【ARXIV2204】Vision Transformers for Single Image Dehazing

1、研究动机
作者提出了 DehazeFormer 用于图像去雾,灵感来自Swin Transformer ,论文中有趣的地方在于 reflection padding 和 注意力的计算
2、主要方法
该方法框架如下图所示,是一个5阶段的UNET结构,卷积块被DehazeFormer block取代。
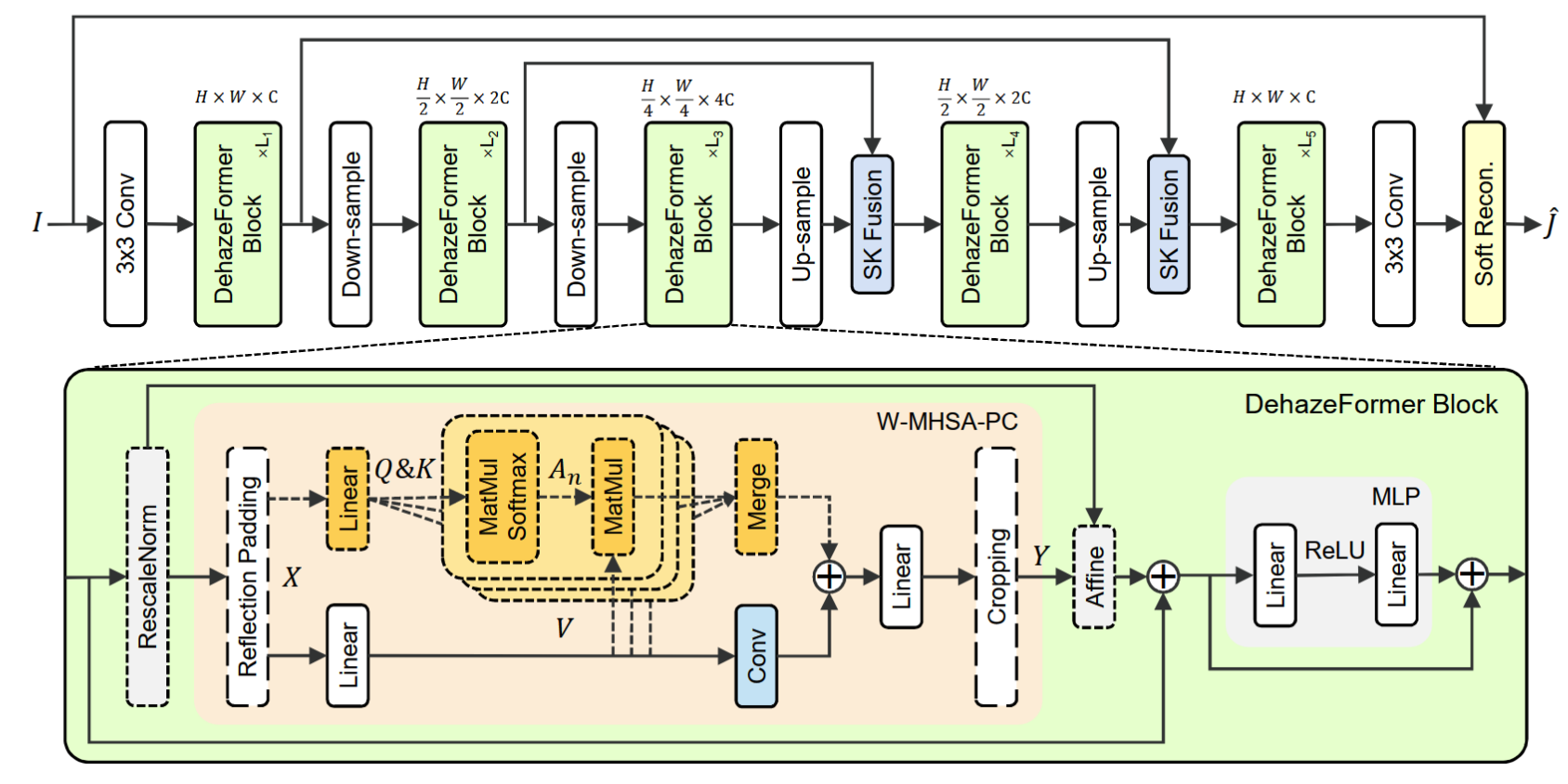
Reflection padding
在SWIN中,使用shfited window来实现窗口间信息的交互,但是作者认为这种操作对于图像边缘区域并不友好。对于分类任务来说,目标区域总是位于图像中间,因此使用 shift window是没有问题的,但是对于图像修复任务来说,边缘区域是同样重要的,这样的操作就不合适了。为此,作者提出了 reflection padding 操作,如下图所示。
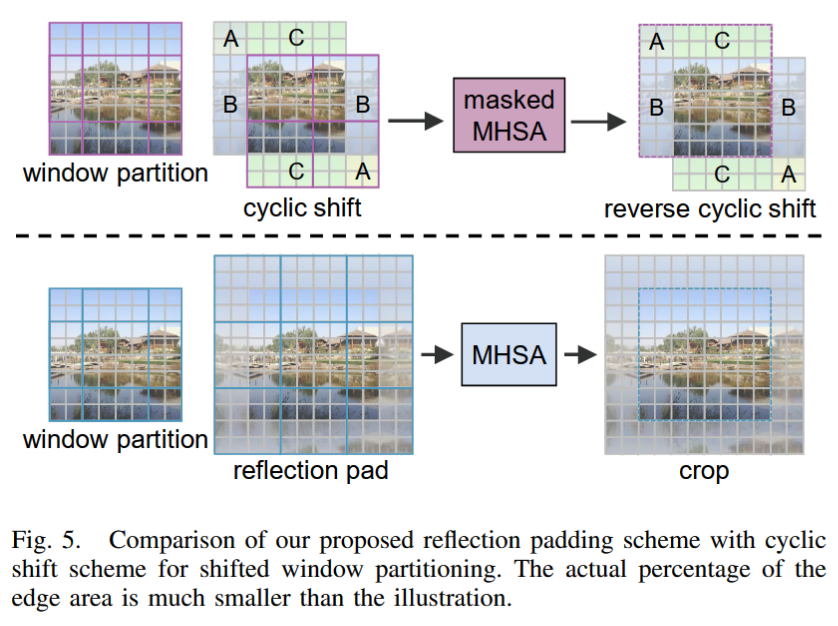
输入图像尺寸是8x8,图中的 window 是 4x4 的,这样对于边缘区域复制2个patch,图像大小就成为12x12,这样就可以变成3x3=9个window。在这9个window里计算局部attention,计算结束后,把中间8x8的区域切出来即可。
作者也指出,这样的操作会引起计算和内存资源的消耗。
W-MHSA with parallel convolution
作者认为由于MHSA的聚集权重是动态的和归一化的,作者认为静态的、可学习的和无约束的聚集权重有助于补充MHSA。因此作者对V进行了额外的卷积。在论文的整体架构图中也能看到 V后面一个卷积层,与 attention 的计算结果做加法。
实验部分可以参照作者论文,这里不过多介绍。

