【ARXIV2104】Attention in Attention Network for Image Super-Resolution
代码地址:https://github.com/haoyuc/A2N
1、Motivation
注意力机制在超分辨率领域应用较多,作者提出两个问题:
- What feature will attention layer strengthen?
- Is attention always effective?
对于上述问题,作者评估了注意力机制增强的区域,然后发现对于shallow layer,注意力机制增强low-frequency bands ;对于 deep layer,注意力机制增强 high-frequency bands。这说明,并不是在所有层加注意力机制都可以改进网络性能。“There are some inefficient and redundant features. Using attention on all layers is not hte most efficient.”
作者首先进行 attention block heatmap 可视化实验,如下图所示。第一行是 attention layer 的输入,第二行是 attention layer 的输出,其中红色代表正值,蓝色代表负值。第三行是 attention map 的平均值,越亮代表系数越大。可以看出,浅层的 block 是低频区响应强(系数大),深层的 block 是高频区响应强。

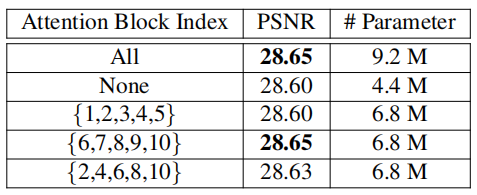
作者接着做了一个 Attention dropout 的实验,如下表所示。{1,2,3,4,5}表示前五个 block 的 attention 保留,后面五个关闭。实验结果非常有趣,只保留后面五个 block 的 attention 效果非常好,同时参数也较少。结果表明“spending budget on attention uniformly across the network is sub-optimal”
2、Method
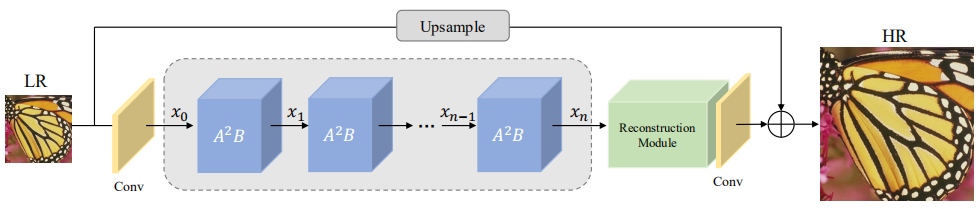
2.1 网络总体架构
作者提出的 attention in attention netowrk (\(A^2N\))如图所示。包括一个卷积层,几个 attention in attention block,一个重建模块,这里不多描述。
2.2 Attention in Attention Block
受到动态卷积的启发,就是动态卷积可以“aggregate multiple parallel conv kernels dynamically based upon their attentions”,作者提出一个 learnable attention dropout module 来自动扔掉不重要的特征,同时平衡 attention branch 和 non-attention branch. 该模块如下图所示,可以看出 non-attention 分支就是一个3X3卷积; attention 分支是使用sigmoid给输入的特征调节权重。
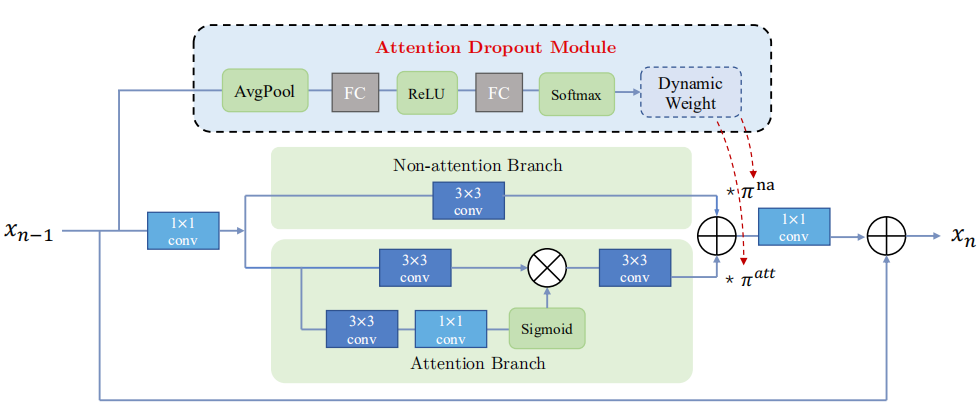
上面标红的是 attention dropout module,其实就是一个SE模块,可以给两个分支分配权重,分别是\(\pi^{na}\) 和 \(\pi^{att}\)。作者也指出,对两个权值进行限制可以 “faciliate the learning of attention dropout module”,因此限制 \(\pi^{na} + \pi^{att} =1\)。
实验部分可以参考作者论文,这里不过多介绍。

