【CVPR2023】Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
 > 论文:https://readpaper.com/paper/4728855966703960065
> 论文:https://readpaper.com/paper/4728855966703960065
这个论文的代码地址叫GRL,意思是 Global, Regional, Local 的意思,作者从三个尺度对特征建模,核心是构建了一个 anchored strip self-attention。
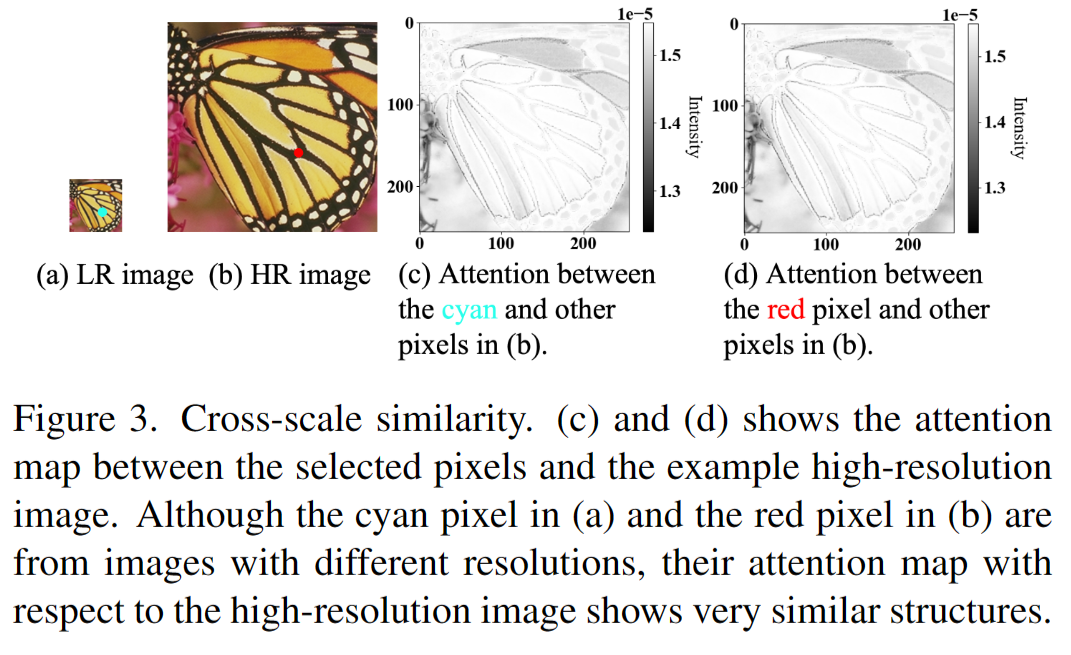
如何从Global, Regional, Local三个尺度有效对特征建模,是当前难题。作者首先观察一个现象发, 下图所示,低分辨率图像中青色点的 attention map 和高分辨率图像中红色点的 attention map 非常相似,说明图像的结构在不同尺度上被复制。
因此,作者设计了一个 anchored strip attention,在Q和K之间建立了一个隐空间 A,叫做 anchor (可能叫别的名字也可以)。首先将输入投影到维度较低的 A,然后分别和 K 和 Q 做矩阵乘法,得到 (替换原来的K) 和 (替换换原来的Q),接下来就是传统的 QKV 三件套操作了。本质来看,就是通过引入 anchor,作为一个中间体来减少了计算量。
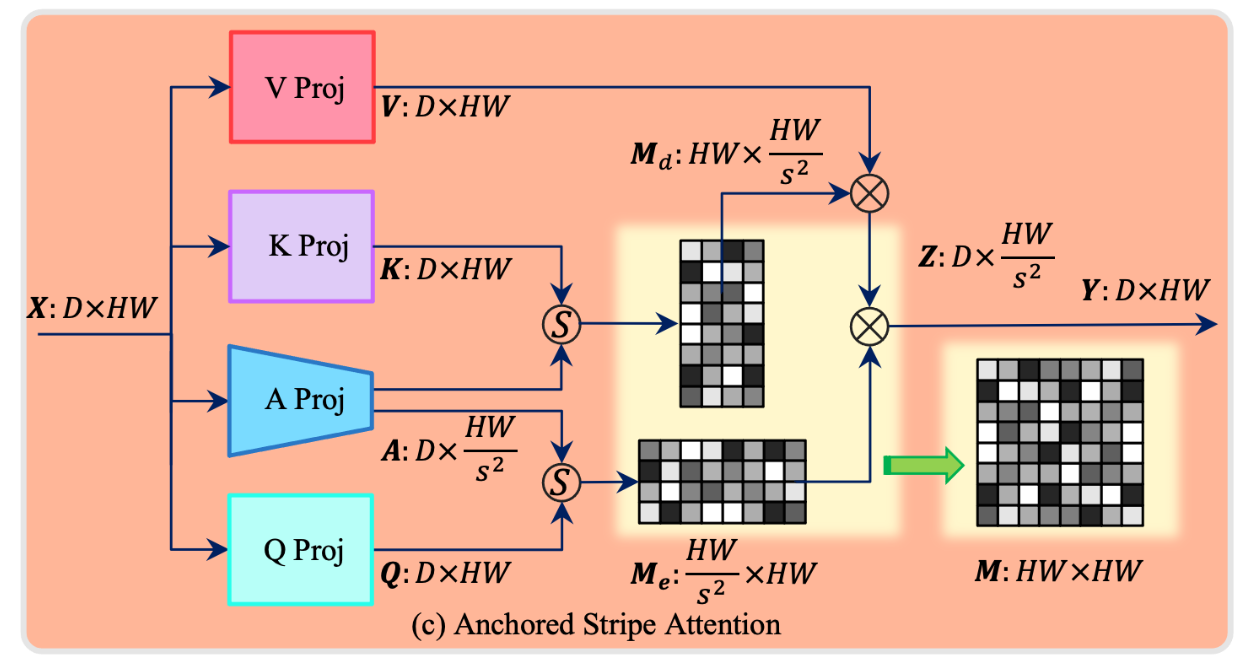
论文还提到使用了 strip attention 的概念,但是我感觉,这个 貌似取任何值都可以啊,和 strip 关联并不是特别大。也许我看的不够仔细,欢迎大家指正。
实验可以参考作者论文,这里不过多介绍。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY