【TGRS2021】Self-Supervised Denoising Network for Satellite-Airborne-Ground Hyperspectral Imagery
1. Motivation and framework
当前基于CNN的高光谱图像修复取得了非常大的进展,但是仍然存在如下两个问题:
- the trained model is limited to the model-driven noise simulation process and may generalize poorly to the real HSI with more sophisticated noise distributions.
- the whole-band approach may lead to an undesirable effect on the noise-free bands when only a few bands are degraded. In general, the noise degradation only occurs in a minority of the spectral bands, primarily due to the low SNR caused by the optical dispersion characteristics of the spectrograph. The noise intensity are varying among different bands, so that the whole-band assumption is not practical.
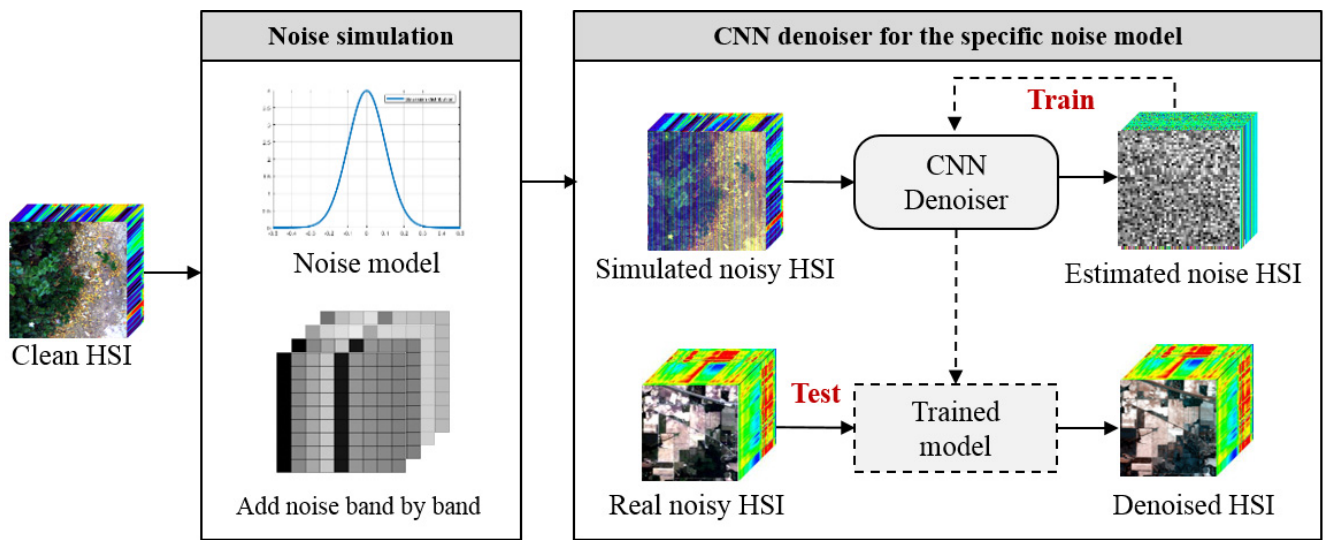
为了解决这两个问题,作者提出了一个 self-supervised 降噪网络(如上图),包括 noise estimator 和 CNN denoiser 两个部分:
- noise estimator的主要作用是 exploit the information of both the noise-free bands and the noisy bands,从而提取真实的噪声样本。 estimated noise samples and the clean bands from one single HSI are combined to build the paired training data. (noise sample 和 clean patches 都是从含噪声的HSI中生成,没有使用外部数据)
- CNN denoiser 是一个 multi-to-single 的 CNN网络。noisy bands and adjacent bands are jointly aggreated via the contextual dilated spatial blocks and the spectral convolutional blocks.
