【CVPR2022】BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
【CVPR2022】BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
BatchFormer的 V1 版本
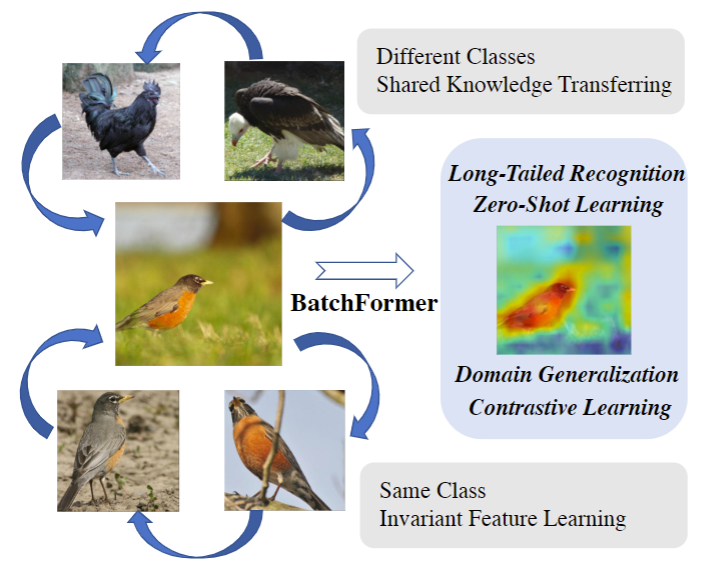
这是一个来自 悉尼大学 和 京东 的工作。为了解决当前样本不平衡、零样本、域适应等问题。如下图所示,中间的是鸟(头部类),下面的是同样的鸟类目标,上面的是不同类的鸡、秃鹫目标(尾部类),这些都是外观极为相似的目标。 因为总体外观相似,把知识从样本数量较多的岛类目标,迁移到样本数量较少的秃鹫,是非常有好处的。(吐槽一下,这个图里秃鹫作为数量较少的尾部类可以理解,但很常见的鸡为啥也作为尾部类不是特别理解)
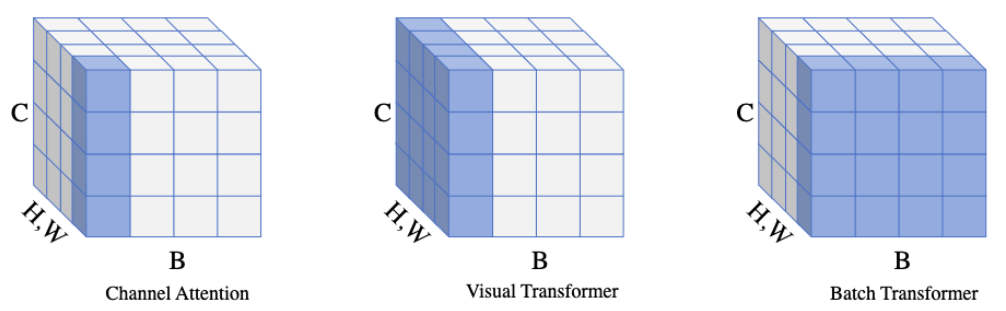
作者提出了一个网络能够从 mini-batch 中学习样本间的关系,叫做 BatchFormer。它可以促进每个 mini-batch 里的样本互相促进学习,比如在样本数量不平衡的长尾识别任务中,利用样本较多的数据促进样本较少类别样本的学习。一个形象的对比图如下所示,Channel attention是在通道上做 attention, VIT 是在空间上做attention,但BatchFormer是在 batch 维度上做 attention。
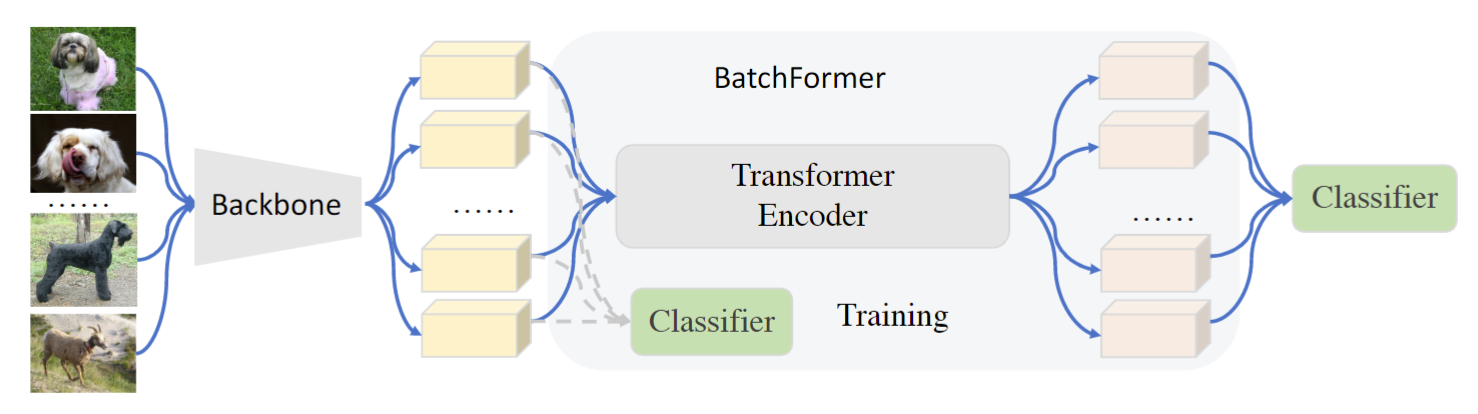
本文提出的特征学习框架如下图所示。特征提取器后面插入 Transformer 。这个Transformer 是沿batch 维度的,把整个 batch 看做一个sequence。同时,在 Transformer 前后都加入了一个分类器。值得注意的是:1)两个分类器是共享的,通过这个共享分类器,能够保持训练和测试的batch不变性。2)Transformer 没有使用位置编码。
def BatchFormer(x, y, encoder, is_training):
# x: input features with the shape [N, C]
# encoder: TransformerEncoderLayer(C,4,C,0.5)
if not is_training:
return x, y
pre_x = x
x = encoder(x.unsqueeze(1)).squeeze(1)
x = torch.cat([pre_x, x], dim=0)
y = torch.cat([y, y], dim=0)
return x, y
BatchFormer 的伪代码如上所示。encoder里包括 MSA和 MLP。\(X\in \R^{N\times C}\)代表输入的特征,N 和 C 分别代表序列长度的特征维度(N就是batch里的样本数),因此,encoder的计算过程为:
作者的代码中,直接使用 torch.nn.TransformerEncoderLayer(48, 1, 48, 0.5) 来实现 encoder。四个参数及其含义依次为:
- d_model – the number of expected features in the input (required).
- nhead – the number of heads in the multiheadattention models (required).
- dim_feedforward – the dimension of the feedforward network model (default=2048).
- dropout – the dropout value (default=0.1).
