【CVPR2022】Lite Vision Transformer with Enhanced Self-Attention

1、研究动机
尽管ViT模型在各种视觉任务中效果显著,但是目前轻量级的ViT模型在局部区域效果不理想,作者认为:自注意力机制在浅层网络有局限性(Self-attention mechanism is limited in shallower and thinner networks)。为此,作者提出一种 light yet effective vision transformer 可以应用于移动设备(Lite Vision Transformer, LVT),具有标准的 four-stage 结构,但是和 MobileNetV2 和 PVTv2-B0 含有相同的参数量。 作者主要提出了两种新的 attention 模块:Convolutional Self-Attention (CSA) 和 Recursive Atrous Self-Attention (RASA) 。下面分别介绍 CSA 模块和 RASA 模块。
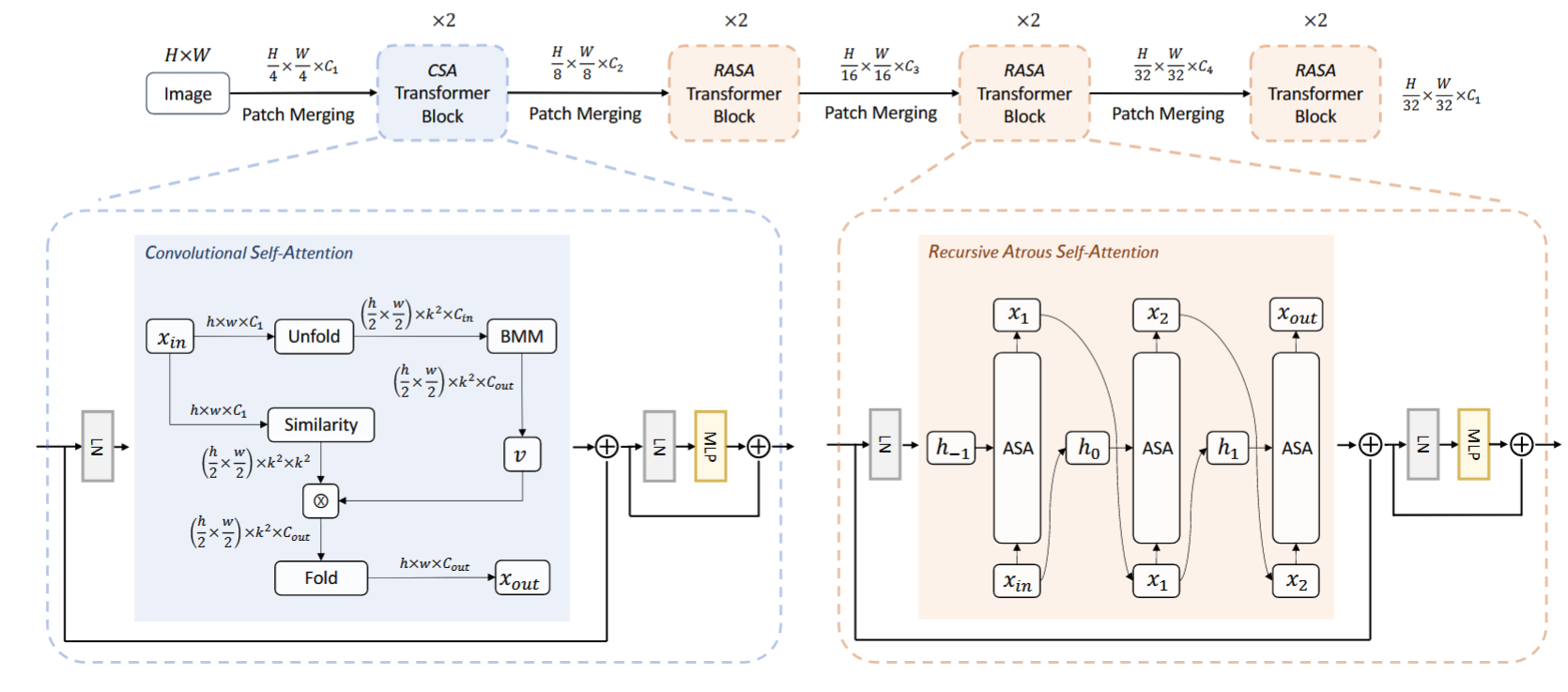
2、Convolutional Self-Attention (CSA)
流程如上图所示,基本流程是:
- 计算similarity(即代码中的attn): 将 (hw/4, c) 的矩阵通过1x1卷积变为 (hw/4, k^2, k^2)。
- 计算V: 生成一个(hw/4, c, k^2)的矩阵,然后reshape通过1x1的卷积改变通道数(图中为BMM),得到(hw/4, k^2, c_out)的矩阵。
- 矩阵乘法,similarity 和 v 相乘,得到 (hw/4, k^2, c_out)
- 使用 fold 变换得到输出
从代码上来看,CSA 的代码比 VOLO 更复杂,但本质上貌似没有不同(也许是我的理解还不到位)。而且,我感觉 CSA 的代码没有 VOLO 简洁。感兴趣的可以参考《VOLO: Vision Outlooker for Visual Recognition》这篇论文及网上代码。
