【ECCV2022】OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers

论文:https://arxiv.org/abs/2207.02255
论文中文版:https://dengpingfan.github.io/papers/[2022][ECCV]OSFormer_Chinese.pdf
1、Motivation
伪装物体检测最近比较火,也非常有趣,具体可以参考程明明老师的知乎文章:怎样看待伪装物体检测算法出乎意料的鲁棒性? 下图展示了一个伪装物体检测的示例。这篇论文范登平老师提供了中文版,论文细节可以参考该中文版。
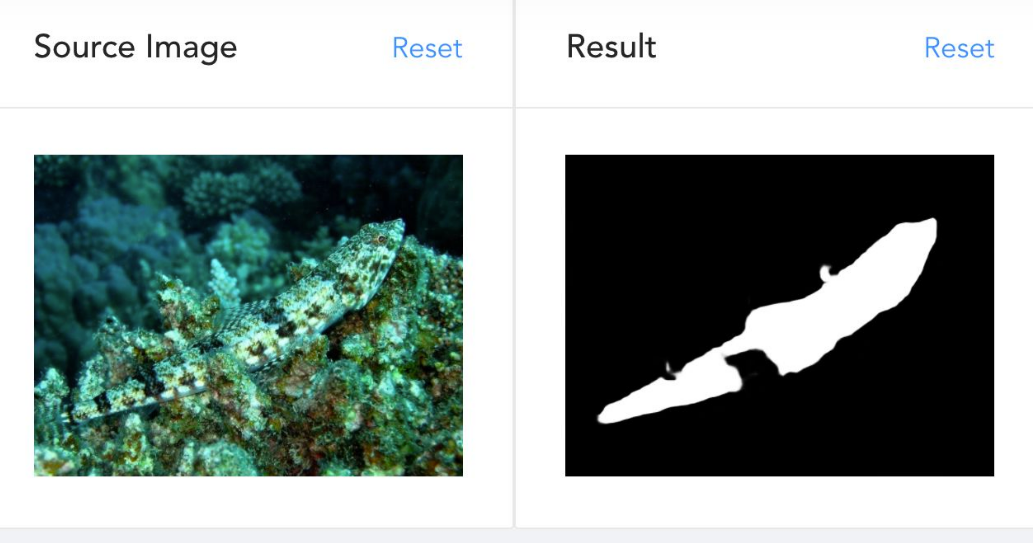
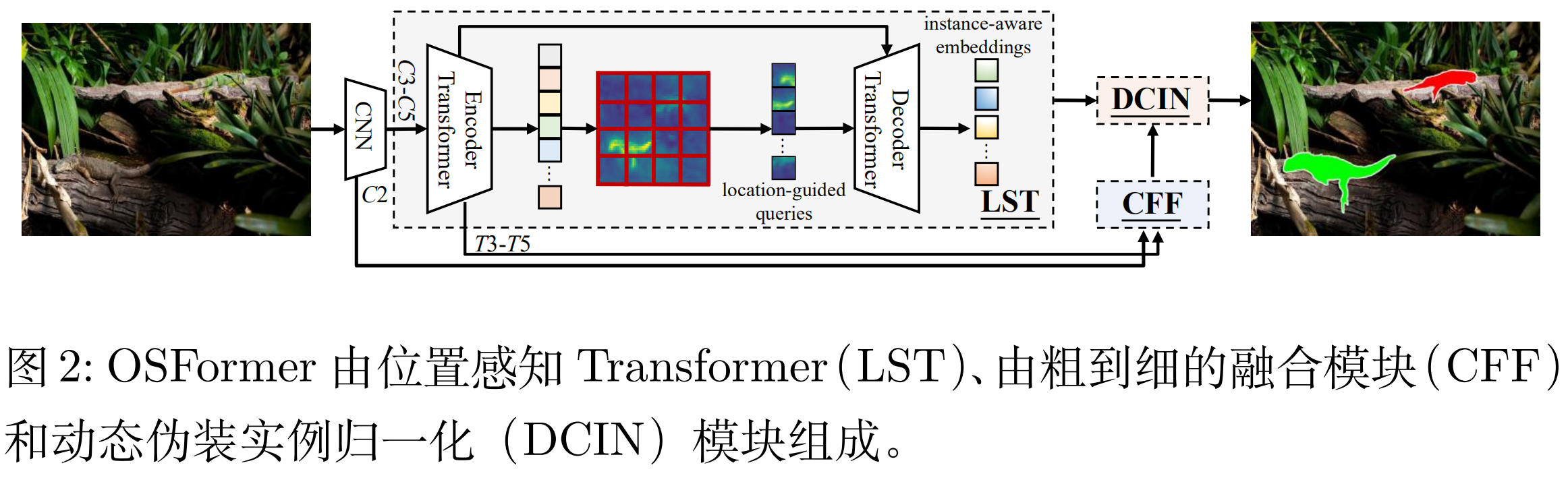
当人类注视一个高度伪装的场景时,视觉系统会本能地在整个场景中寻找有价值的线索。受这种视觉机制的启发,作者提出了OSFormer,该方法在全局中细致地捕捉所有位置的关键信息(即,局部背景),并直接生成伪装实例掩膜(即,单阶段模型),包括两个关键部分:
