【CVPR2022】CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows

【CVPR2022】CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
1、Motivation
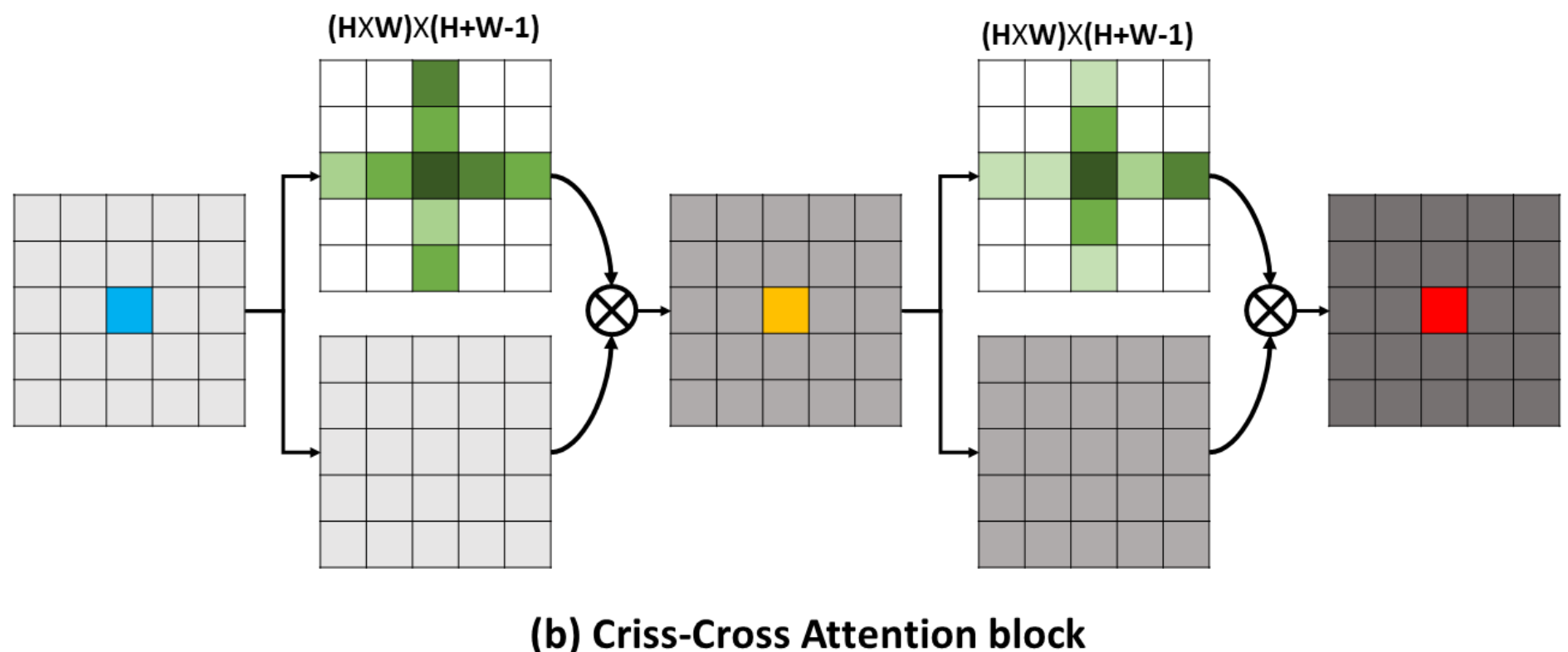
这个论文的想法是受了 CCNet 的启发,CCNet 是认为注意力计算过于复杂,因此提出 criss-cross 的注意力计算方法(如上图所示)。这篇论文中提出的 CSWin 是使用了条状区域来计算 attention ,在网络的不同阶段使用不同宽度的条状区域,在节约计算资源的同时实现了强大的特征建模能力。