BatchFormer的输入变为输入的 batch 维度数据,这样自注意力机制就变成不同样本之间的交叉注意力。但是,因为测试数据未知,即样本关系未知,因此BatchFormer前后的特征可能存在差异,所以,不能直接通过移除 BatchFormer 对新的样本进行推断。因此,作者使用了辅助分类器,辅助分类器和最终分类器之间是权重共享的。
BatchFormerV2
作者最近又提出了V2版本的 BatchFormer,将其泛化为一个更通用的模块,来促进一般的目标检测、分割、分类任务。具体来说,将 BatchFormer 插入到两层 Visual Transformer 之间,在每个空间的像素点上面进行Batch Transformer 操作。同时,将每个空间位置上面的 BatchFormer 共享,如下图所示。
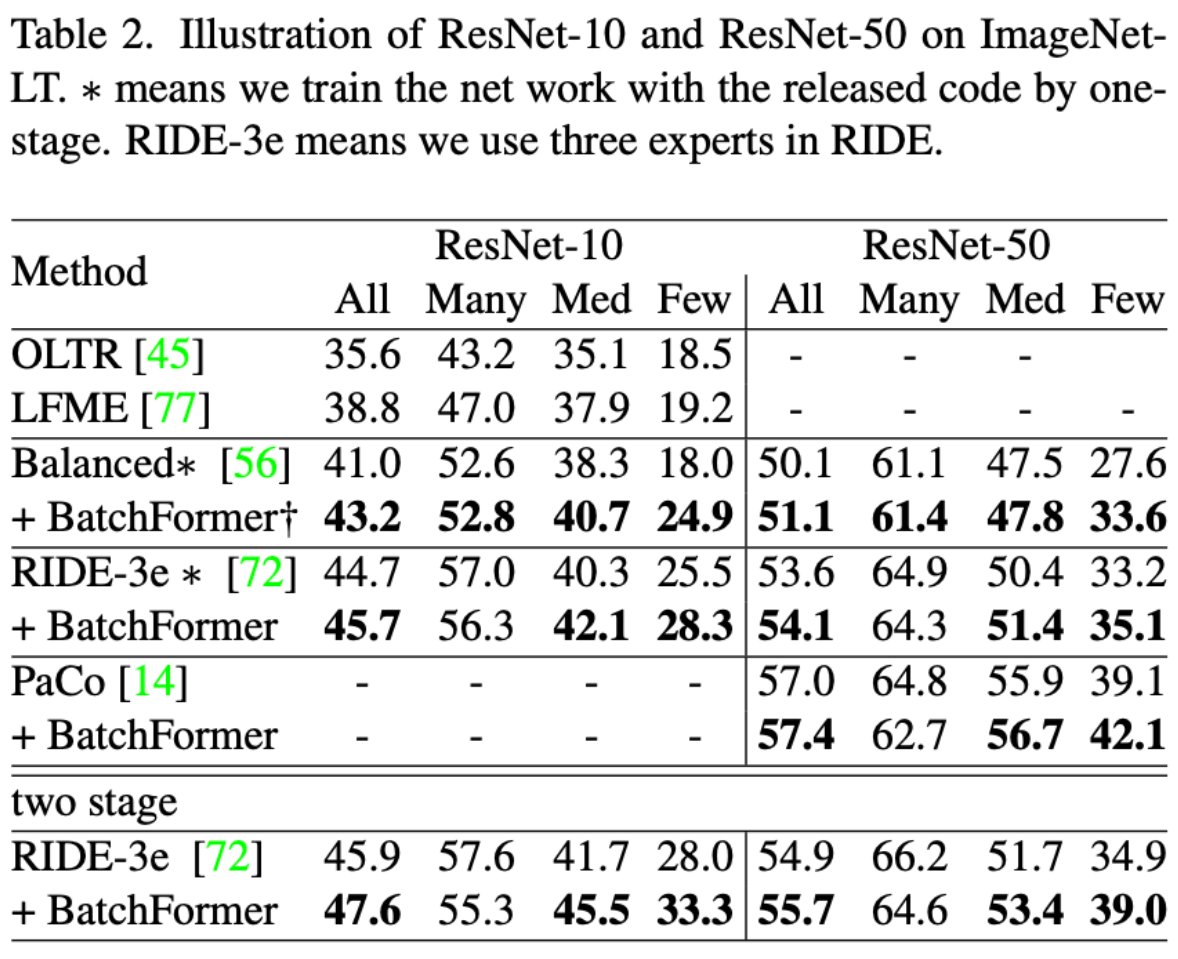
从长尾分类的实验结果上看,BatchFormer 可以显著的提升分类性能。当然,作者还做了很多目标检测、图像分割的实验,这里不过多介绍。