【ARXIV2204】Neighborhood attention transformer

感谢B站“秋刀鱼的炼丹工坊” 的讲解,这里的解析结合了很多多的讲解。
论文:https://arxiv.org/abs/2204.07143
代码:https://github.com/SHI-Labs/Neighborhood-Attention-Transformer
这个论文非常简单,思想其实在之前的论文里也出现过。首先看下面这个图,标准VIT的 attention 计算是全局的,像第一图中红色的 token 和蓝色的 token 会全局的和所有的 token 进行计算。swin 是中间的两个图,第一步 token 的特征交互限制在局部窗口内。第二步窗口有shift,但 token 的特征交互仍然在局部的窗口内。最后一个图就是这个论文提出的 neighborhood attention transformer, NAT,所有 attention 的计算在 7X7 的邻域里进行。看起来和 convolution 一样,只是在一个 kernel 里面的范围内去做操作。但是和 convolution 不同的是,NAT里面是计算 attention,所以每一个 value 出来的权重是根据输入的这个值来决定的,而不是像卷积核里面那样训练好就固定的一个值。

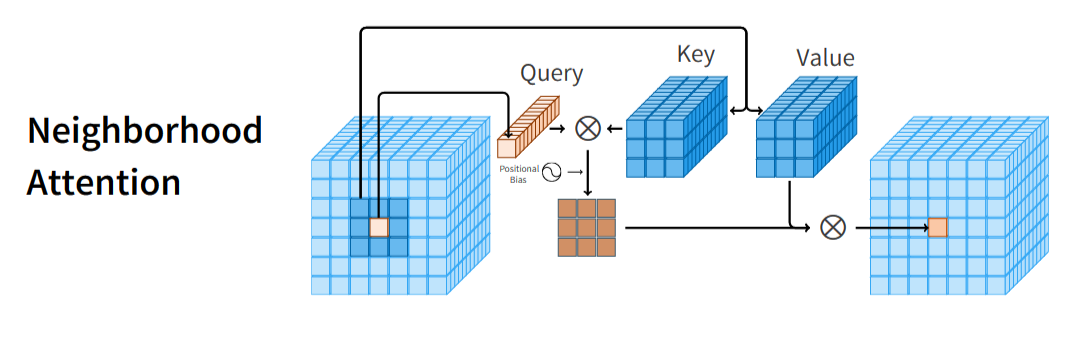
作者还给出了 attention 计算的图示。如下图所示,对于CHW的输入矩阵,Query 是某个位置一个 1XC的向量, key 是一个 3x3xC 的矩阵,两个矩阵逐元素相乘(尺寸不同进行 broadcast ),结果是 3x3xC,最后在 C 这个维度求和,得到3X3的相似度矩阵。用这个矩阵给 value 分配权重 ,最后合并为一个 1x1xC 的向量,就是 attention 的计算结果。
作者还进行了计算复杂度的分析,可以看出,因为在局部邻域里计算注意力,计复杂度大大降低,和 swin 是基本一致的。

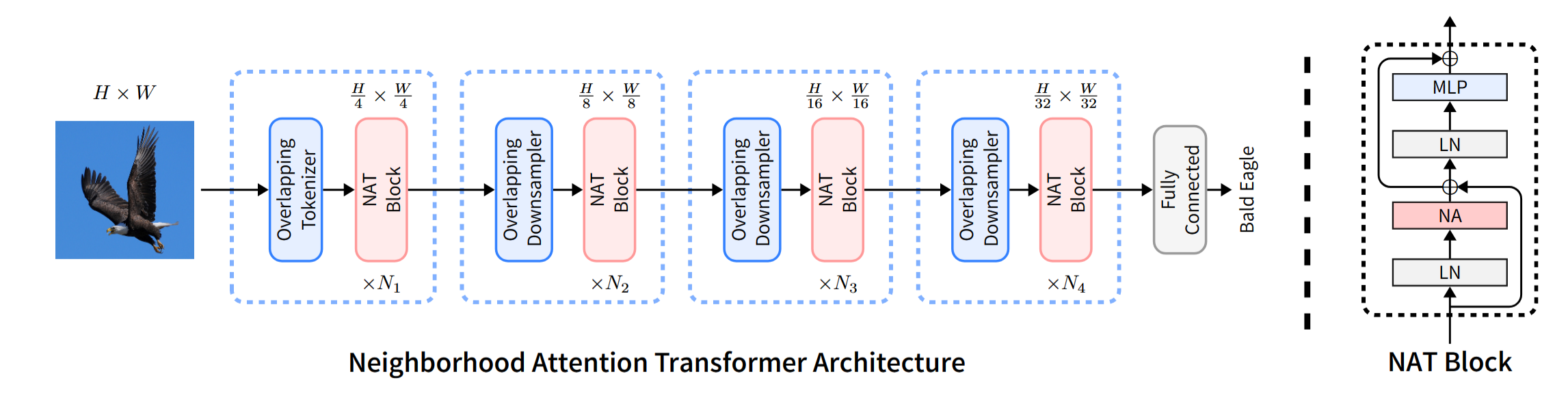
