【ICCV2021】Context Reasoning Attention Network for Image Super-Resolution

论文:【ICCV2021】Context Reasoning Attention Network for Image Super-Resolution
代码:https://github.com/Ast-363/CRAN (非官方实现)
论文的研究动机是“recent advances in neuroscience show that it is necessary for the neurons to dynamically modulate their functions according to context, which is neglected in most CNN based SR methods ”,因此,作者改进了Xudng Lin在ECCV2020提出的 Context-gated conv (CGConv),提出了 Context guided conv (如下图所示),应用到了超分辨率中。
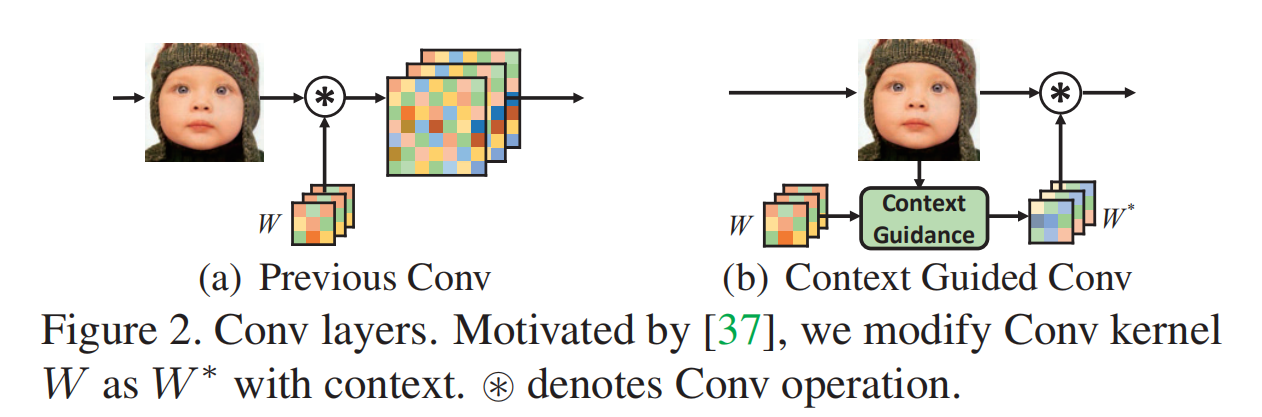
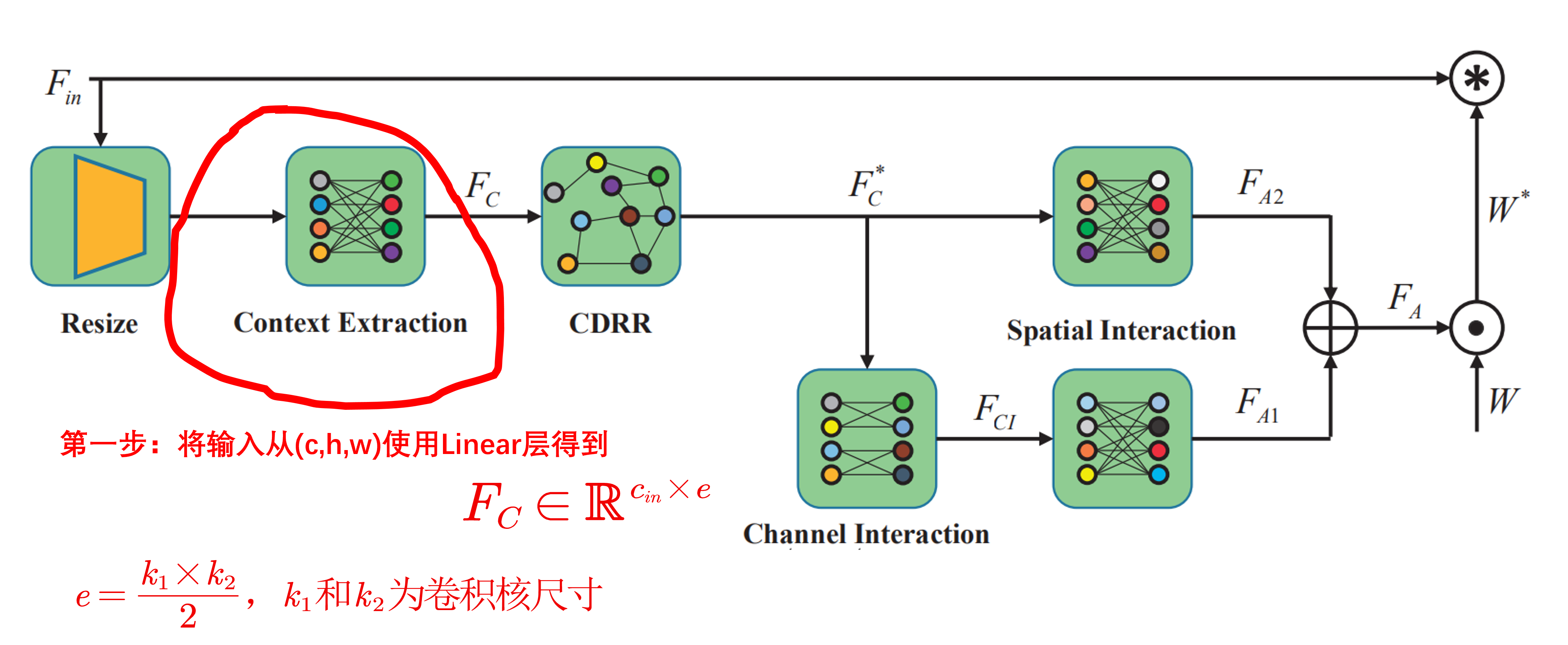
下面重点对Context guided conv 模块进行介绍,这个模块主要包含三个步骤:context information extraction, context descriptor relationship reasoning,和 context reasoning attention convolution.
