【ARXIV2202】Visual Attention Network
【ARXIV2202】Visual Attention Network
一些想法
- 这个方法看起来非常简单,有些像在MobileNet 中间加了一个 带空洞的 depth-wise conv
- 论文题目说是提出了一个 attention 模块,但网络本质还是四阶段的 transformer
- 没有任何一个模块是新提出的,但组合起来是在 计算量 和 准确率 间取得了平衡
- 性能的提升,可能关键点还是在于四阶段 transformer 网络的独特结构和训练策略
研究动机
作者指出 self-attention 存在三个不足:(1)将图像处理为一维序列,忽略了其二维结构。(2)很难处理高分辨率图像。(2)它只捕捉了空间适应性,而忽略了通道适应性。因此,作者提出了一种新的大核注意力(LKA)模块,并进一步介绍了一种基于LKA的新的神经网络——视觉注意网络(VAN)。
方法介绍
1、Large Kernel Attention (LKA)
LKA 与 MobileNet 很相似,MobileNet将标准卷积解耦为两部分,即 Depth-wise conv 和 Point-wise conv。作者将卷积分解为三个部分:大核 Depth-wise conv、大核带空洞的 Depth-wise conv 和 Point-wise conv。这样就有效地分解大的卷积核。
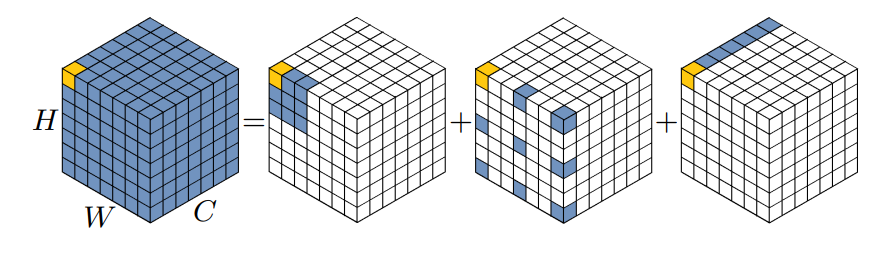
上图中,彩色网格表示卷积核的位置,黄色网格表示中心点。从图中可以看出,13×13卷积分解为5×5 DConv,5×5 dilated DConv,空洞步长为3 ,1×1点卷积。
如下所示,实际代码实现中为 5×5 的 DConv,7×7 的 dilated DConv,dilation=3,最后是1×1点卷积。