论文主要有三个贡献:
- 设计了自监督的网络去除HSI的混合噪声
- 设计了自监督的训练方法(noise-clean image pairs通过多次回归来从 noisy 高光谱图像自身提取)
- 构建multi-to-single CNN去噪模型用于提取 spectral-sptial 特征
2. Noise estimator
作者将 multiple regression 和 LMLSD 集成到一起。(这个地方没大看明白)通过这个操作,可以根据噪声强度阈值把全部波段分为 clean bands 和 noisy bands。然后,成对的训练数据是在 clean 数据上加上随机的 noise samples 来实现。
3. Self-supervised CNN denoiser
(1) self-supervised training scheme. 当前方法大多规定了Gaussian noise,strip noise, and mixed noise 模型来进行训练,当噪声分布不符合这些模型时,影响性能。根据噪声估计的结果,noisy HSI can be divided into clean bands and noisy bands. 成对的训练数据是在 clean 数据上加上随机的 noise samples 来实现。这样,it is effective for the model to remove the same noise in the noisy bands including specific bands. 作者指出,这样的设计就避免了当前方法严重依赖训练数据的不足,同时可以学习数据集中的真实噪声分布。
(2) Multi-to-single band denoising network. 作者提出了一个 multi-to-single 去噪网络,如下图所示。当前波段和相邻波段为一组输入\(\{y_{b-1}, y_b, y_{b+1}\}\) ,首先使用 multi-scale dilated conv 处理各个波段。作者指出,the spatial size of various ground objects can be quite different, so that it is difficult to capture enough contextual information from a single-scale receptive field. 因此,使用 multi-scale dilated conv aggregate the contextural information. (其实就是 dilated conv 应用了不同的步长) 。后面的 spectral denosing network 没有太多特点,这里不多介绍。
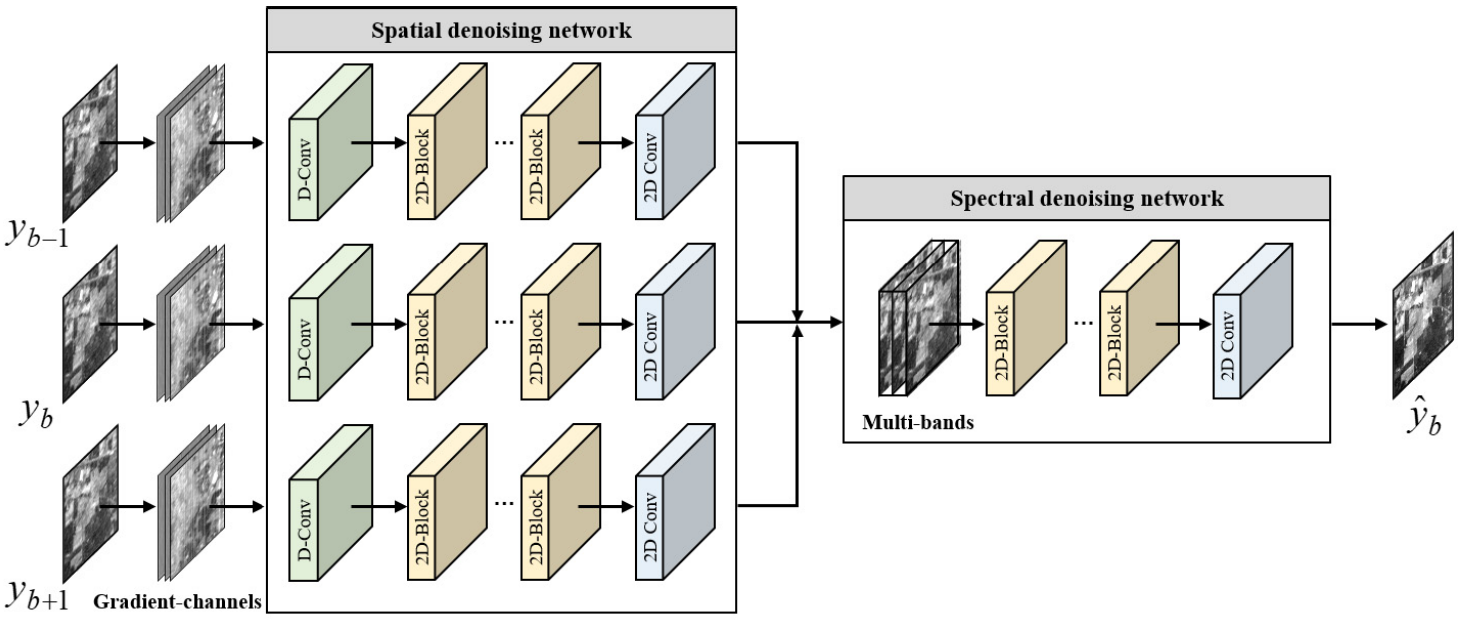
(3) Spatial-spectral model training. 在 output 和 realistic noise sample 之间计算MSE损失,这里不过多介绍。
实验部分可以参照作者论文,这里不过多介绍。

