【CVPR2022】Restormer: Efficient Transformer for High-Resolution Image Restoration
 a
a
1、研究动机
论文的 motivation 非常简单,就是认为CNN感受野有限,因此无法对长距离像素相关性进行建模。因此,想使用 Transformer 的思路来进行图像修复。
2、主要方法
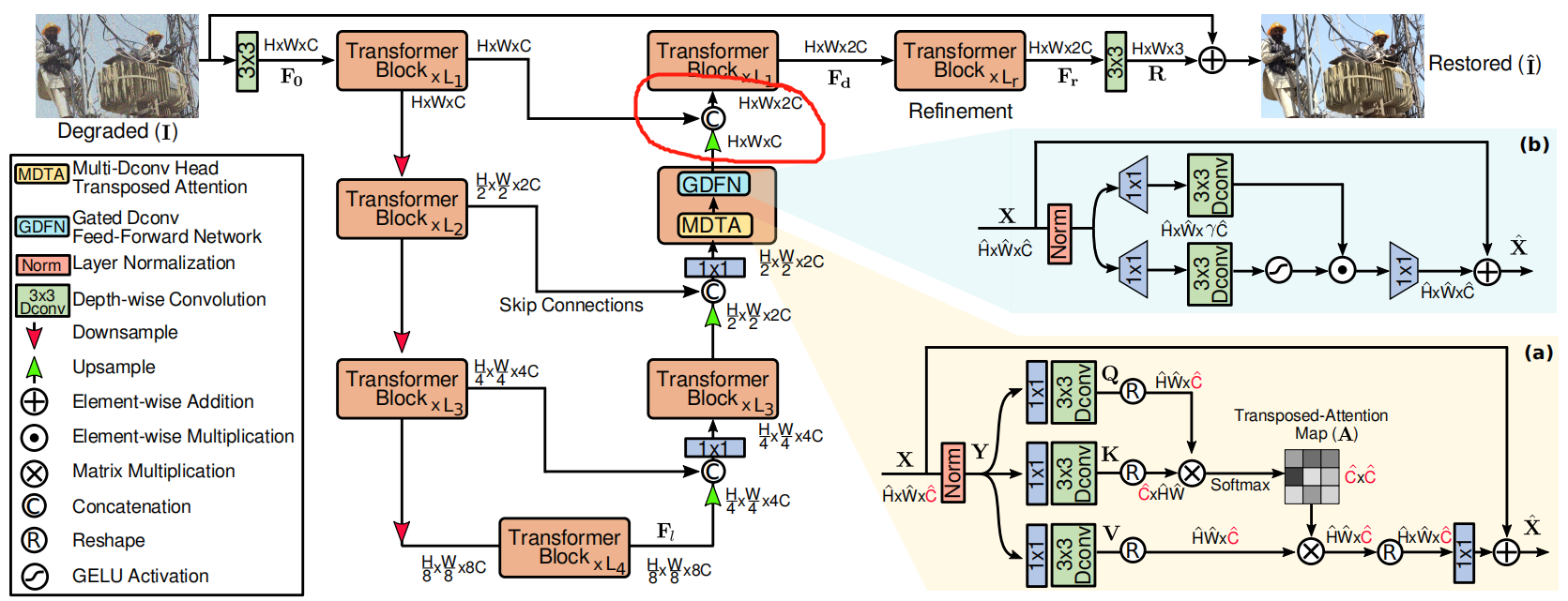
论文整体框架如下图所示,还是类似UNet的结构,按着1/2,1/4, 1/8 下采样,在中间添加skip connection。如图中画红圈的部分展示,每个 Transformer block 由两个部分串联组成:MDTA 和 GDFN。
对于特征上下采样,作者分别采用 PyTorch 里的 pixel-unshuffle 和 pixel-shuffle 实现,非常类似 swin transformer 里的 patch merging (不清楚实现是不是一样的,还没时间比较,汗 ~~~)。

MDTA (Multi-Dconv Head Transposed Attention)
Transformer中计算量主要来自于注意力计算部分,为了降低计算量,作者构建了MDTA,不在像素维度计算 attention,而是在通道维度计算。过程很简单,先用 point-wise conv 和 dconv 预处理,在通道维计算 atteniton,如下图所示。

直接看代码:
## Multi-DConv Head Transposed Self-Attention (MDTA)
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
# 升维,卷积,分块得到qkv
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
# 维度变化 [B, C, H, W] ==> [B, head, C/head, HW]
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
# [B, head, C/head, HW] * [B, head, HW, C/head] * [head, 1, 1] ==> [B, head, C/head, C/head]
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
# [B, head, C/head, C/head] * [B, head, C/head, HW] ==> [B, head, C/head, HW]
out = (attn @ v)
# [B, head, C/head, HW] ==> [B, head, C/head, H, W]
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
GDFN (Gated-Dconv Feed-Forward Network)
VIT中使用全连接网络FFN处理,在本文中作者有两个改进:1)引入 gating mechanism, 下面分支使用GELU激活。2)使用 dconv 学习图像局部结构信息。

直接看代码:
## Gated-Dconv Feed-Forward Network (GDFN)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
其它细节与实验分析
网络在下图中画红圈的部分还有一个细节,这个位置没有像之前的两个 block 使用 1X1 的卷积来降维,而是又使用了几个 Transformer block 来处理,叫做 Refinement stage。作者有一个实验专门验证这个 Refinement 阶段的有效性。
从 Level-1 到 Level-4 ,Transformer block的数量是 [4,6,6,8],MDTA中的 head 数量为[1,2,4,8],通道数为[48,96,192,384]。Refinement阶段有4个block。同时,作者还采用了 progressive training 的策略,输入图像尺寸从 128 到 384 渐增。
作者在图像去雨、单图像运动去模糊、散焦去模糊(在单图像和双像素数据上)、图像去噪(在合成和真实数据上)四个任务做了大量实验以证明方法的有效性。具体可以参照作者论文,这里不过多介绍了。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY