【ICLR2022】CrossFormer: A versatile vision transformer

【ICLR2022】CrossFormer: A versatile vision transformer
论文代码级的解析推荐阅读 FlyEgale 的文章:浅谈CrossFormer - 知乎
1、PVT回顾
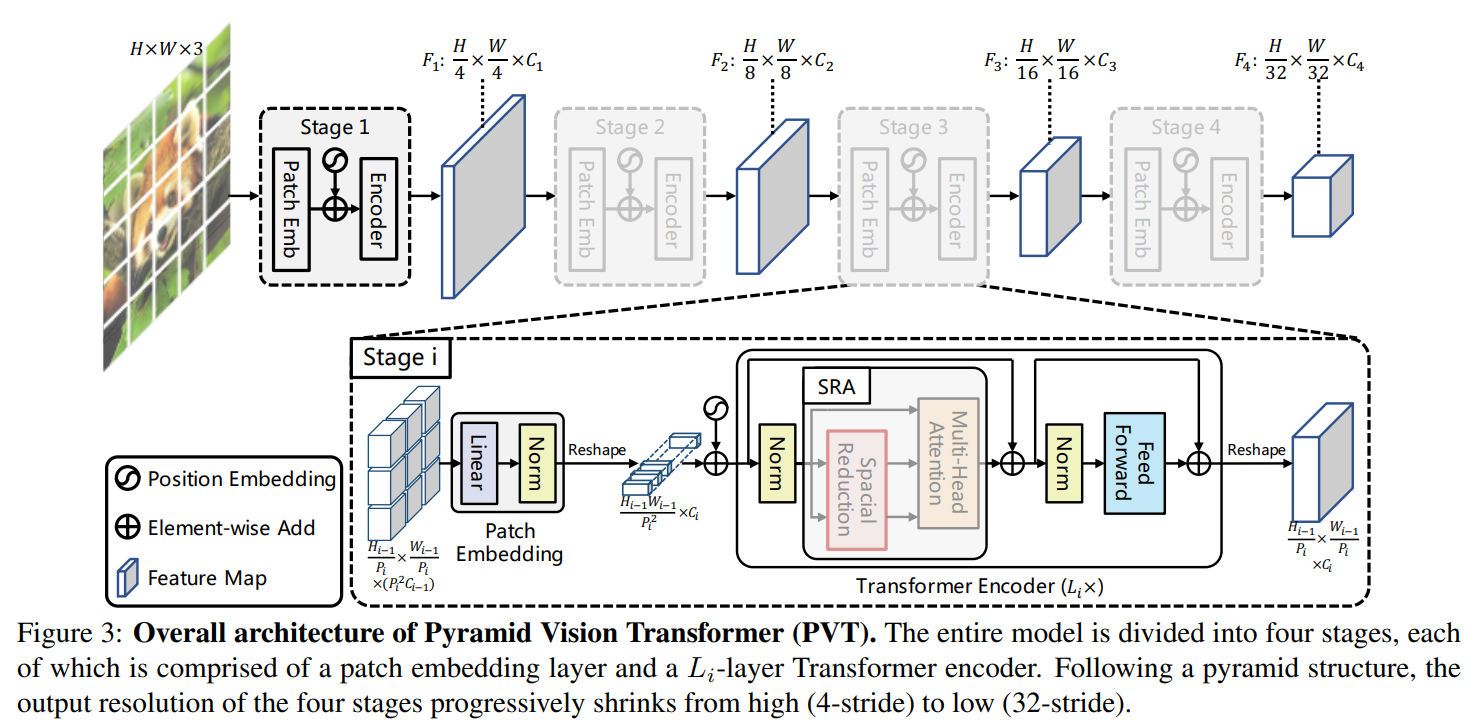
首先简单回顾下ICCV2021的 PVT,架构图如下所示。因为VIT没有考虑多尺度信息,PVT就通过特征下采样集成了多尺度信息。具体包括四个阶段:第一个阶段,输入是 \(H\times W\times 3\) 的图像,首先4x4分块得到 \(\frac{W}{4}\times\frac{H}{4}\)个patch(即token),每个patch 通过全连接层转化为\(C_1\)维向量,这样就得到了 transformer block 的输入。因为该模块的输入输出特征维度是相同的,因此第一阶段输出是 \(\frac{W}{4}\times\frac{H}{4}\times C_1\)。到第二、三、四阶段时,token的尺度分别为8,16,32,这样就集成了多尺度信息。
2、CrossFormer 与 PVT 的不同