- 位置感知 Transformer(LST),以动态地捕捉不同位置的实例线索。LST 包含一个带有混合卷积前馈网络(BC-FFN)的编码器来提取多尺度全局特征,以及一个带有位置引导 queries 的解码器来获得实例感知嵌入
- 由粗到细的融合模块(CFF),它通过融合主干网络和LST 的多尺度低级和高级特征来获得高分辨率的掩码特征。在此模块中还嵌入了反向边缘注意力(REA)模块,来突出伪装实例的边缘信息。
OSFormer整体架构如下图所示,下面重点介绍LST, CFF, DCIN 三个部分。
2、 LST (Location-Sensing Transformer)
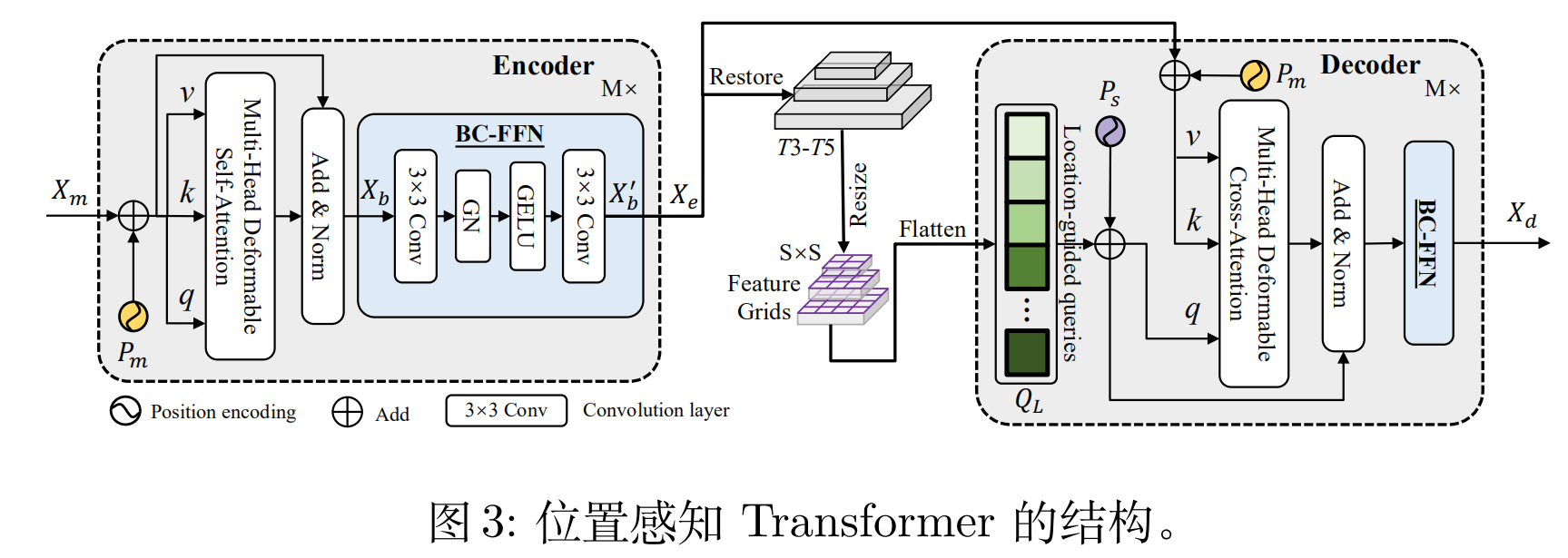
