【AAAI2022】ShiftVIT: When Shift Operation Meets Vision Transformer

论文:【AAAI2022】When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism
1、研究动机
这个工作是使用一个非常简单的操作取代 attention,取得了非常好的效果。首先介绍一下论文的motivation。作者认为 Tranformer 取得成功的关键在于两个特性:
- Global:快速的全局建模能力,每个 token都能和其它的 token 发生关联
- Dynamic:为每个样本动态的学习一组权重
作者的 motivation 就是:能不能用更简单的方式来取代 attention ,更极端的就是 NO global, NO dynamics, and even NO parameter and NO arithmetic calculation .
为此,作者提出了 shift block,非常简单,本质就是对部分特征进行简单的移位操作来代替 self-attention 。
2、方法介绍
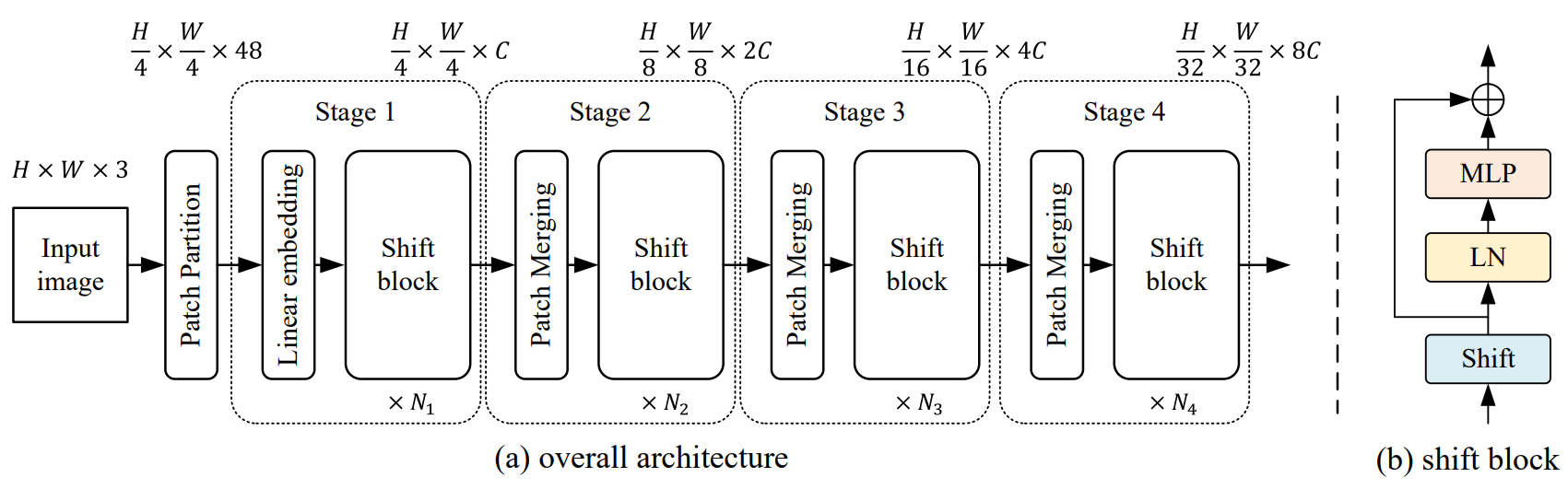
如下图所示,标准的 Transformer block 就是先用attention处理,再用FFN处理。作者提出用 shift block 来代替 attention。这个模块非常简单,就是将输入维度为CHW的特征,沿C这个方向取出来一部分,然后平均分为4份,这4份特征分别沿 左、右、上、下 进行移动,剩下部分的特征保持不变。