第一步:context information extraction ,这一步和 CGConv 是完全一样的,就是使用全连接层把输入特征变成\(F_C\in\mathbb{R}^{c_{in}\times e}\)。
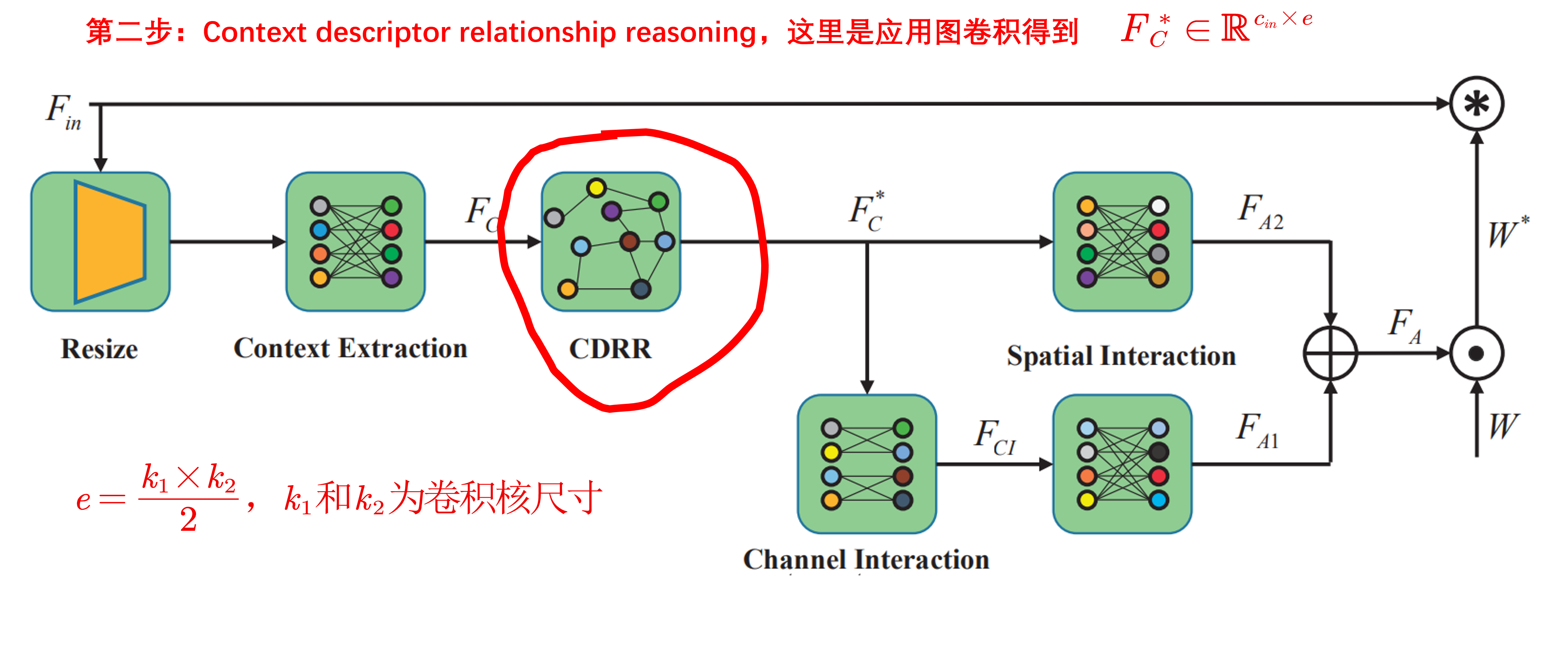
第二步:context descriptor relationship reasoning ,构建图\(G(F_C,R)\) ,图的节点是\(F_C\),图的边是\(R\),是一个\(e \times e\)的矩阵。应用图卷积得到输出特征\(F^*_C\in\mathbb{R}^{c_{in}\times e}\)。 (和GCConv 相比,这里是主要改进的地方)
第二步:context reasoning attention convolution ,这个步骤和之前的 GCConv 也是一样的,\(F^*_C\) 使用全连接分别得到 \(F_{A1} \in \mathbb{R}^{c_{out}\times