【ICCV2021】Tokens-to-Token ViT: Training Vision Transformers From Scratch on ImageNet

部分内容来自于 GiantPandaCV 的文章
1、Motivation
作者指出VIT的不足之处:
- 直接将图片分块展开成一维向量不利于对图片结构信息(如边缘,线条)建模
- 冗余的Attention模块限制了特征表达,并带来运算负担
因此,作者提出了 Token to Token Transformer (T2T),采用类似CNN窗口的方式,将相邻的 token 聚合,有助于建模局部特征。
2、Method
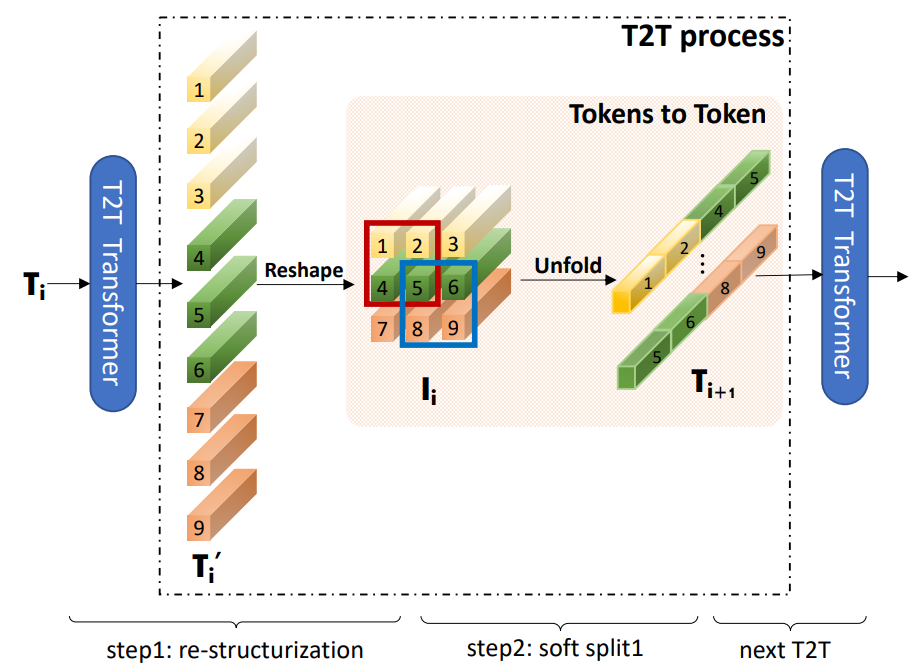