同时,论文还有一个创新点是提出了Locally Enhanced Positional Encoding,这个创新相对弱一些,后面会介绍。
2、方法介绍
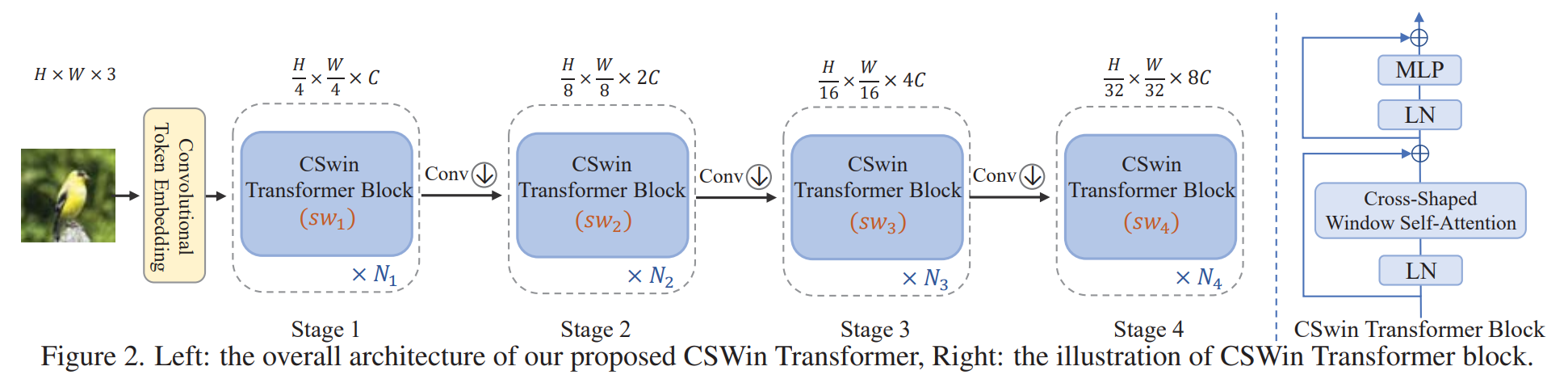
CSWin 总体框架如上图所示,主要是一个四阶段的网络,只是 attention 部分替换为了 cross-shaped window 注意力。
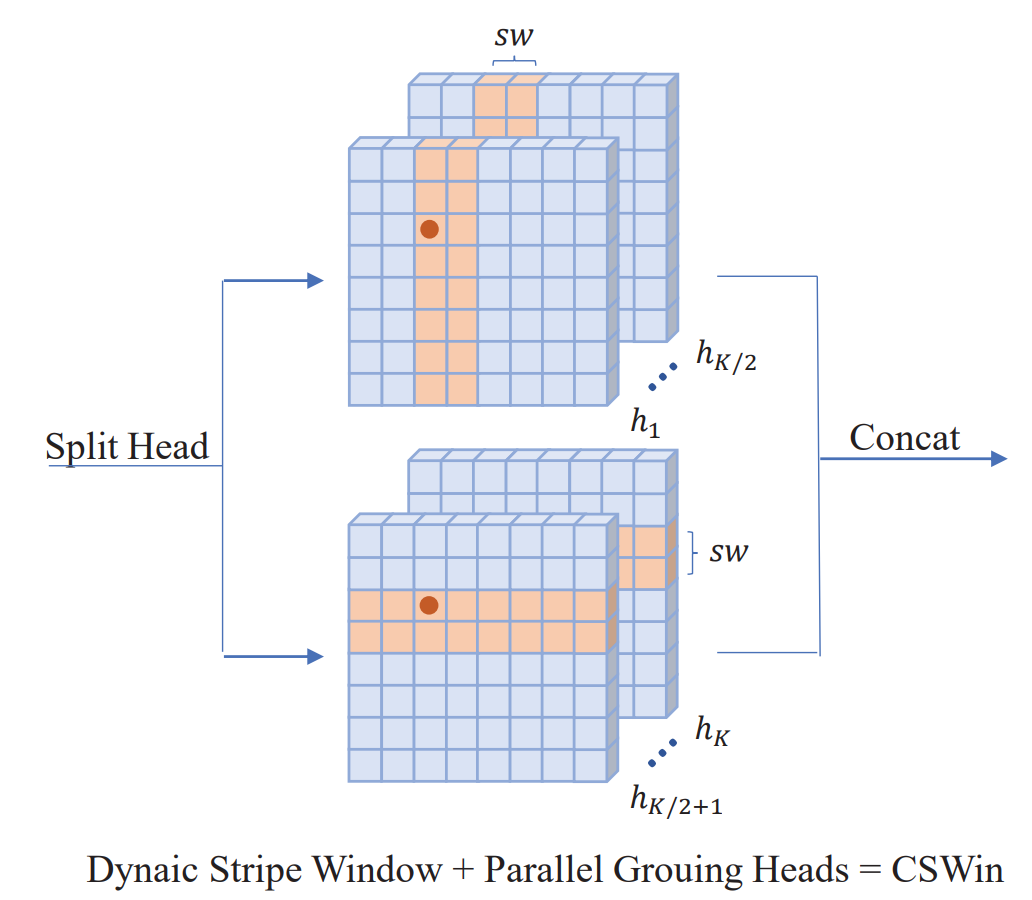
**(1)cross-shaped window self-attention。 ** 在四个阶段中,stripe的宽度依次为[1,2,7,7],可以看出这样设计,一开始感受野较小,后面感受野较大,和之前一些网络的原理也类似,一开始提取纹理等细节特征,后面逐渐抽象到语义。
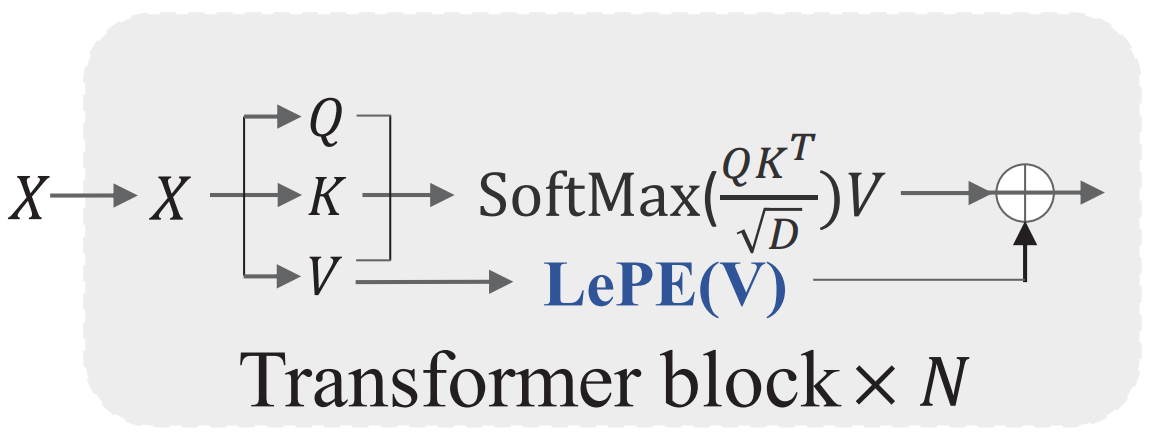
