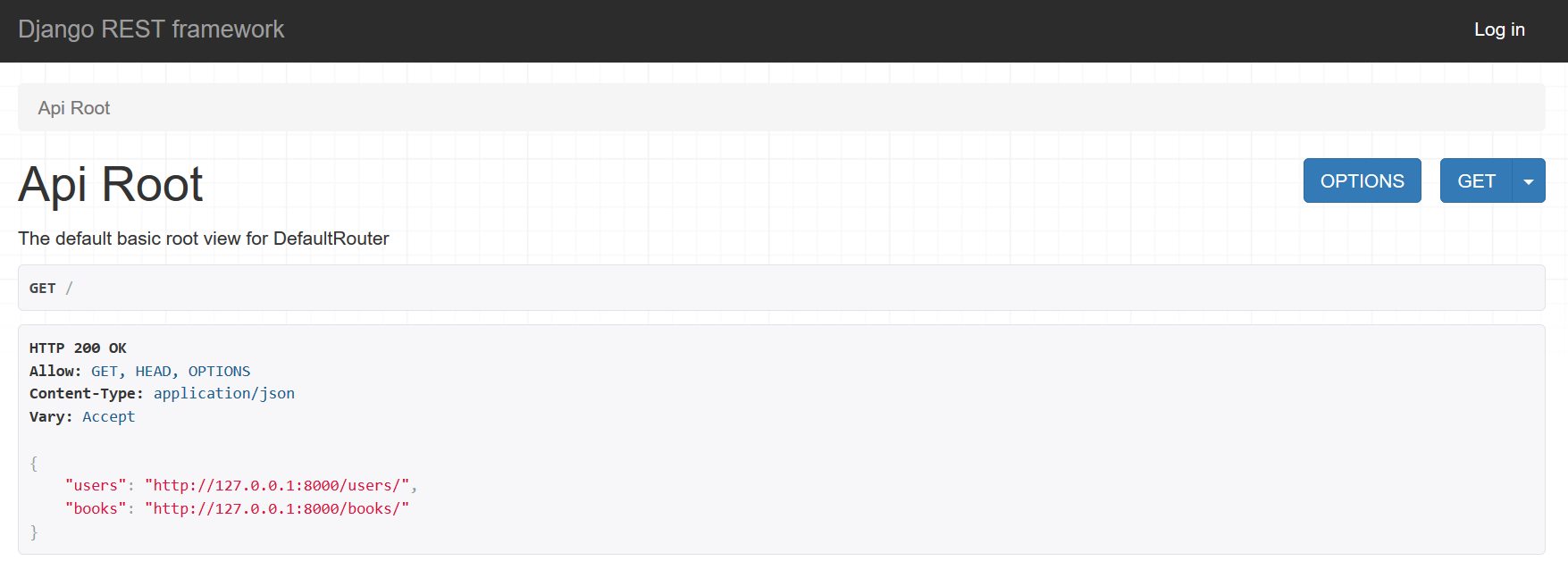
当然,这个页面不是我们写的,是rest_framework内置的一个页面。这是rest_framework提供给我们用作测试的页面。
小技巧:访问rest_framework中对应的url时,在路径后面拼上?format=json,我们可以得到该数据的一个json字符串形式的列表。
使用rest_framework,我们并没有返回一个HTML页面,只是返回了一堆json格式的字符串。没错,这就是restful协议的实现方式,通过不同的请求返回固定格式的数据,从而实现前后端分离,这就是restful所要实现的。
django的rest_framework组件实现了前后端的分离,后端只需提供相应接口即可,前端发送什么请求,就返回什么数据,从而使得前后端各司其职。
使用rest_framework在后端的开发中,肯定会发送响应的请求测试数据,这里,我们借助一个很NB的插件:Postman
通过rest_framework,可以快速的实现对一个模型表的增删改查,那它内部到底都帮我们做了哪些事情?这个应用都实现了哪些功能呢?
