
1.redis持久化




在客户端发布save的过程中有可能造成阻塞,如一千万条数据同时保存并生成二进制RDB文件的时候,此时就会延迟堵塞。
文件策略是如果存在老的RDB文件,会用新的文件替代老的文件如下图所示:

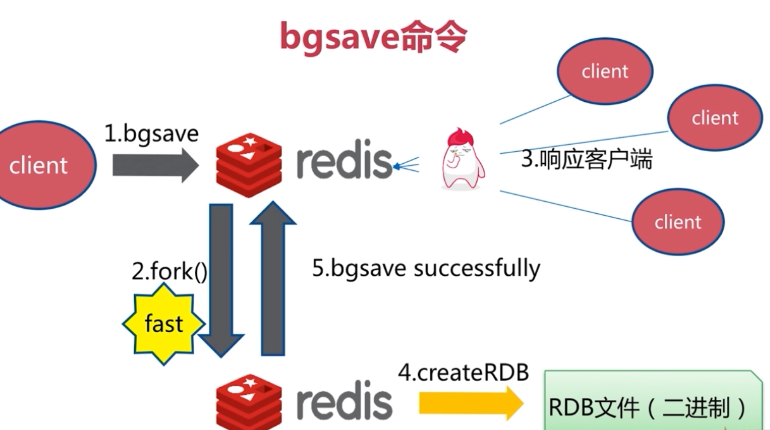
对于bgsave而言,它会利用linux中的fork()函数生成一个redis的子进程(fast的意思是相对来说速度比较快,但是当量大的时候依旧有可能阻塞主线程),然后再生成RDB文件,并且将成功生成的消息(bgsave successfully)返回告诉主进程,并响应客户端如下图所示:
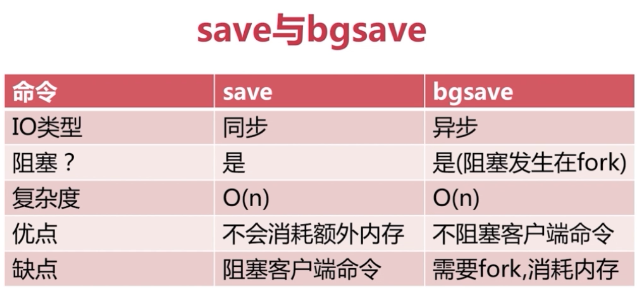
5.save与bgsave的对比:所说的阻塞对比当量小的时候几乎没区别
6.若客户端不发布save的命令,redis也可以进行保存的操作配置。不论是60秒发布10000条,还是300秒发布10条,还是900秒发布一条信息都会进行更新保存并生成RDB文件。利用的就是bgsave来保存生成,(但是这种操作也有不合适的弊端,就是文件写入过于频繁,60秒就需要更新10000条)
对于生成的RDB文件一般用dump.rdb的格式来保存。
最佳配置:
 :当保存出错时是否停止写入
:当保存出错时是否停止写入
 :是否要压缩文件,rdb文件会在主从之间进行拷贝,采用压缩的形式可以加快拷贝速度
:是否要压缩文件,rdb文件会在主从之间进行拷贝,采用压缩的形式可以加快拷贝速度
 :是否对rdb文件进行校验检验
:是否对rdb文件进行校验检验
·  :文件名一般用端口号来区分
:文件名一般用端口号来区分
 :一般情况下不选用根目录来保存,而是选择大的硬盘路径来保存
:一般情况下不选用根目录来保存,而是选择大的硬盘路径来保存
总结RDB:
1耗性能,耗时(对所有数据进行dump,其次写会消耗很多的cpu和内存(IO性能),是个on的过程(copy-on-write策略))
2不可控,丢失数据(定时保存或多或少会丢失一部分数据)
AOF:
AOF的三种策略:always,everysec,no
always:写的命令会进入到缓存区中,每条命令fsync到硬盘中生成AOF文件
everysec:写的命令会进入到缓存区中,每秒都会刷新fsync到硬盘中生成AOF文件(出现故障的时候有可能会丢失一秒的数据)
no:写的命令会进入到缓存区中,会根据不同的系统来选择写入还是不写入,不需要人为考虑,系统自动判断
一般情况下根据各方面权衡会默认选择使用everysec的方案

7.当高并发或者时间推移日志文件会变得冗余,很消耗内存,此时可以选择使用AOF重写,AOF重写可以减少硬盘的占用量,加速恢复速度,
AOF重写的两种实现方式:
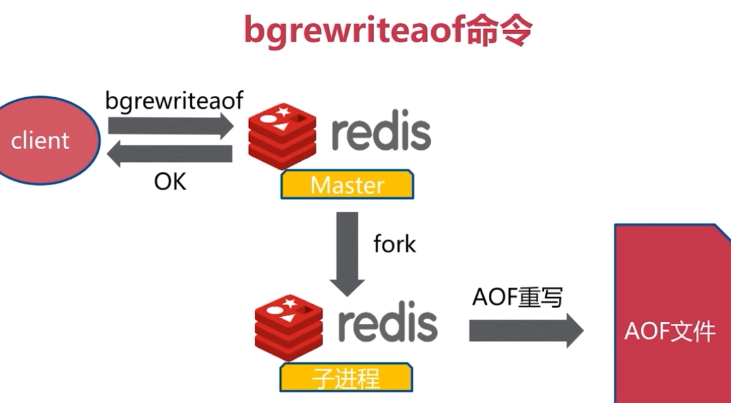
1.bgrewriteaof:和bgsave类似
2.AOF重写配置

配置:no-appendfsync-on-rewrite :是否关闭重写
。。。。perscentage 100:表示增长率

RDB和AOF的取舍:

RDB:集中管理可以一次性写入大量,但不要太频繁,因为对机器内存cpu等影响比较大,

AOF:建议一直开着,也体现出redis持久化的特点,等到一定时间可以关闭,毕竟开缓存也需要一定的开销
集中管理利用fork(),但是也有可能出现内存爆满的情况
RDB:集中管理可以一次性写入大量,但不要太频繁,因为对机器内存cpu等影响比较大,

最佳策略:小分片:利用redis进行内存分配,每个内存分配最大4G,当然cpu的消耗也比较大