(2)Locally enhanced positional encoding。 个人感觉这个部分的创新较小,因为已经看到很多方法都有类似的操作。如下图所示,就是使用 DWConv 来替换位置编码,然后把这个 DWConv 用残差的形式加在V上。
3、实验分析
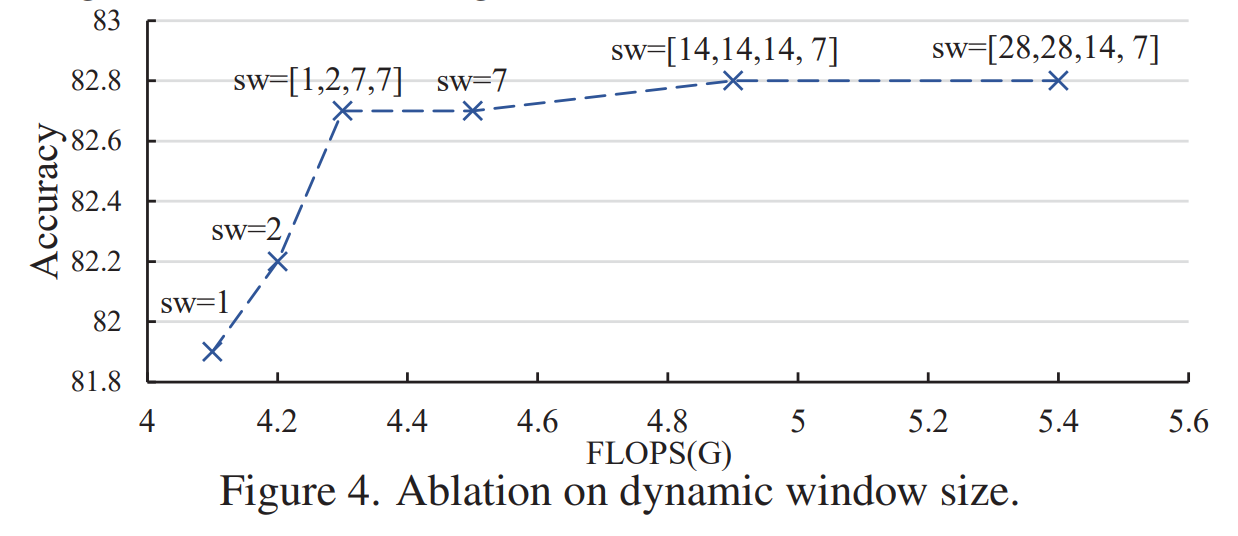
实验部分比较有趣的地方就是 stripe 宽度的实验。可以看到,随着宽度增加,FLOPS会显著增加,默认设置 【1,2,7,7】可以取得较好的平衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号