【AAAI2023】Head-Free Lightweight Semantic Segmentation with Linear Transformer

论文:【AAAI2023】Head-Free Lightweight Semantic Segmentation with Linear Transformer
代码:https://github.com/dongbo811/AFFormer
这是来自阿里巴巴的工作,作者构建了一个轻量级的Transformer网络用于语义分割,主要有两点创新:1、用prototype representation作为可学习的局部描述代替decoder;2、构造了自适应频率滤波模块提取频率信息。
网络整体架构如下图所示,包括四个阶段,每个阶段包括 prototype learning (PL) 和 Pixel Descriptor (PD)。我的理解是: (1)PL 将 通过 clustering 变为 ,这样可以显著降低计算量(但是 H 和 h 的比例关系,我没有看到,实验里也没有分析)。同时,聚类是在 3x3 的邻域里实现的。接着 输入Adaptive Frequency Transformer 的模块计算得到;(2)PD 是CNN网络,用于将恢复到输入大小。(但是PD的具体细节,论文里没有介绍)
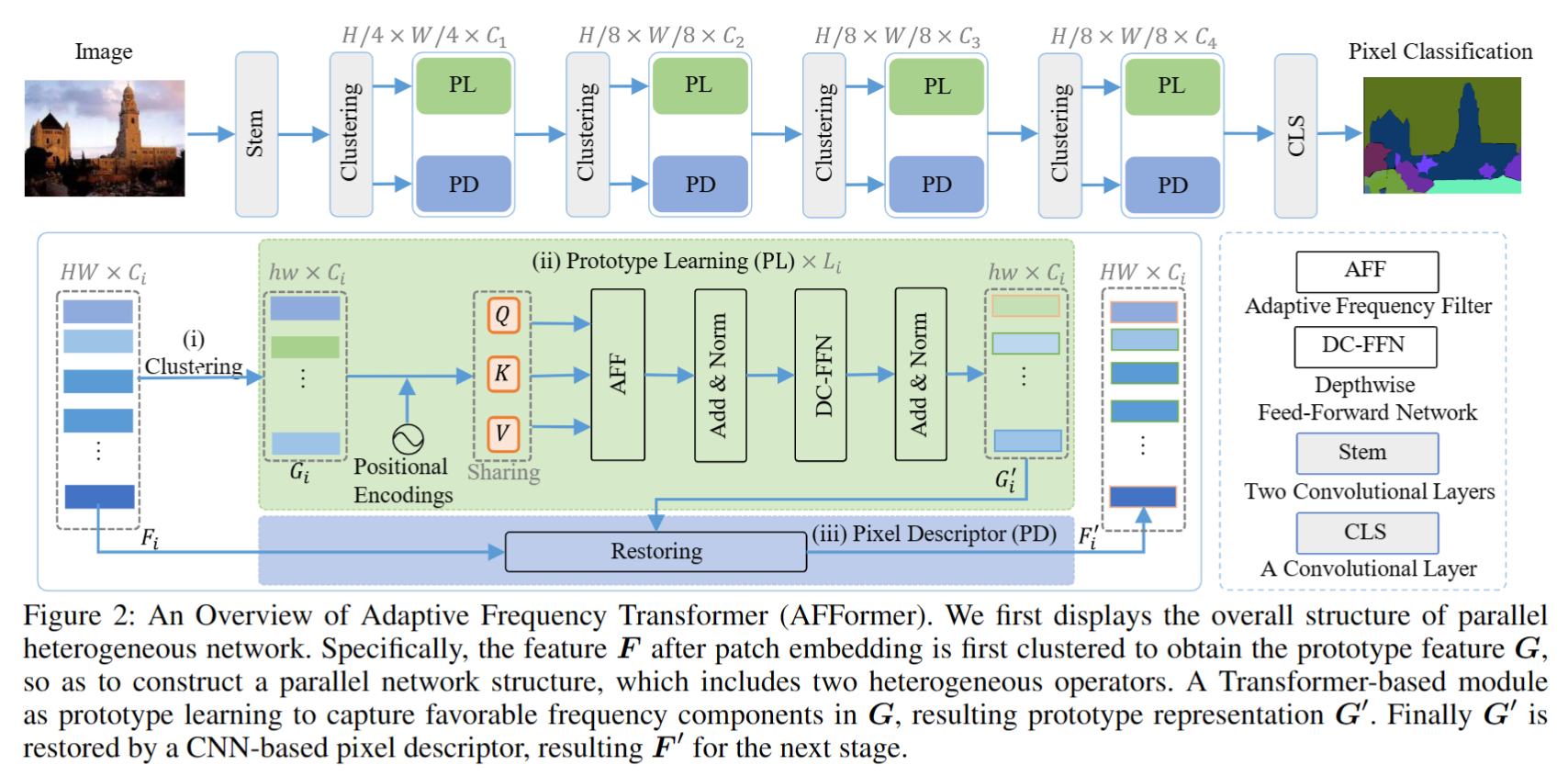
该方法的核心在于Prototype Learning 中的 Adaptive Frequency Filter,结构如下图所示。相当于改变了self-attention 中QKV 的计算方式。有三个分支,计算的结果最后直接相加。
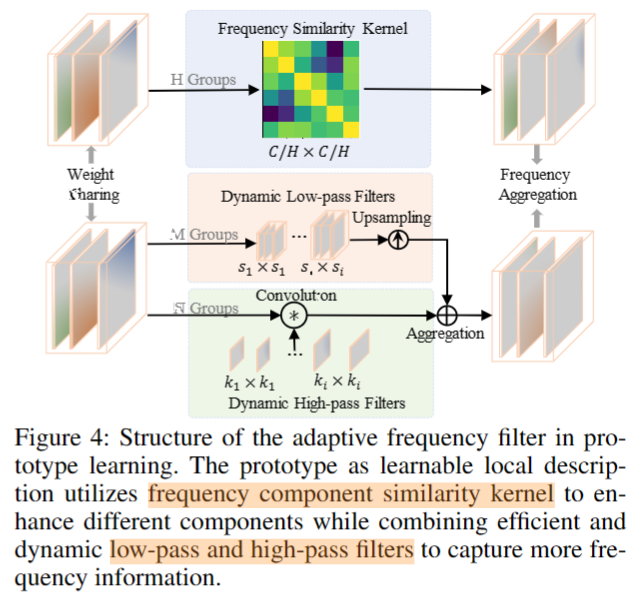