k_1\times k_2}\) 和 \(F_{A2} \in \mathbb{R}^{c_{in}\times k_1\times k_2}\),(起名分别为 channel interaction 和 spatial interaction )。最后,将两者分别沿两个方向复制,接着融合得到 \(F_A\in \mathbb{R}^{c_{in}\times c_{out}\times k_1 \times k_2}\) 。 这里还使用 sigmoid 函数实现归一化。这样 \(F_A\) 就可以做为卷积核的权重,实现对卷积核的 modulating 。
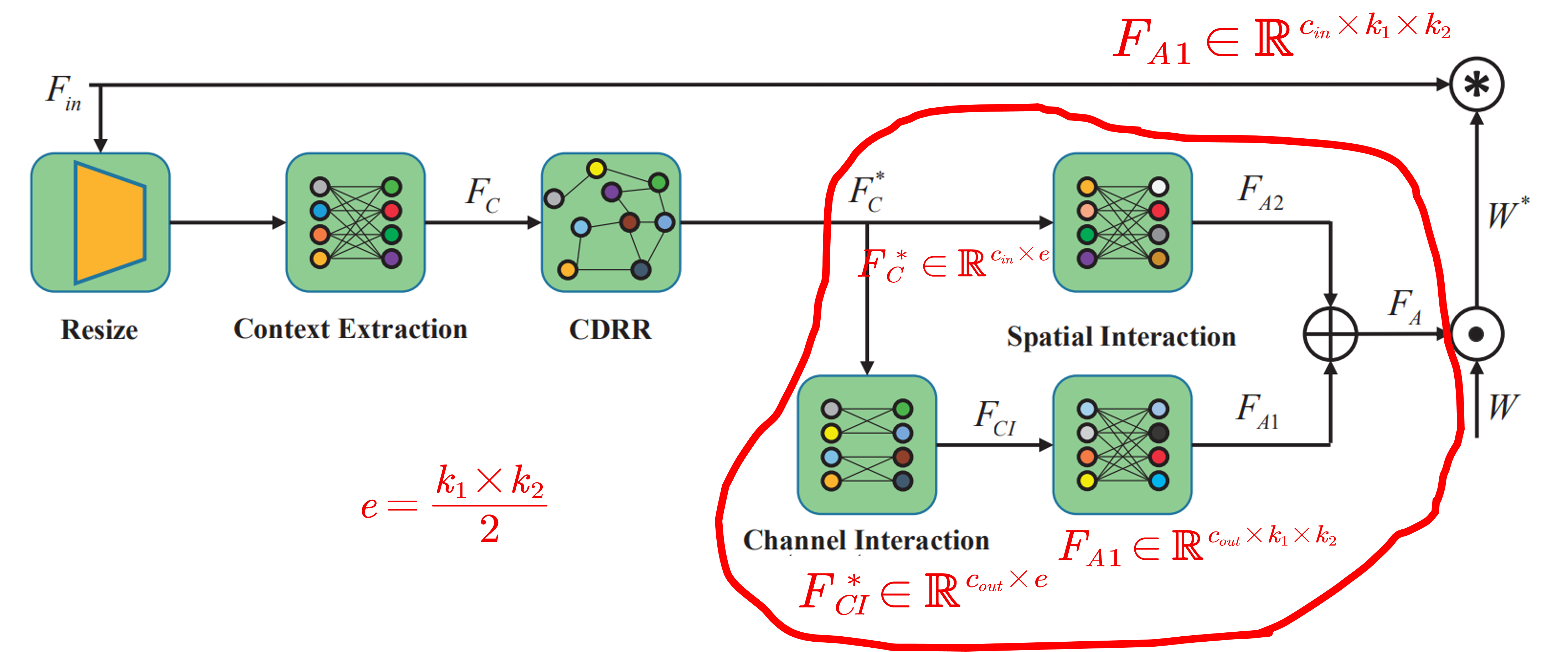
总体来看,第一步和第三步和之前的 GCConv 是差不多完全一样的,只是在第二步中加入了一个图卷积,这也是作者主要改进的地方。
论文的其它部分包括实验还没有仔细看,感兴趣可以阅读作者论文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号