【AAAI2023】Ultra-High-Definition Low-Light Image Enhancement
【AAAI2023】Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
这个论文首先构建了ultra-high definition low-light (UHD-LOL)数据集,然后提出了 Low-Light Transformer (LLFormer)。
LLFormer 的整体框架如下所示,可以看出和 Restormer 有些类似。我的理解,作者改进了三个点:1、Transformer block里面修改了 attention;2、Transformer block里修改了FFN;3、添加了 cross-layer attention 。改进的部分分别用绿框标出了,下面分别进行介绍。
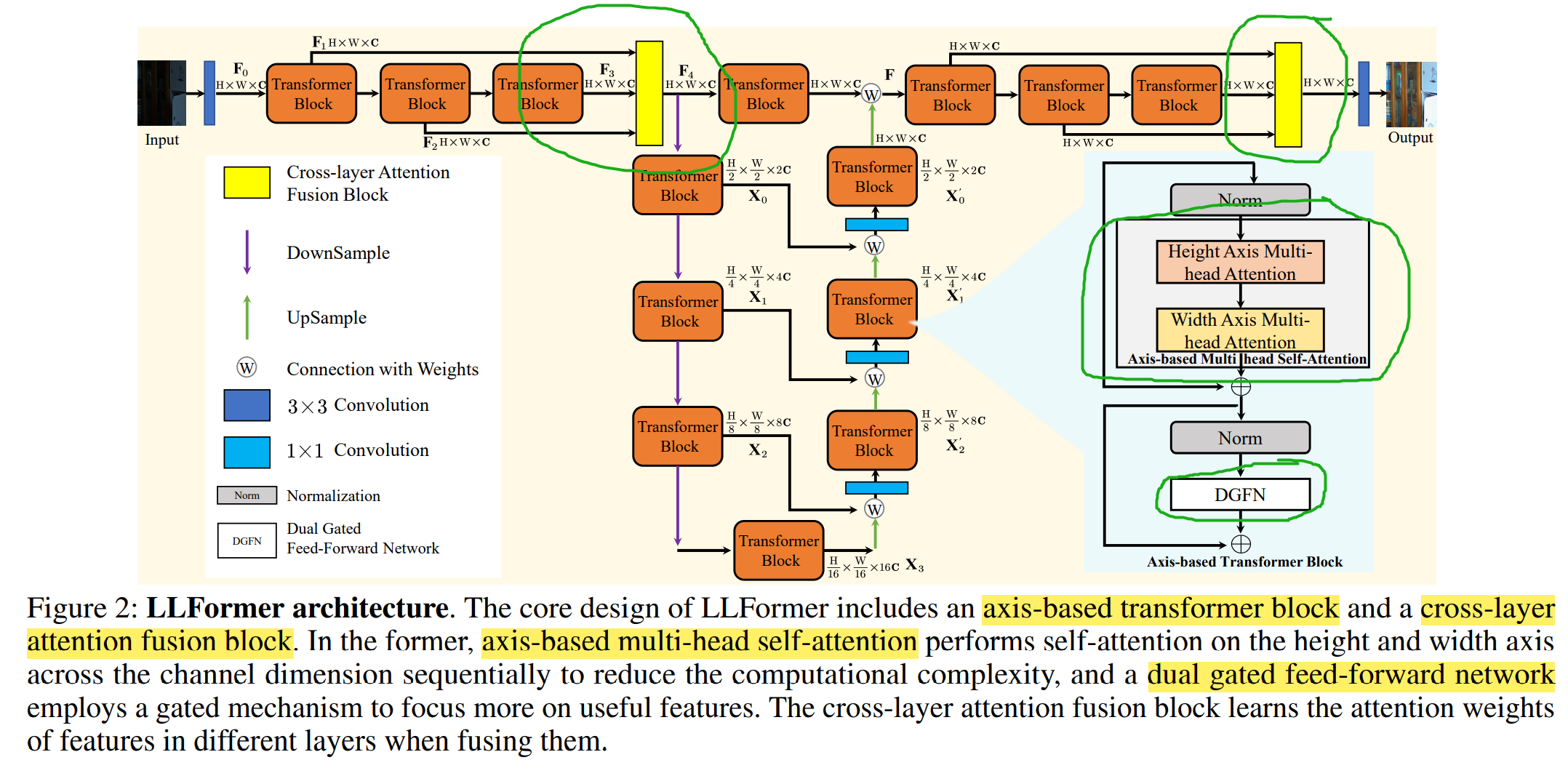
1、Axis-based Transformer Block
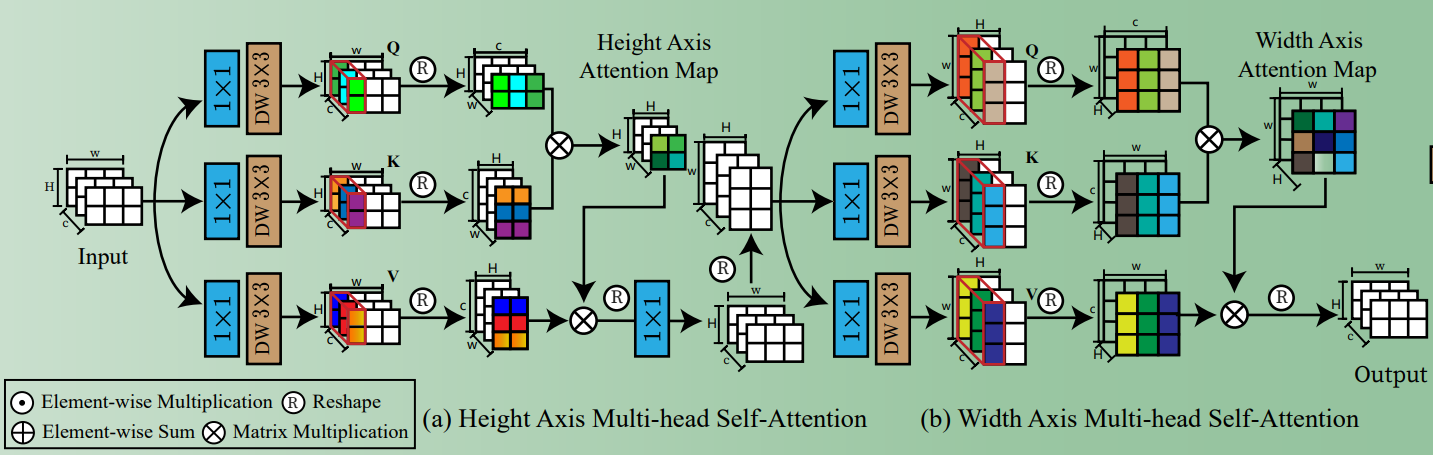