class AttentionModule(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)#深度卷积
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)#深度空洞卷积
self.conv1 = nn.Conv2d(dim, dim, 1)#逐点卷积
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn #注意力操作
class SpatialAttention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = AttentionModule(d_model) #注意力操作
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x) #注意力操作
x = self.proj_2(x)
x = x + shorcut #残差连接
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.attn = SpatialAttention(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))#drop_path分支中,每个batch有概率使样本在self.attn或者mlp不会”执行“,会以0直接传递。
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return
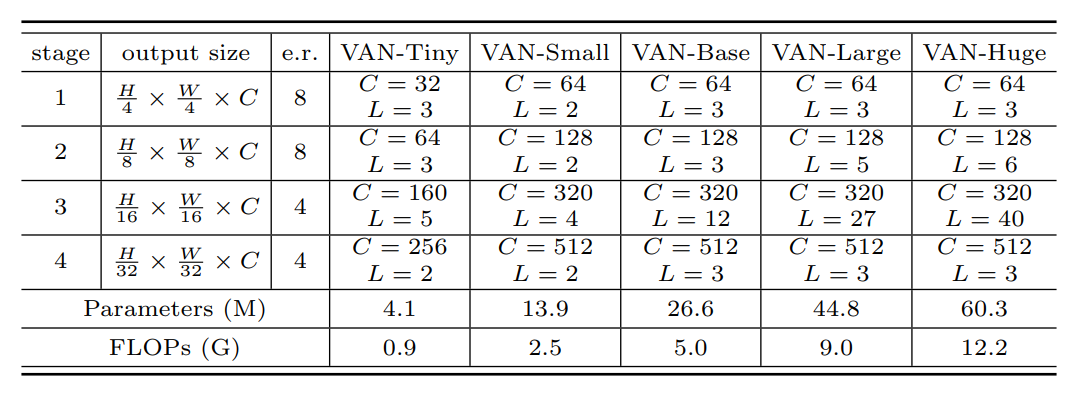
网络结构上,作者还是使用了 swin 的结构分为四个阶段:H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32。随着分辨率的降低,输出通道的数量也在不断增加。网络细节如下表所示,其中e.r. 表示FFN中的 expansion ratio。
