
2.技术选型:
prometheus、zabbis、nagios、open-falcon进行选型
监控系统 语言 成熟度 扩展性 性能 社区活跃 容器支持 企业使用
zabbix c+php 高 高 低 中 低 高
nagios c 高 中 中 低 低 低
open-falcon go 中 高 高 中 中 中
prometheus go 中 高 高 高 高 高
zabbix、open-falcon可以自定义脚本,zabbix可以推拉都支持,prometheus定义了监控数据规范,可以通过开发各种exporter扩展系统采集能力
zabbix用mysql导致性能有硬伤,nagios和open-falcon都是rdd环形数据库存储模式,但是open-falcon是做了一致性hash实现数据分片的,还能对接OpenTSDB,prometheus是自研了时序数据库,每秒千万级数据存储
open-falcon基本是国内公司活跃
skywalking往往是用他来做APM,系统性能监控(每分钟访问量、接口延迟)+ 链路追踪,prometheus+grafana -> 所有机器的可视化监控(cpu、内存、磁盘、io、网络),ELK存储日志是国内大部分公司都常见的
3.prometheus监控数据指标的分类讲解
counter,只增不减,机器启动时间(从系统启动开始计算到现在为止的时间)、http总访问量一类的,跟rate配合,看各个时间段里的指标变化情况,比如QPS,每秒的http请求数,以及这个变化率,就是通过counter可以算出来的
gauge,仪表盘,指标实时变化情况,cpu和内存使用量,网络io大小,总量恒定,但是变化的时候可大可小
summary,数据分布状况,比如接口响应时间,TP50、TP75、TP90、TP95、TP99,50%的接口请求都是少于20ms,75%的请求少于50ms,90%的请求少于100ms,95%可能是300ms,99%可能是1s,50%小于几毫秒、75%、90%、95%、99%
histogram,区间内样本个数
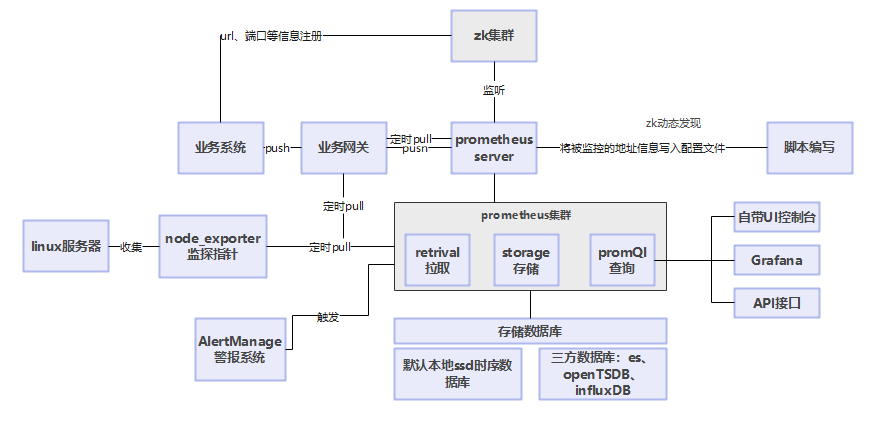
4.Prometheus联邦集群部署架构设计
两层架构,每个prometheus server负责监控一部分的机器,上层有联邦节点,负责汇总下层节点的数据,但是这里有一个问题,那就是负责监控部分机器的单个server还不是高可用的,这是有问题的
后来有一个国外公司开源的Prometheus高可用方案,叫做Thanos,无缝集成Prometheus
querier,sidercar,store,compactor
每个prometheus上都得部署一个sidercar,他是负责代理querier对server数据的读取的,另外还会把本地存储数据写到对象存储中去,querier接收http的promql查询,负责数据查询汇聚,向sidecar发送grpc请求,sidecar调用prometheus api获取数据,querier聚合数据在一起
查询数据的时候,如果查询的是历史数据,querier调用store接口,直接从对象存储里获取数据,compactor是屁处理组件,针对对象存储进行压缩,把雄安对象合并压缩成大对象,节约磁盘占用
5.Prometheus本地TSDB时序数据存储设计
时序数据,按照时间来排序和组织再一起的一段数据,存储和查询都是按照时间熟悉来进行查找的,mysql(b树索引来存储+基于索引来查询+事务),hbase(按照rowkey来进行kv格式的数据存储),InfluxDB、OpenTSDB和prometheus自研TSDB是按照时间顺序来组织和存储数据的
监控数据按照时间分隔成block,大小不固定,按照步长倍数递增,最小的block保存2h监控数据,步数为3,步长为3,block的大小就是2h、6h、18h,小block合并大block,二个2h的block合并为6h的block
block文件名是创建时间,可以按时间对block排序
block有4个部分,chunks、index、meta.json、tombstones,chunks就是压缩后的时序数据,每个chunk是512mb
index是对数据进行检索设计的,记录chunk里时序的offset,TOC表是index入口,记录index文件里其他表的位置,写入其他表的是之前,先把当前offset作为该表地址记录下来,读取index先读取TOC表
symbol table,tsdb对磁盘里的标签是避免重复存储的,都是用符号表里的索引来代替的,时序列表,series,记录block中每个时序的标签以及这些时序关联的chunk块,label index table,把相同标签组合知道一起,postings表,代表标签和时序的关联关系
查询某个时间段某个指标的监控数据,先根据时间段找到block,加载每个block的index文件,读取index的TOC表找到其他表,最后52个字节就是TOC表(6个表*每个表8字节的offset+4字节的crc校验和),接着找到符号表,确定指标标签在符合表里的索引id,接着基于这个索引id继续查找
指标标签是在标签索引表里,找到标签再postings table的位置,找到具体的posting,这样就能找到这个标签对应的时序了,找到对应的时序后,根据时序表查找他在block里的位置,就可以读取磁盘加载监控数据了
tombstone是对数据进行软删除的
meta.json是block的元数据
WAL,预写日志,为了防止暂存内存中的数据丢失,引入WAL,分隔为默认大小为128mb的文件segment,数字命名,00000001一类的,WAL的写入单位是page,每个page是32kb
远端存储,是一套接口,引入adapater适配器,把读写请求转化为第三方远端存储接口,InfluxDB、OpenTSDB,CreateDB、TiDB、Cortex、M3DB等等,http post请求+protobuf编码,调用adapter的读写接口,接口定义再remote.proto文件里,读请求是同步的,但是写请求是异步的
多个分片队列,合并数据后异步一次性发送数据过去,分片队列默认是1个,10s重新计算一次,动态可变,合并后再给adapter就可以了


