【ICLR2022】Expediting vision transformers via token reorganization
【ICLR2022】Not all patches are what you need: Expediting vision transformers via token reorganization
一些个人想法
- 作者在第5、9、13层应用该方法,这个貌似没有给出原因
- 图1用的不是特别好,没看明白具体要说明什么
- 该方法和DynamicVIT是最相关的,最近有一系列相关的方法提出,值得关注
- 审稿人指出这个方法难以和swin等多尺度方法结合,因此 the real gain could be very limited
Abstract
之前的VIT将图像块作为token,来建立多头自注意力。但是与传统CNN相比,VIT的 global self-attention between image tokens and long-range dependency 使得模型收敛较慢。目前很少有人关注VIT加速,因为和CNN的差异,CNN加速的一些方法(蒸馏和修建等操作)无法直接应用于VIT。在本文中,作者提出在推理时,重新对token进行组织,实现方法如下:
- 保留关注的图像tokens和融合不关注的图像tokens来重组tokens,以加快后续MHSA和FFN计算,通过这种方式,随着网络的深入,逐渐减少图像tokens的数量,以降低计算成本
- 在相同数量的输入图像token情况下,该方法减少了MHSA和FFD计算量,实现高效推理
主要方法
在VIT中,最终是通过 [CLS] 来进行分类,和其他tokens的交互通过encoder的注意力机制完成:
这里的\(q_{class}\)表示[CLS],组合系数\(\textbf{a}\)是[CLS] 对所有 tokens 的注意力值。因此,可以用该注意力值来表示 tokens 的重要性。
因此作者使用 [CLS] 来识别 tokens 的重要程度,基于这些参数来移除注意力值最小的 token,但从下面的实验中可以看出,这会严重影响分类精度,所以作者在训练阶段加入了图像 token 重组。

作者的总体思路如下图所示:保留\(k\)个注意力值最大的 tokens,叫做 attentive tokens,然后把其它的 tokens 合并为一个新的 token。

对于 inattentive token,虽然包含较少的信息,作者认为它们仍然是有助于预测结果的,同时,作者是选择保留了固定数量的tokens,所以当图像中的对象较大时,移除与之相关的部分,会对性能造成负面影响。综上,作者将不重要的tokens进行融合(加权平均),融合后将继续向后传播 。

实验分析
实现细节
本文的 token identification module 被添加到 DeiT-S 和 DeiT-B 的第4、7、10层中,以及 LV -ViT-S 的第5、9、13层。另外作者采用了 warm up 的策略来进行 tokens 的标记。让 attention tokens 的保留率由1逐渐降低到目标值
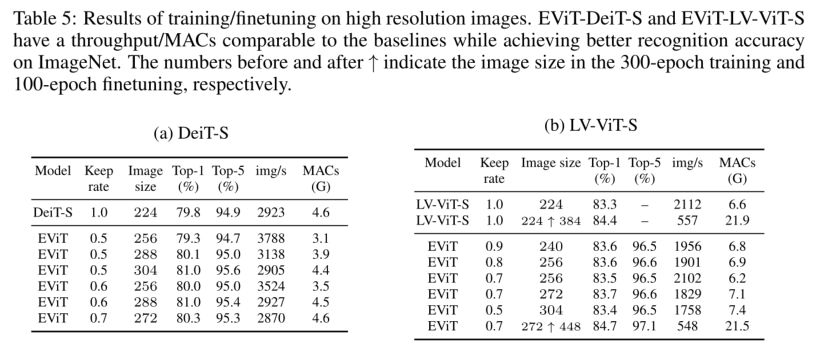
用高分辨图像训练
这里因为对tokens进行了融合减少,所以在维持相同计算量的情况下,允许更多地tokens输入,因此该方法可以输入更高分辨率图像。作者将标准输入图像 224×224 调整为 256×256
可视化
为了进一步研究 EViT 的可解释性,作者进行了可视化实验,可以看到基本上重要的目标区域都得到了保留。