在作者的实现中,shift的步长设置为1个像素,同时,选择 1/3 的通道进行 shift (1/12的通道左移1个像素,1/12的通道右移1个像素,1/12的通道上移1个像素,1/12的通道下移1个像素)。该模块的 pytroch代码如下,可以看出来,这个模块计算非常简单,基本没有参数。

在网络架构上, 该方法对标的是 swin transformer,除了 attention 模块用 shift block 替代,其它部分是完全一样的。
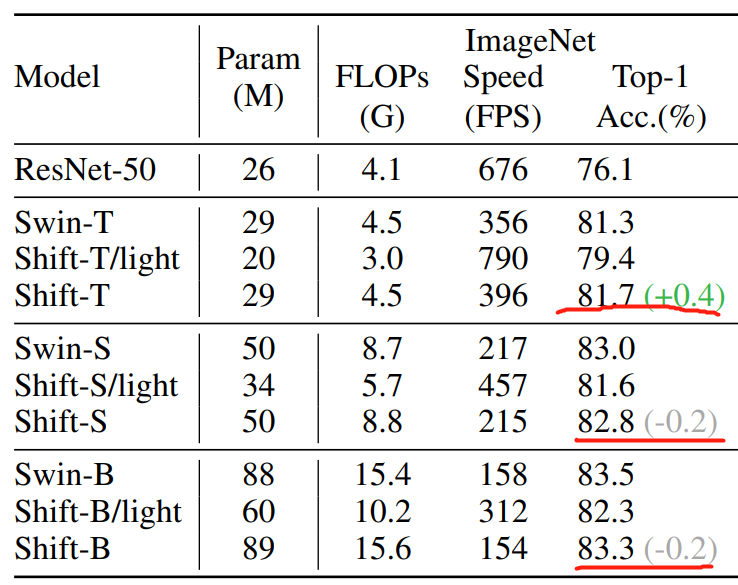
作者首先得到了 ShiftVIT/light,参数量显著减少。为了保持和 swin transformer 基本一致,作者在 stage3和 stage4 分别添加了6个和1个模块,达到和 swin transformer 参数量基本一致的模型 Shift-T,如下表所示。
| Name | Swin-Tiny | Shift-T/light | Shift-T |
|---|---|---|---|
| block数量 | [2,2,6,2] | [2,2,6,2] | [2,2,12,3] |
| 参数量 | 29 | 20 | 29 |
| FLOPs | 4.5 | 3.0 | 4.5 |