T2T 的流程如下图所示,将输入的 token 通过 reshape 操作转化为二维,然后利用 unfold 操作,属于同一个局部窗口的 token 拼接成一个更长的 token,再送入下一层。
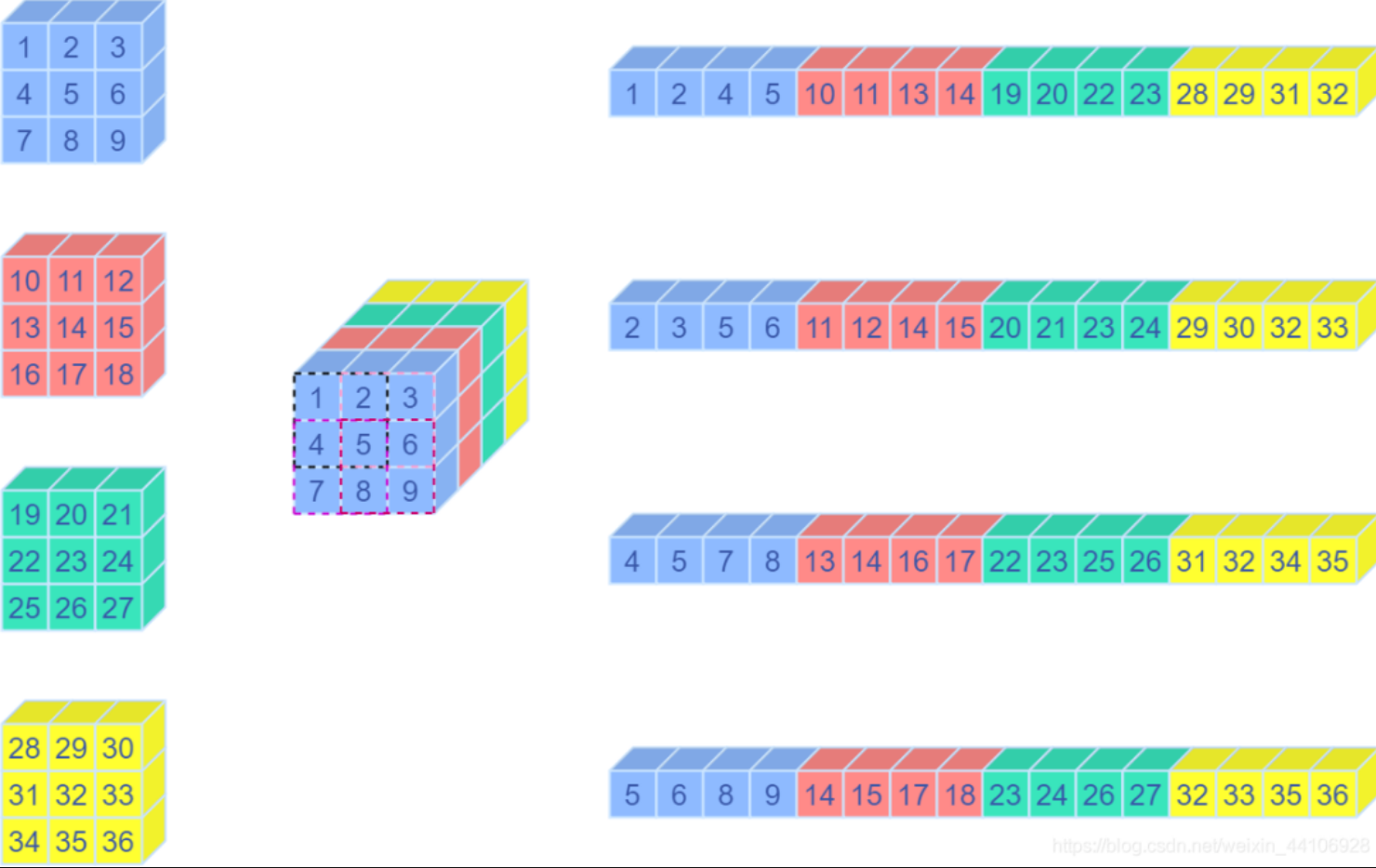
Unfold 操作其实是卷积中的 img2col 操作,将卷积窗口的向量,重排成一个列向量,示意图如下所示:
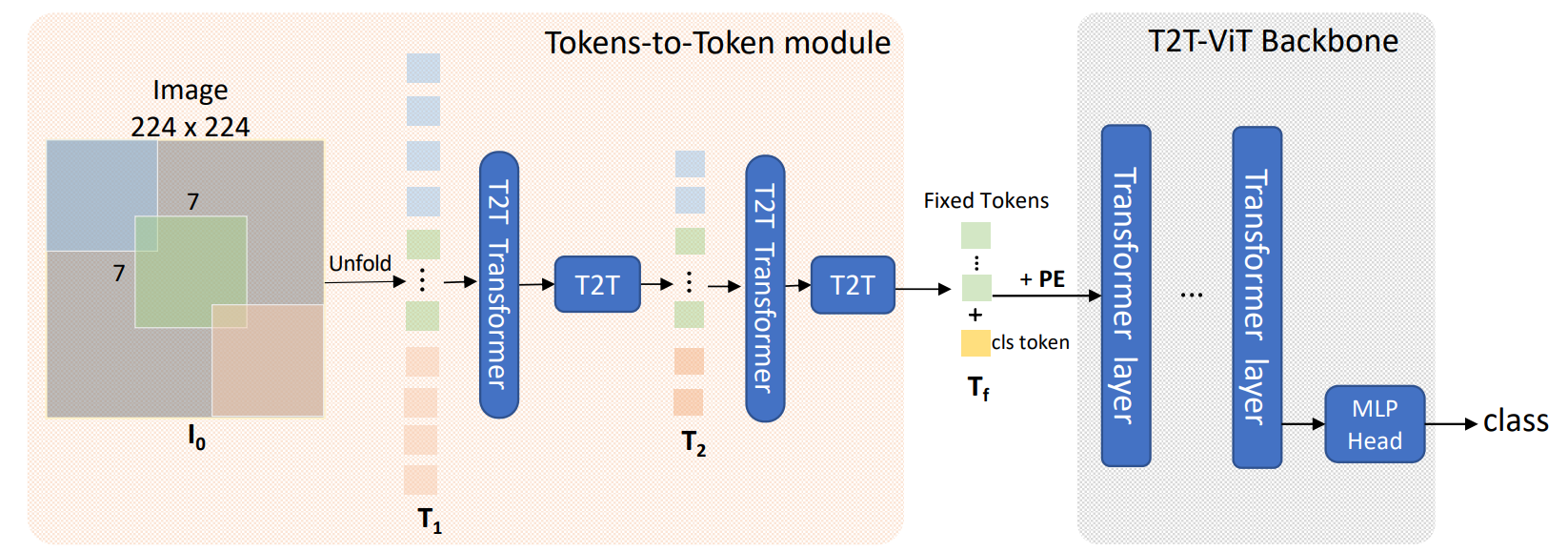
网络整体架构如下图所示,先经过2次Tokens to Token操作,最后给token加入用于图像分类的cls token,并给上位置编码(position embedding),送入到 VIT backbone 当中。
更多可以查看 Panda 的文章,代码讲解的也非常详细。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号