每个阶段的图示如下:
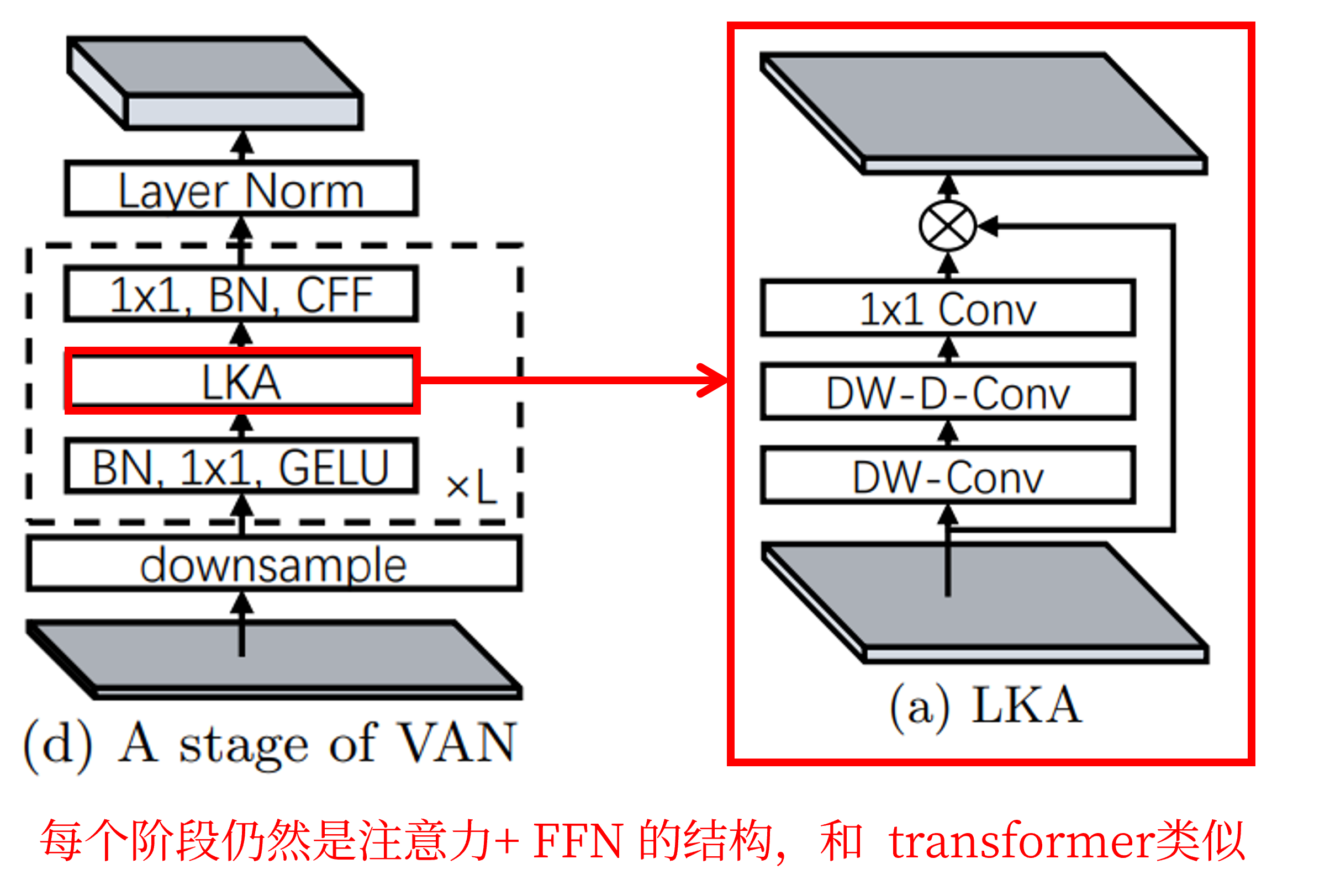
实验分析
1、图像分类
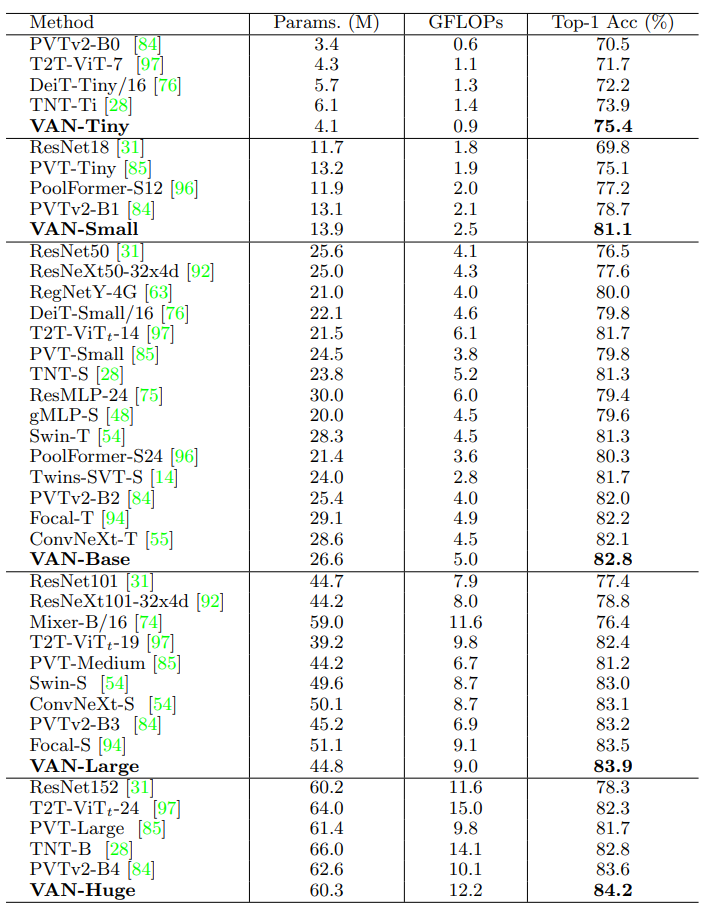
在图像分类任务上,VAN优于其他参数计算成本相似的CNN,ViTs 和 MLPs。作者在每个类别中选择了一个具有代表性的网络进行讨论。ConvNeXt[53]是一种特殊的CNN,它吸收了VIT的一些优点,如大的感受野(7×7卷积)和先进的训练策略(300个epoch、数据增强等)。VAN和ConvNeXt[53]相比,VAN-base比CoNvNeXt-t多出0.7%,因为VAN具有更大的感受野和自适应能力。Swin-Transformer是一种著名的ViT变体,采用局部注意力和移动窗口的方式。由于VAN对二维结构信息非常友好,具有较大的感受野,并在通道维度上实现了自适应性,VAN-Base比Swin-T提高了1.5%。从结果中可以看出,在小模型上面VAN的表现更加出色。
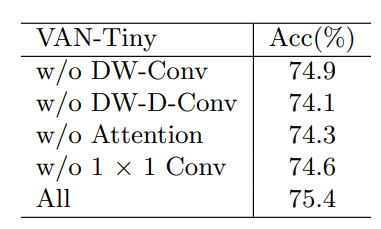
2、消融实验
DW-D-Conv提供了深度空洞卷积,这在捕获LKA中的长程依赖性中发挥了作用。DW-Conv可以利用图像的局部上下文信息。注意力机制的引入可以看作是使网络实现了自适应特性。受益于此,VAN-Tiny实现了约1.1%的提升。1×1 Conv捕获了通道维度中的关系。结合注意机制,引入了通道维度的自适应性,提高了0.8%,证明了通道维度自适应性的必要性。
3、可视化
从可视化的比较,可以看出VAN方法能够更好的聚焦目标区域。尤其是当目标占图像比例较大时,效果更好,也说明VAN可以捕捉长距离依赖关系。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!