3、实验结果
下表只列出ImageNet图像分类上的实验结果,可以看出,直接替换性能会下降,但是增加模块的 Shift-T模型性能上升了,但是 S 模型和 B 模型性能会略微下降。作者还做了目标检测、语义分割的实验,得出结论是,性能和 swin 是差不多的,但是当模型比较小的时候,ShiftVIT会更有优势。
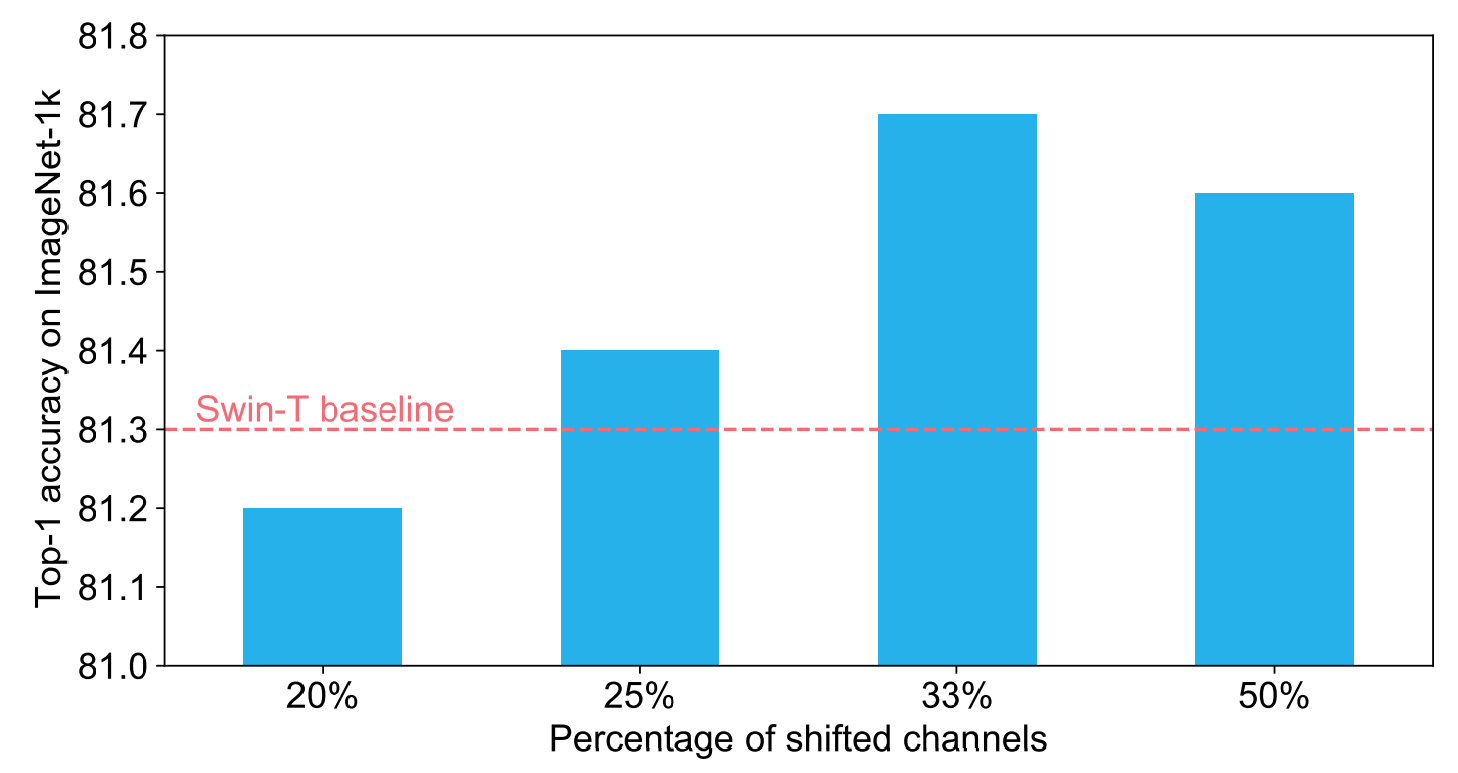
消融实验作者也分析了很多,这里只介绍 shift block 唯一个参数的实验,那就是 shifted channel 的比例,可以看看出,比例太少时,性能会不如 swin-T。当设置为 1/3 时,性能是最好的。
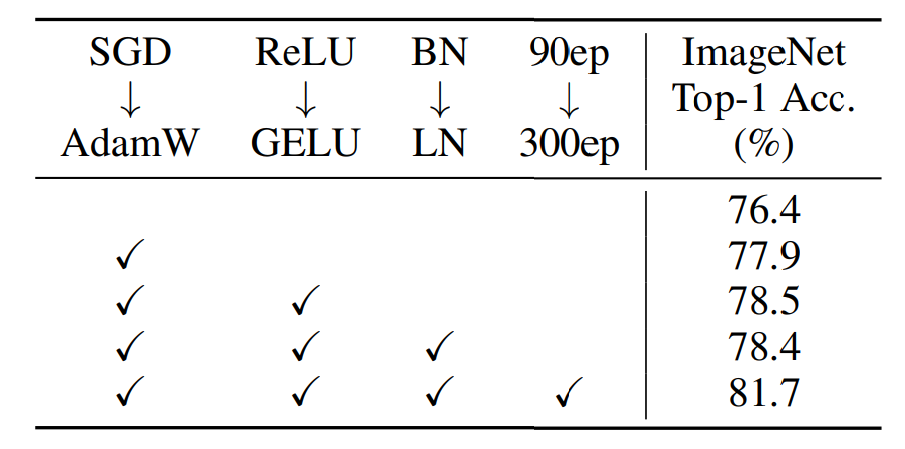
作者还进行了一个有意思的实验叫做 training scheme,分析了 Transformer 性能取得突破的原因可能也是一些 trick 。使用 Adam 替换 SGD,用 GELU 替换 ReLU,用 LN 替换 BN,以及增加 epoch 的数量,都会提升性能。这也说明,这些因素也可能是 VIT 取得成功的关键。
4、总结
作者总结两点启示:1)self-attention 也许并不是 VIT 取得成功的关键,使用简单的通道 shift 操作也能在小模型上超越 swin transformer。2)VIT 的训练策略(Adam、GELU、LN等)是性能提升的关键。