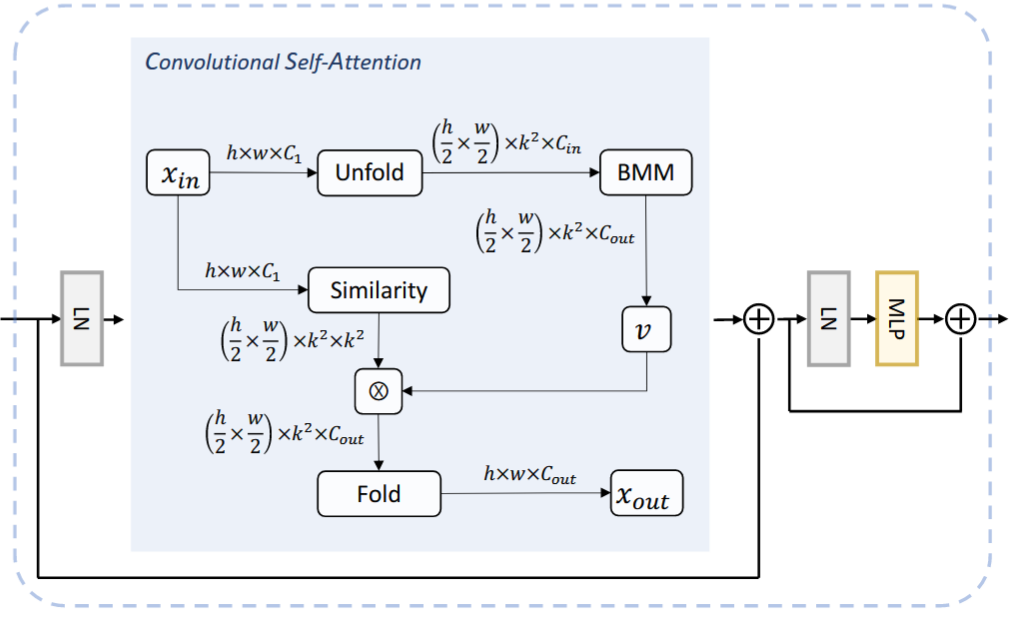
3、Recursive Atrous Self-Attention (RASA)
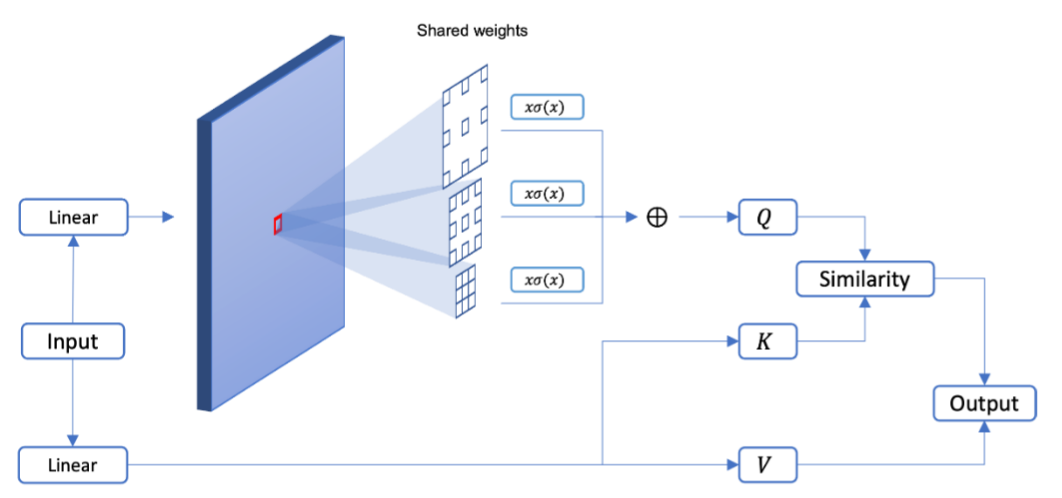
首先介绍 ASA,与普通的attention计算不同的地方在于:作者在计算Q时,采用了多尺度空洞卷积。卷积权重共享,降低了参数。
同时,作者使用了 recursive 操作。每个block里,ASA 迭代两次。
4、实验分析
网络采用了4阶段的架构。第一阶段使用CSA,其他阶段使用RASA。
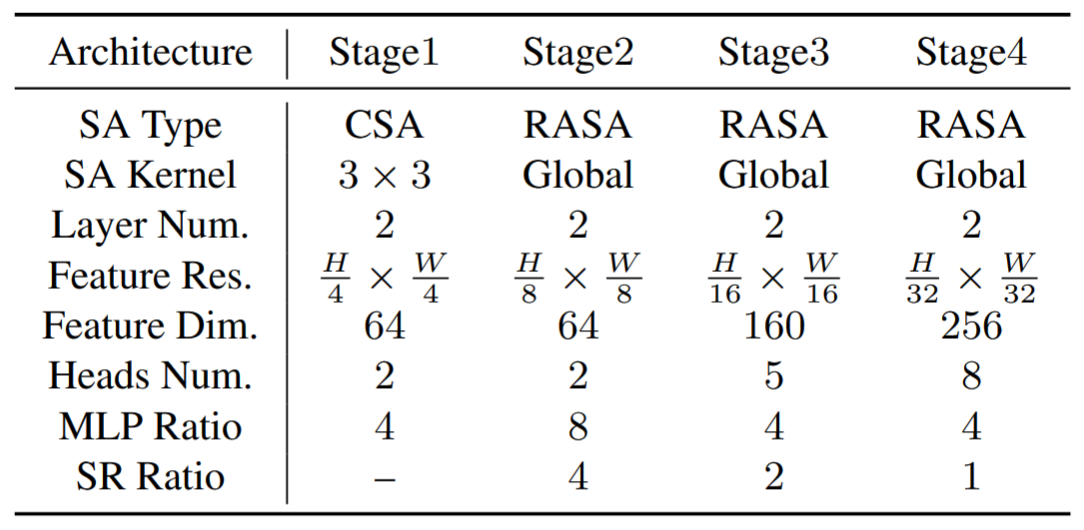
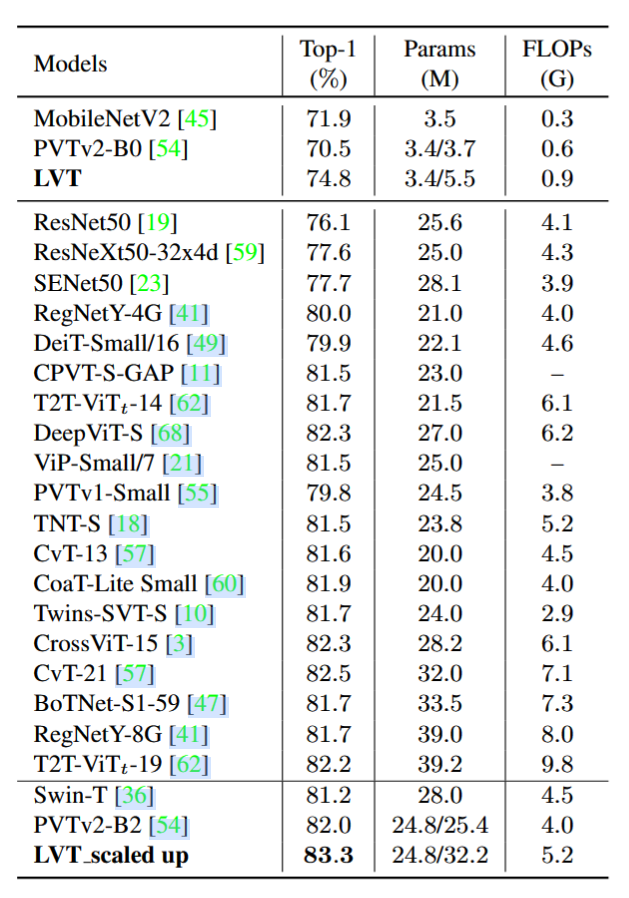
在 ImageNet 的实验结果表明,当参数量与 MobileNetV2 和 PVTv2-B0 相当时,本方法准确率显著较高。同时,增大到与ResNet50参数量接近时,本方法性能显著超越了当前方法。
其它部分可以参考作者论文,这里不再多说。