组件一、APIView
首先,先导入
from rest_framework.views import APIView
看看这个APIView都实现了什么?
class APIView(View):
@classmethod
def as_view(cls, **initkwargs):
"""
Store the original class on the view function.
This allows us to discover information about the view when we do URL
reverse lookups. Used for breadcrumb generation.
"""
if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet):
def force_evaluation():
raise RuntimeError(
'Do not evaluate the `.queryset` attribute directly, '
'as the result will be cached and reused between requests. '
'Use `.all()` or call `.get_queryset()` instead.'
)
cls.queryset._fetch_all = force_evaluation
view = super(APIView, cls).as_view(**initkwargs)
view.cls = cls
view.initkwargs = initkwargs
# Note: session based authentication is explicitly CSRF validated,
# all other authentication is CSRF exempt.
return csrf_exempt(view)
很明显,APIView继承了View,并且重新封装了as_view()方法,返回了view,这么一看,好像跟 父类View中的as_view()方法没什么特大的区别,只是做了一些扩展。rest_framework真正NB的地方是下面这个方法的封装,在父类View中,view返回self.dispatch(),APIView重写了dispatch方法,意义重大。
class APIView(View):
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
self.initial(request, *args, **kwargs)
# Get the appropriate handler method
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
备注:在try中的self.initial(request,...)执行了auth组件,权限组件,频率组件。
 View Code
View Code这个dispatch方法中,try里面的内容跟父类中view的实现一模一样,也是实现了一个分发,没有多大的意义,但是,在try上面,
request = self.initialize_request(request, *args, **kwargs) self.request = request
这两行代码,重中之重,实现了对request方法的封装和重写。
为什么要重写request呢?
因为在Django中,信息的解析与封装是通过wsgiref这个模块实现的,这个模块有一个缺陷。封装的request.POST方法不支持json格式的字符串,也就是说这个模块中没有提供json格式的解析器。而前后端的分离,就需要一种前后端都支持的数据格式,那就是json,而这恰好是wsgiref所无法实现的,要实现前后端分离,必须要对request方法重写。
rest_framework是如何实现request的重写的。
那我们看看self.initialize_request(request, *args, **kwargs)里面都实现了那些东西?
from rest_framework.request import Request
class APIView(View):
def initialize_request(self, request, *args, **kwargs):
"""
Returns the initial request object.
"""
parser_context = self.get_parser_context(request)
return Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
这个方法return了一个类Request的实例对象,这个Request类传入旧的request,对旧的equest进行了一系列的加工,返回新的request对象
class Request(object):
"""
Wrapper allowing to enhance a standard `HttpRequest` instance.
Kwargs:
- request(HttpRequest). The original request instance.
- parsers_classes(list/tuple). The parsers to use for parsing the
request content.
- authentication_classes(list/tuple). The authentications used to try
authenticating the request's user.
"""
def __init__(self, request, parsers=None, authenticators=None,
negotiator=None, parser_context=None):
assert isinstance(request, HttpRequest), (
'The `request` argument must be an instance of '
'`django.http.HttpRequest`, not `{}.{}`.'