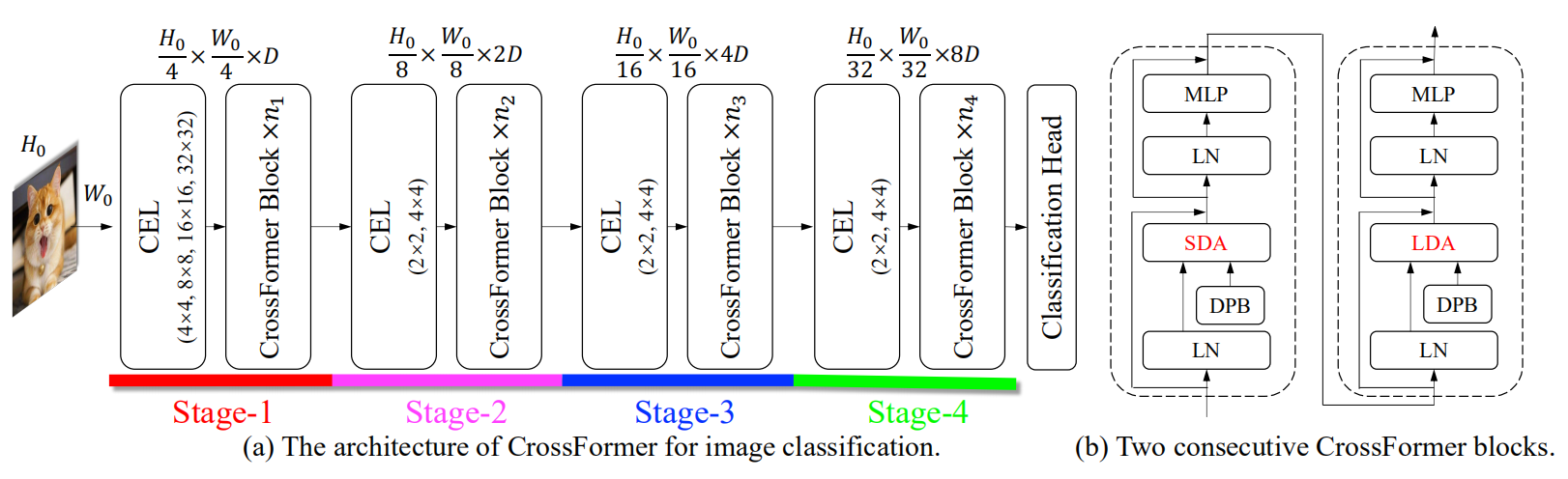
CrossFormer提出了跨尺度的基于跨尺度注意力机制的视觉Transformer,总体架构如下图所示,可以看出使用和PVT相同的金字塔结构,不同的地方在于:
- 提出了 cross-scale embedding layer (CEL) 和 long short distance attention (LSDA),可以建立跨尺度的注意力关联
- 提出了 dynamic position bais (DPB)模块用于相对位置编码
3、跨尺度嵌入层(CEL)
CEL 出现在每个stage的开头,它接收上一个stage的输出为输入,为当前的stage生成 embedding。以第一个stage的CEL层为例,如下图所示,用4个同尺寸的 kernel 进行卷积(步长都是4),得到的特征维度依次为【64,32,16,16】。有趣的话,小卷积得到的特征维度高,大卷积得到的特征维度低。作者解释是这样的原因为了避免大卷积引入更多计算量。这个模块 FlyEgle 有代码级的详细解析,可以参考他的文章。

4、长短距离注意力(LSDA)
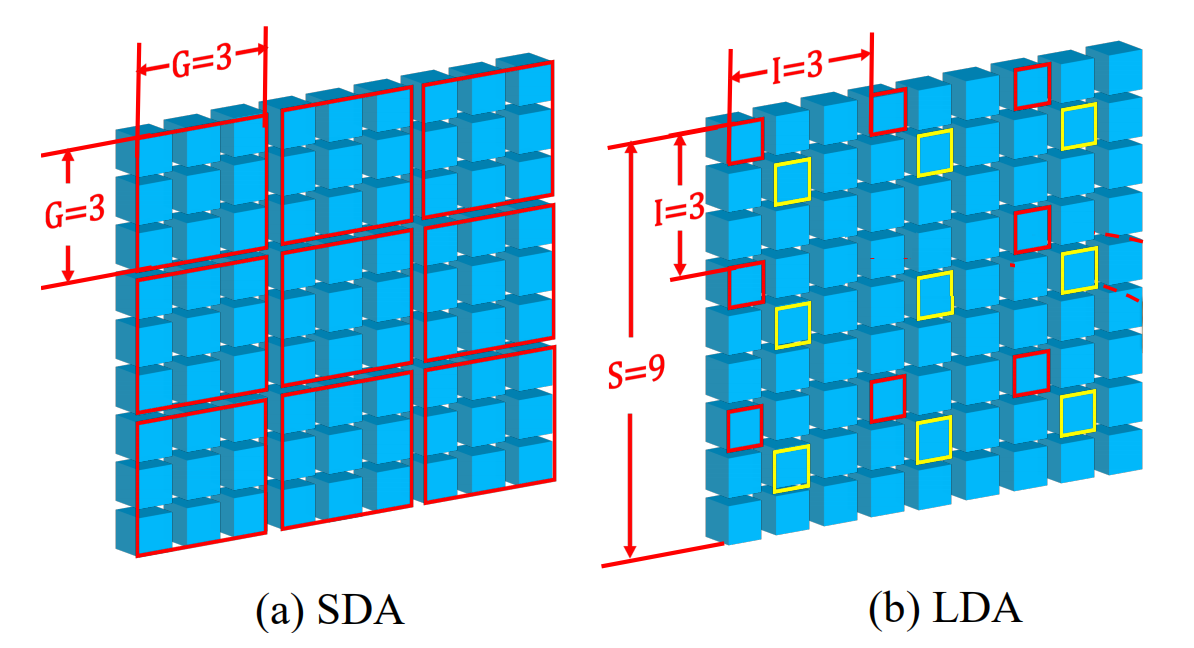
为降低计算量,作进行将自注意力分为 short distance attention(SDA)和 long distance attention (LDA)。常规的注意力计算是全局计算token间的关系,但是 swin 的经验表明,局部对token分组,计算组内token间的关系可以达到很好的效果,也会节省计算量。如下图所示,SDA把邻近的token分为一组,每组为 3x3=9 个 token;而LDA为有间隔的采样,同样是 3x3=9 个token为一组。SDA计算时是将下图输入的 9 x 9 x C 的输入矩阵reshape成 9 x (3 x 3) x C ,这样对 9个 3x3 做 attention 即可。LDA的计算相对复杂,具体推荐阅读 FlyEgle 文章的代码解读。
论文还有一个比较关键的部分:动态位置编码 Dynamic Position Bias (DPB),相对比较复杂,而论文里也没有比较详细的介绍 。从实验结果来看,效果和 swin transformer 的位置编码效果接近,没有太大区别。FlyEgle 文章里有比较详细的介绍,感兴趣可以阅读。
CrossFormer 参考了 PVT 和 swin 的思想,计算注意力时交替使用“局部注意力”和“长距离注意力”,两个结合起来能够取得非常好的效果。