LST结构如上图所示,和 deformable DETR 【1】类似,不同的地方有两处:1、在 FFN 中,加入两个卷积层,目的是“更好的捕捉局部信息并复习课件相邻 token 之间的相关性。” 2、利用编码器的多尺度特征图进行位置引导,这样提高了 query 迭代的效率,加速了收敛。
3、Coarse-to-Fine Fusion (CFF)
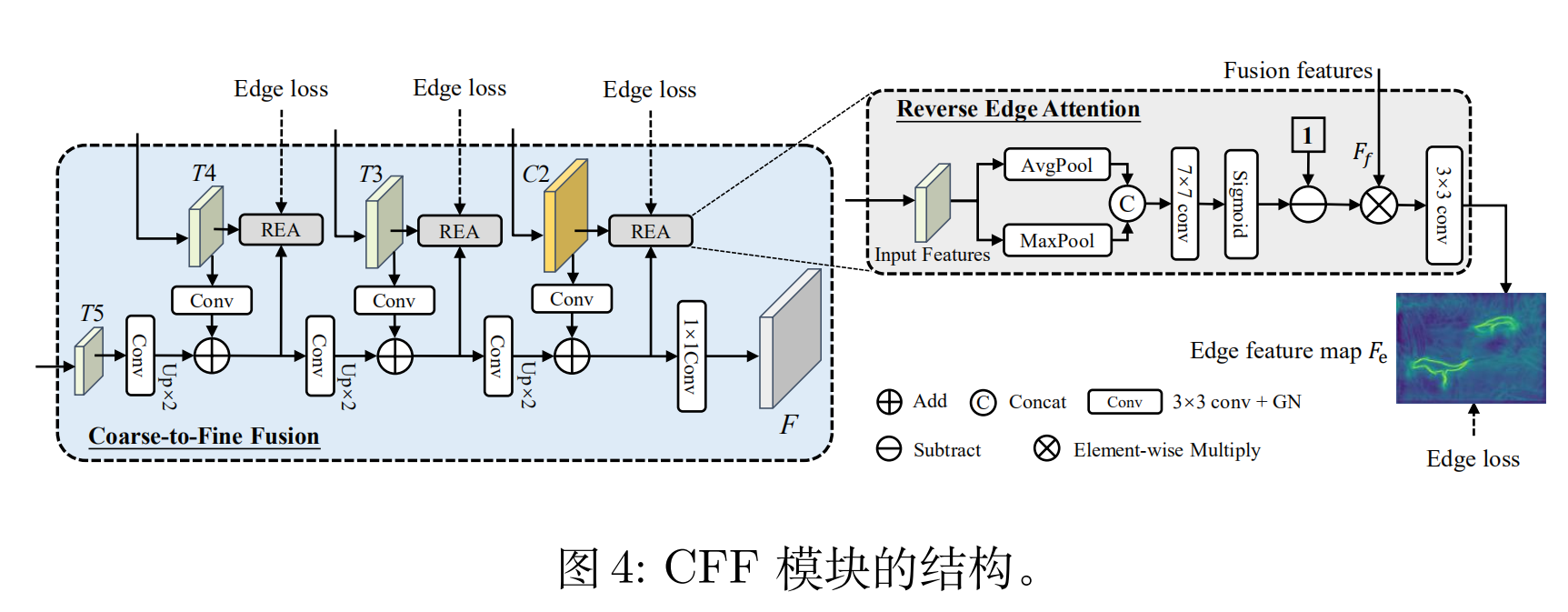
CFF模块结构如上图所示,之前的特征C2、T3、T4、T5 作为级联融合的输入,不断融合。作者还设计了一个 Reverse Edge Attention (REA)模块,用于捕捉边缘特征,其结构在图中有详细说明。
4、Dynamic Camouflaged Instance Normalization (DCIN)
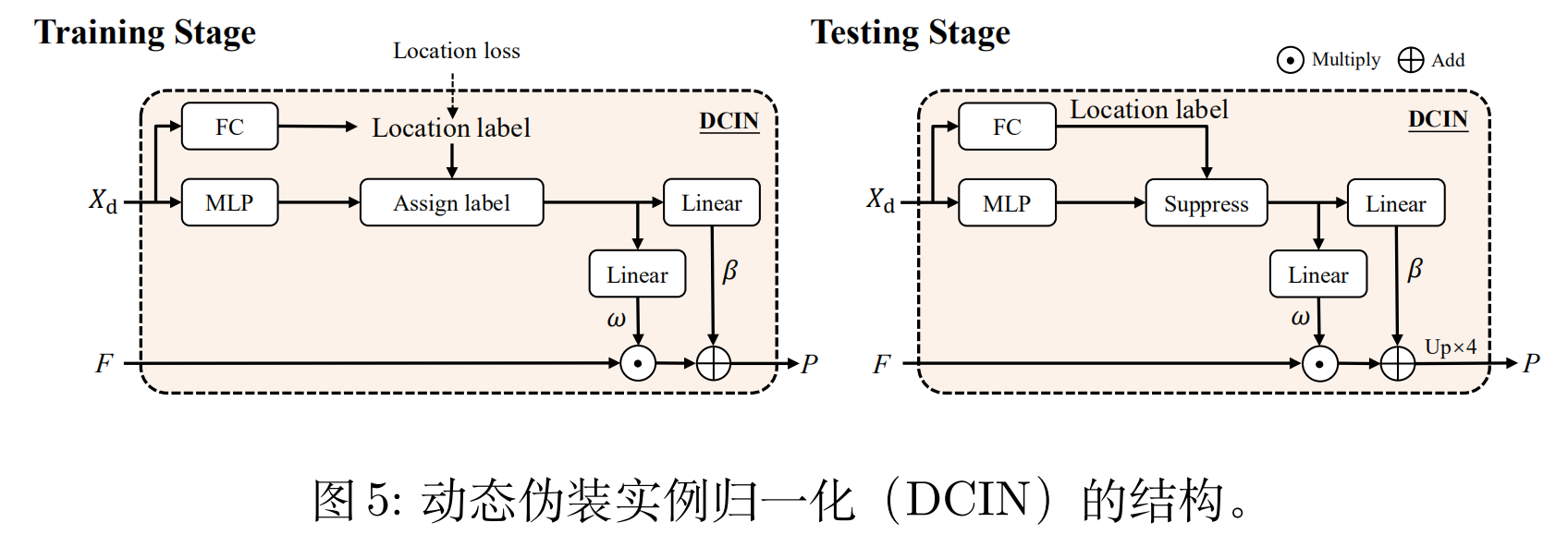
受 AdaIN 【2】的启发, 作者设计了 DCIN 来预测最终的 mask,结构如上图所示。作者采用了动态网络的思路,训练阶段 FC 层可以生成 location label。在测试阶段,使用 threshold > 0.5 过滤效的参数。随后,采用 AdaIN 获得仿射权重和偏置。最后,与CFF的输出结合得到结果。
实验部分可以参考作者的论文,这里不过多介绍。
参考文献
【1】Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable DETR: Deformable transformers for end-to-end object detection. In: ICLR (2020)
【2】Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: IEEE ICCV (2017)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界
2021-08-06 【ARXIV2104】Attention in Attention Network for Image Super-Resolution