.format(request.__class__.__module__, request.__class__.__name__)
)
self._request = request
self.parsers = parsers or ()
self.authenticators = authenticators or ()
self.negotiator = negotiator or self._default_negotiator()
self.parser_context = parser_context
self._data = Empty
self._files = Empty
self._full_data = Empty
self._content_type = Empty
self._stream = Empty
初始化的过程中,我们可以得到一些对我们有用的信息,我们可以通过这个类Request的实例对象,也就是新的request,通过
request._request 就可以得到我们旧的request。
class Request(object):
@property def query_params(self): """ More semantically correct name for request.GET. """ return self._request.GET @property def data(self): if not _hasattr(self, '_full_data'): self._load_data_and_files() return self._full_data
所以,我们可以通过这个新的request.query_params 得到旧的request.GET的值(这个方法没啥卵用),最关键的是request.data这个方式,可以得到序列化后的数据,这个方法补全了旧request的不足。
备注:在request.data中,提供了很多数据类型的解析器,包括json的,所以,对于提交的数据,我们可以直接通过这个方法获取到。而不需要通过request.POST。
那么我们接下来说说rest_framework的下一个组件-------序列化组件
组件二、serializers
开发我们的Web API的第一件事是为我们的Web API提供一种将代码片段实例序列化和反序列化为诸如json之类的表示形式的方式。
我们在使用json序列化时,有这么几种方式:
第一种,借助Python内置的模块j。手动构建一个字典,通过json.dumps(obj)得到一个json格式的字符串,使用这种方式有一定的局限性,那就是我们无法控制这张表中的字段,有多少个字段,我们就需要添加多少个键值对,一旦后期表结构发生变化,就会很麻烦。
第二种方式:解决上述方式中字段的不可控性,就需要借助Django中内置的一个方法model_to_dict,(from django.forms.models import model_to_dict),我们可以将取出的所有的字段循环,依次将每个对象传入model_to_dict中,这样就解决了字段的问题。
还有一种方式,也是Django提供的一个序列化器:from django.core.serializers import serialize ,我们可以直接将queryset数据类型直接传进去,然后指定我们要转化的格式即可,这两种Django提供给我们的方法虽然可以解决这个序列化字段的问题,但是有一个缺点,那就是我们可以直接将一个数据转化为json字符串形式,但是却无法反序列化为queryset类型的数据。
rest_framework提供了一个序列化组件---serializers,完美的帮助我们解决了上述的问题:from rest_framework import serializers ,用法跟Django中forms组件的用法非常相似,也需要先自定制一个类,然后这个类必须继承serializers.Serializer,然后我们需要序列化那些字段就在这个类中配置那些字段,还可以自定制字段的展示格式,非常的灵活。
models部分:
from django.db import models
# Create your models here.
class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish")
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title
class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name
views部分:
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import *
from django.shortcuts import HttpResponse
from django.core import serializers
from rest_framework import serializers
class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
publish=serializers.CharField(source="publish.name")
#authors=serializers.CharField(source="authors.all")
authors=serializers.SerializerMethodField()
def get_authors(self,obj):
temp=[]
for author in obj.authors.all():
temp.append(author.name)
return temp
class BookViewSet(APIView):
def get(self,request,*args,**kwargs):
book_list=Book.objects.all()
# 序列化方式1:
# from django.forms.models import model_to_dict
# import json
# data=[]
# for obj in book_list:
# data.append(model_to_dict(obj))
# print(data)
# return HttpResponse("ok")
# 序列化方式2:
# data=serializers.serialize("json",book_list)
# return HttpResponse(data)
# 序列化方式3:
bs=BookSerializers(book_list,many=True)
return Response(bs.data)
值得注意的时,我们使用这种方式序列化时,需要先实例化一个对象,然后在传值时,如果值为一个queryset对象时,需要指定一个参数many=True,如果值为一个obj时,不需要指定many=False,默认为False。
#我们自定义一个类Bookserialize,继承serializers.Serializer
from framework.views import Bookserialize
from framework import models
book_list = models.Book.objects.all()