(1)Frequency similarity kernel. 作者描述是计算的 K 和 V 之间的相似性,使用一个 linear layer 对 K 和 V 进行降维,然后应用 Softmax 。(图里描述是分了H个组,相似性矩阵大小为 (C/H)x(C/H),但是H这个参数具体取的多少论文里没有介绍)
(2)Dynamic low-pass filters. 作者应用 average pooling 取代 low-pass filter。将V分为 m 组,每组特征进行均值池化,然后使用 bilinear pooling 进行恢复。(这个地方我有些疑问,这一步没有参数)
(3)Dynamic high-pass filter. 作者将 V 分为 n 组,每组应用 的 depth-wise conv 。同时,作者还将结果与 Q 做 Hadamard 积来抑制高频部分。
最后,三部分计算的结果直接相加,得到AFF模块的最终输出。
实验上,该方法对标的是SegFormer,有明显的性能提升。

个人感觉可以受限于AAAI论文篇幅不能过长,有一些细节需要讨论:
- 有几个参数没有介绍与分析(PL第一步将特征从F转化为G时,下采样的倍率;AFF里面的H、M、N等)
- 题目里的 head-free 应该指的是没有 decoder 吧,因为不专业做语义分割,不是特别清楚




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-01-26 【ECCV 2020】Spatial-Adaptive Network for Single Image Denoising
2021-01-26 【CVPR2020】MMTM: Multimodal Transfer Module for CNN Fusion
2021-01-26 【CVPR2020】Multi-Scale Progressive Fusion Network for Single Image Deraining
2020-01-26 2019秋季软件工程课程思考