【ARXIV2204】Simple Baselines for Image Restoration

**向孙老师致敬 ~~~ **
【ARXIV2204】Simple Baselines for Image Restoration
代码:https://github.com/megvii-research/NAFNet
论文:https://arxiv.org/abs/2204.0467
感谢知乎网友 Kester 的分享,这里用了很多他的观点
最近Transformer模型开始在图像修复领域兴起,模型的复杂度也随之上升。在这篇论文里,作者提出一个计算高效的 simple baseline 达到 SOTA 效果。
作者首先分析了当前的图像修复模型的复杂度,主要包括:inter-block 和 intra-block 。
inter-block 指的是各个模块之间的关系,包括:multi-stage, multi-scale fusion, UNet 三种结构。作者认为:宏观结构不是影响算法效果的关键(we believe the architecture will not be a barrier to performance)。为此,在本文中,作者采用了 UNet 结构,并把精力集中在到 intra-block 的改造上。
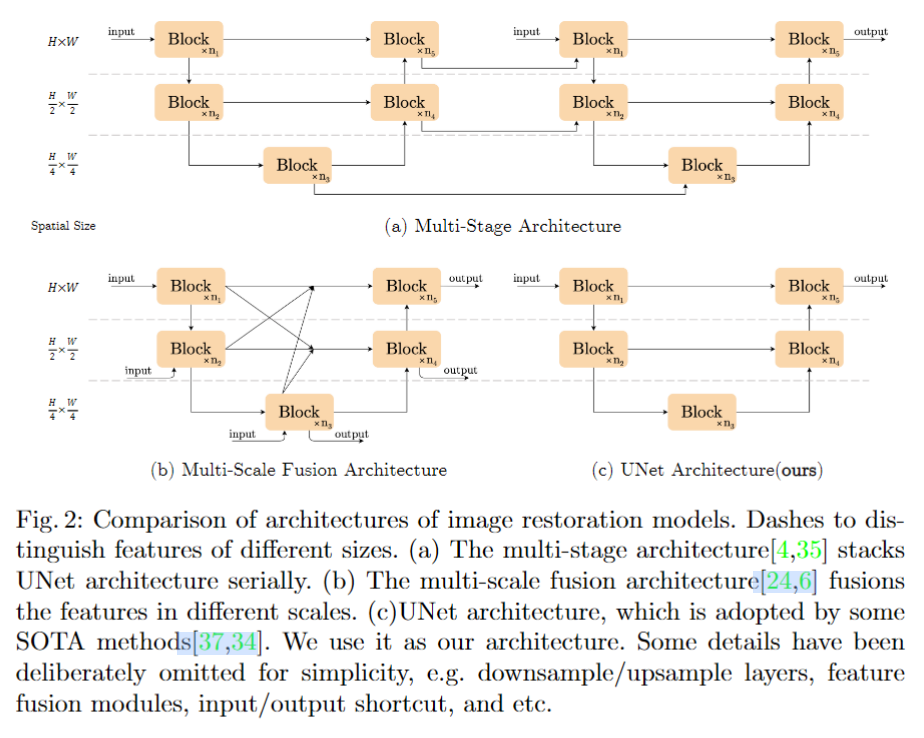
对于 intra-block 的改进,包括三方面:
- 归一化方面,作者采用了 LayerNorm。文章采用了Transformer里被通常采用的LayerNorm,并通过实验发现其能提点。其实传统意义上,除了早期的方法,底层视觉一般是不太会增加归一化层,认为其会降点而且让图像模糊。这和BatchNorm的特性有关,一方面BatchNorm本身训练测试阶段由于统计量不同,就会导致领域不适应问题。另外不同于high-level task倾向于寻找一致性表示,底层视觉的任务与之相反,往往是倾向于学习图片特定性以增强细节的恢复效果, batchNorm由于是batch内做attention,其实很容易将其他图片的信息引入,忽略了恢复图像的特定信息,导致性能下降。 