bs= Bookserialize(book_list,many=True)
bs.data
[OrderedDict([('title', '神墓')]), OrderedDict([('title', '完美世界')])]
# queryset对象 结果为一个列表,里面放着每一个有序字典
book_obj = models.Book.objects.first()
bs_ = Bookserialize(book_obj)
bs_.data
{'title': '神墓'}
# 如果为一个对象时,结果为一个字典
特别需要注意的是:使用这种方式序列化时,对于特殊字段(一对多ForeignKey、多对多ManyToMany),serializers没有提供对应的字段,需要指定特殊的方式,因为obj.这个字段时,得到的是一个对象,所以我们对于FK,需要使用一个CharField字段,然后在这个字段中指定一个source属性,指定显示这个对象的那个字段。同样的,对于多对多的字段,我们也要使用特殊的显示方式:SerializerMethodField(),指定为这种字段类型时,显示的结果为一个自定义的函数的返回值,这个自定义函数的名字必须是get_字段名,固定写法,接收一个obj对象,返回值就是该字段在序列化时的显示结果。
另外,我们在取值时,直接通过这个对象.data的方式取值,这是rest_framework提供给我们的序列化接口。
其实。我们应该明白它内部的实现方式:如果值为一个queryset对象,就创建一个list,循环这个queryset得到每一个数据对象,然后在循环配置类下面的每一个字段,直接这个对象obj.字段 得出值,添加到一个字典中,在将这个字典添加到这个列表中。所以,对于这些特殊字段,我们取值时,通过这种方式得到的是一个对象。
通过这种方式就会出现一个问题,我们每序列化一个表,就要将这个表中的字段全部写一遍,这样显得很麻烦。在Djangoforms组件中,有一个ModelForm,可以帮我们将我们模型表中的所有字段转化为forms组件中对应的字段,同样的,在serializers中,同样有一个,可以帮我们将我们的模型类转化为serializers中对应的字段。这个组件就是ModelSerializer。
组件三、ModelSerializer
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
depth=1
备注:
1.定义一个depth=1 会将特殊字段 FK和M2M中每个对象的所有字段全部取出来。
2.对于FK字段,显示的是主键值,对于多对多字段,默认显示方式为:[pk1,pk2,...],一个列表中,包含所有字段对象的主键值。如果我们不想显示主键值,可以重写对应字段属性。
class BookModelSerializers(ModelSerializer):
class Meta:
model=Book
fields="__all__"
authors=serializers.SerializerMethodField()
def get_authors(self,obj):
temp=[]
for obj in obj.authors.all():
temp.append(obj.name)
return temp
3.对于含有choices的字段,我们可以通过指定字段的source来显示展示的值
比如:course_class = models.Integerfield(choices=((1,'初级'),(2,'中级')))
course_class = serializers.CharField(source='get_course_class_display')
提交post请求
def post(self,request,*args,**kwargs):
bs=BookSerializers(data=request.data,many=False)
if bs.is_valid():
# print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
备注:跟form组件类似,如果校验不通过,可以通过这个对象.errors将错误信息返回。
重写save中的create方法
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
# exclude = ['authors',]
# depth=1
def create(self, validated_data):
authors = validated_data.pop('authors')
obj = Book.objects.create(**validated_data)
obj.authors.add(*authors)
return obj
单条数据的get和put请求
class BookDetailViewSet(APIView):
def get(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj)
return Response(bs.data)
def put(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,data=request.data)
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
超链接API:Hyperlinked
class BookSerializers(serializers.ModelSerializer):
publish= serializers.HyperlinkedIdentityField(
view_name='publish_detail',
lookup_field="publish_id",
lookup_url_kwarg="pk")
class Meta:
model=Book
fields="__all__"
#depth=1
urls部分:
|
1
2
3
4
5
6
|
urlpatterns = [ url(r'^books/$', views.BookViewSet.as_view(),name="book_list"), url(r'^books/(?P<pk>\d+)$', views.BookDetailViewSet.as_view(),name="book_detail"), url(r'^publishers/$', views.PublishViewSet.as_view(),name="publish_list"), url(r'^publishers/(?P<pk>\d+)$', views.PublishDetailViewSet.as_view(),name="publish_detail"),] |
总结
restframework中的APIView组件,弥补了Django中对于json数据格式的支持,通过前后端都支持的json,完美的实现了前后端分离,使得后端只需要提供数据接口即可,而且restframework组件中的serializers组件,提供了更快捷、更灵活的序列化支持。下个系列中,将主要阐述restframework对视图函数的三层封装,感受一下视图三部曲的神奇。
作者:高赛
出处:https://i.cnblogs.com/EditPosts.aspx?opt=1
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