网络的整体架构和当前方法一样,都是4阶段。每个阶段分辨率降低一半。不过,降分辨率使用的是 步长为2的 3X3 卷积。第一步 overlapping tokenizer 使用的是2个3x3卷积,每个卷积的步长为2。
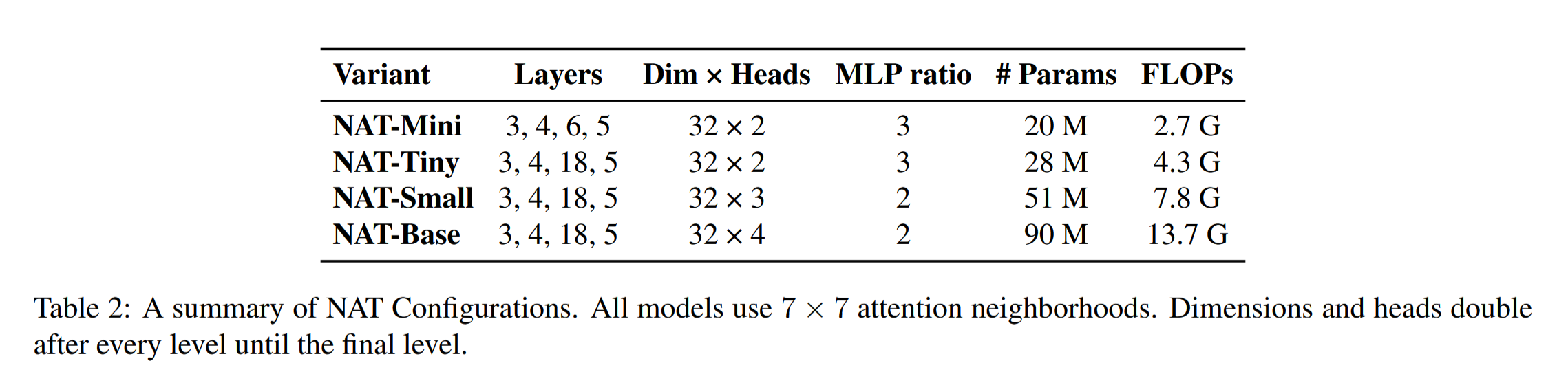
作者设计了4种网络结构,邻域大小都是7X7,具体如下:
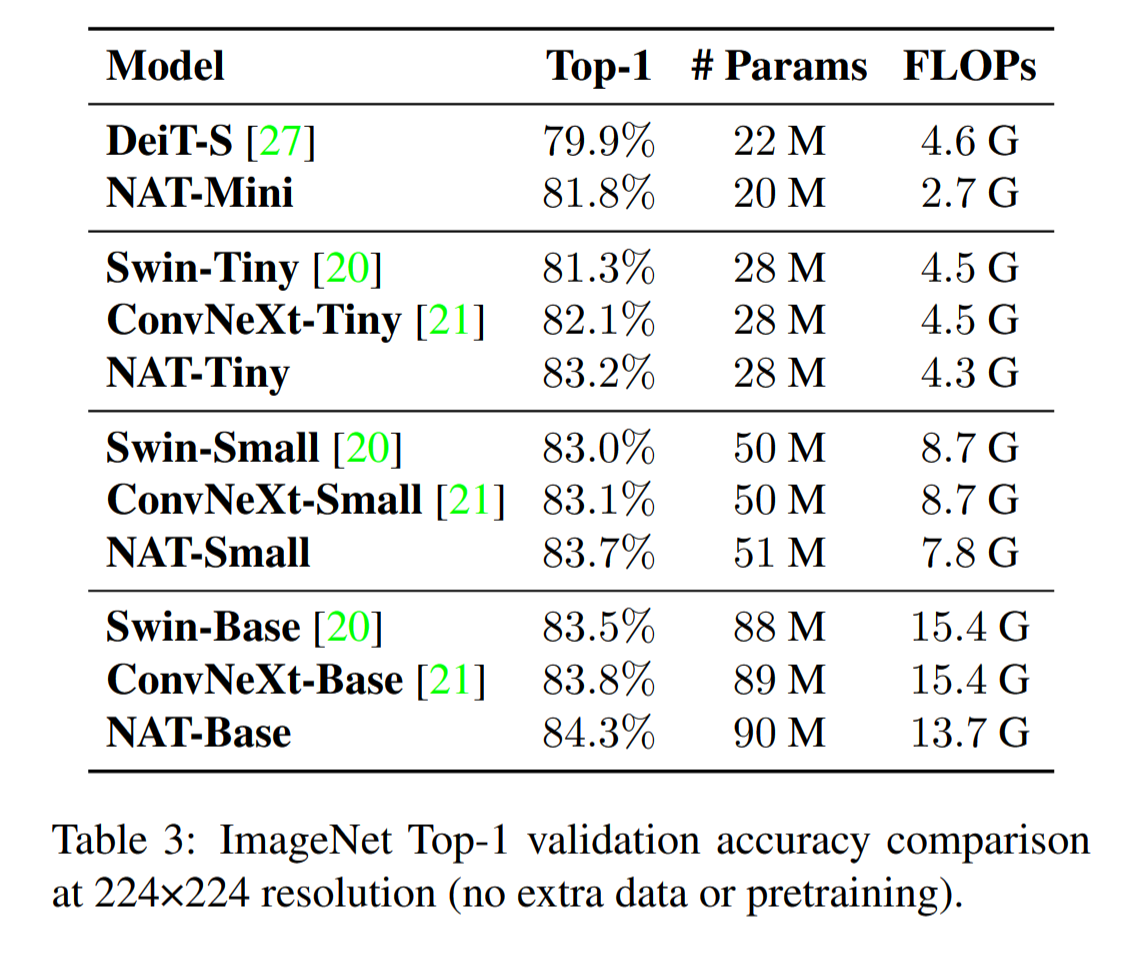
在图像分类任务上,NAT取得了非常好的性能,如下表所示:
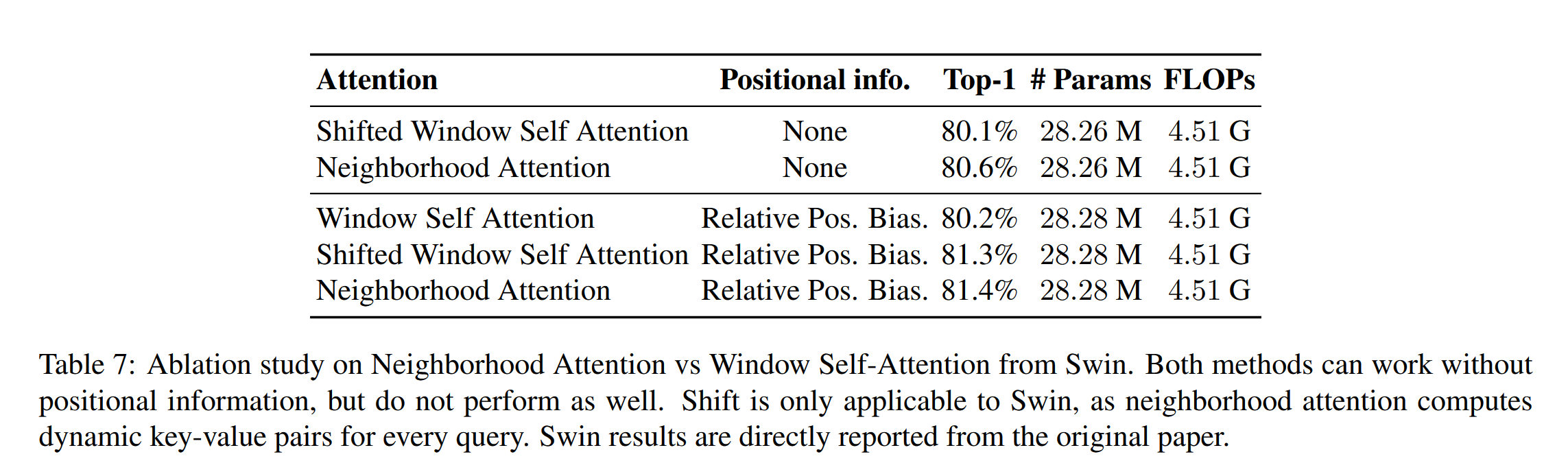
在 Ablation study 里面,作者对比了 postion embedding 和 attention 计算的性能差别。不过,作者模型是 81.4% ,和上面表格里的 83.2 有差异,不清楚是什么原因。
总的来说,这个论文思想非常简单,之前很多论文也体现过这个想法。但这个论文是和企业联合做的,难点应该在于 CUDA 硬件实现上,作者写了大量的CUDA代码来对 neighborhood 操作进行加速。