所以之前底层视觉里面用的比较多的norm是instance Norm(比较多的是在风格迁移),因为只关注同一个图片同一channel内的信息,所以某种意义上避免了平滑,layerNorm关注整幅图,也没有超过单张的范围,所以能够work还是蛮make sense的。
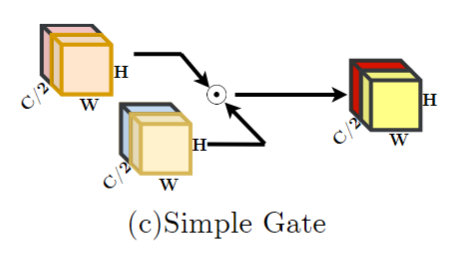
- 激活函数,作者构建了 SimpleGate。 首先作者回顾了GLU,然后给出推导认为 GELU 是 GLU 的一种特殊形式。GLU的计算量主要来自于 sigmoid 和 映射函数,因此作者删除了 sigmoid,同时映射函数也删除了。具体操作如下:对特征进行 channel-split,分成两个C/2个通道的特征,并相乘,如下图所示。 由于这个简化的simple gate引入了非线性,所以常用的ReLU自然也不需要再加入到网络中了,这也就是为什么这篇文章提出的方法叫做 Nonlinear Activation Free Network 。
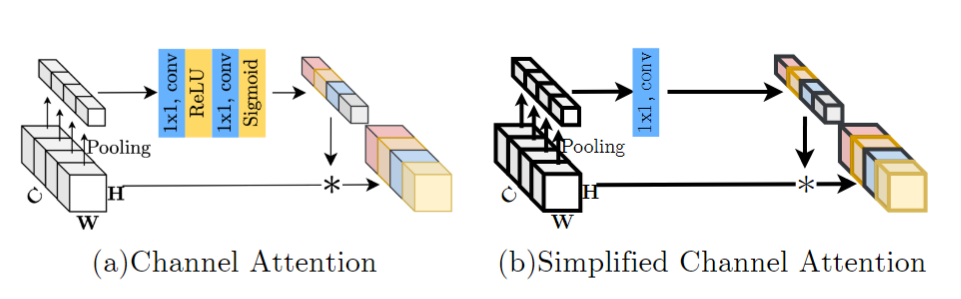
- attention,上述的simple Gate操作虽然可以有效减少计算量,但是作者认为channel-wise的操作丢失了,所以在后面的attention上,作者使用了简化的channel attention,减少计算量的同时引入channel的交互,如下图所示。
作者最终提出了下面的模型,如下图中(d)所示。
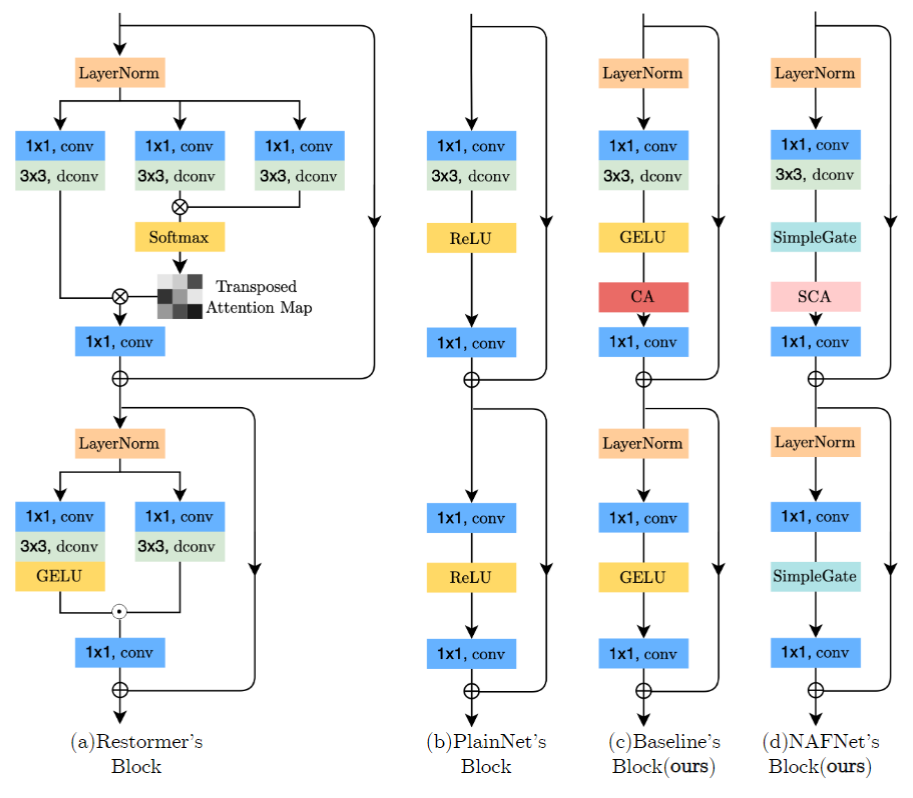
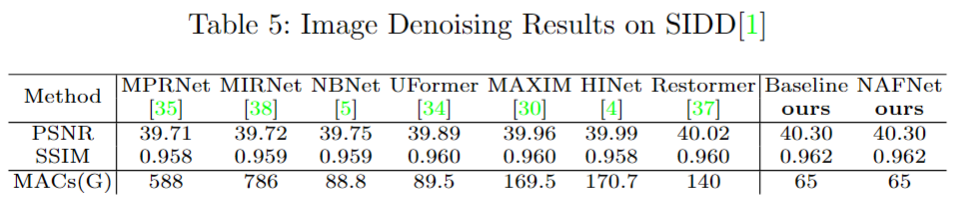
从图去噪的实验结果来看,MACs 值显著降低的情况下,显著提升了效果。
最近很多工作将 Transformer 用于图像修复任务,大家都集中于研究 MHSA 是不是用于图像修复里效果会更好。但是这个论文只使用一些简单的操作就取得了非常好的效果。也让人感觉,Transformer 在图像修复任务中的成功是利益于一些 trick 的结果。