Transformer 在图像修复中应用的难点在于计算复杂度高,在Q和K计算相似性时,对于输入为(C,H,W)的特征需要进行CHWxCHW的矩阵运算。因此,作者分为两个步骤,第一步相似性计算的是HxH,叫做 height-axis attention。第二步相似性计算的是 WxW,叫做 width-axis attention。(这里可以对比 Restormer,只是在C这个维度计算相似性)
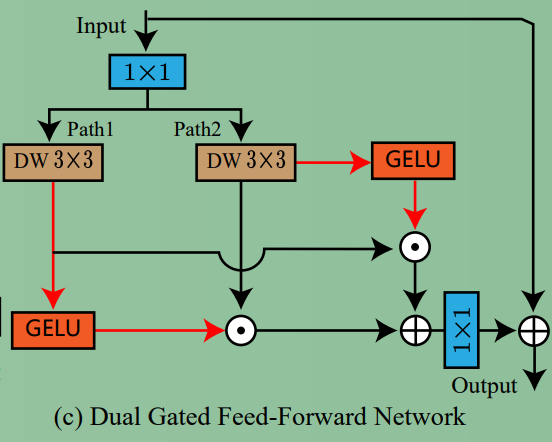
2、Dual Gated Feed-forward Network(GDFN)
在Restormer中,FFN有两个分支,其中有一个分支上使用GELU激活对另一个分支添加门控。在这个论文中,作者给两个分支都使用 GELU 激活,然后互相给另外一个分支添加门控(如下图),这样就进一步增强了FFN的非线性建模能力。
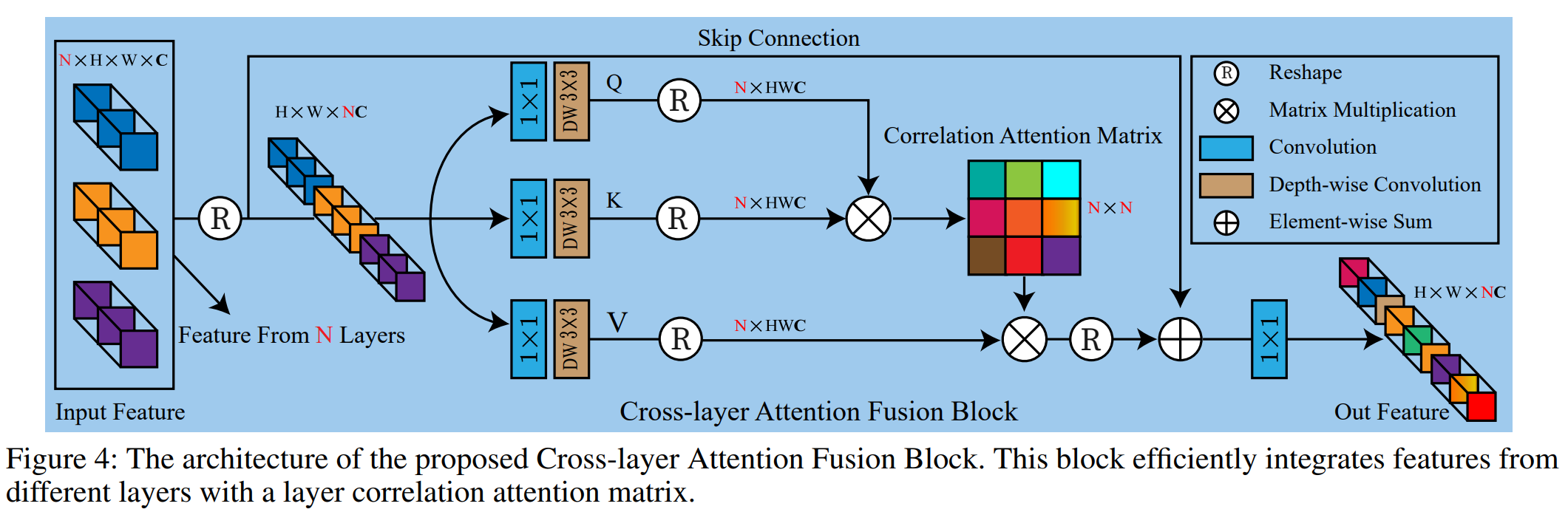
3、Cross-layer Attention Fusion Block
一个网络有很多层,大多方法没有考虑层与层之间特征的关联。从论文整体架构图中可以看到,网络输入有三个Transformer block,这样就有三个特征输出(相当于下图中输入的三组特征,N=3)。作者通过 attention 运算,计算一个3x3的相似性矩阵,给输入的特征进行加权。输入的三组特征里,强调重要的、抑制不重要的。Layer attention 的思路最早应该是在 【ECCV2020】Single Image Super-Resolution via a Holistic Attention Network 这个论文里出现(在任文琦老师报告里听到的)
实验部分可以参考作者论文,这里不再过多介绍。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-01-31 【AAAI2021】EfficientDeRain: Learning Pixel-wise Dilation Filtering for High-Efficiency Single-Image Deraining