【ICLR2021】Robust and generalizable visual representation learning via random convolutions
论文:Robust and generalizable visual representation learning via random convolutions, ICLR 2021
代码:https://github.com/tourdeml/robust-representation-random-convolutions
深度学习算法对于 texture style shifts 和 small perturbatgions 比较敏感,因此,作者提出了一种数据增强算法 RandConv。该方法的主要思路是使用多尺度的 random conv 生成图像,同时保持目标的全局形状。
下图中第一行为RandConv算法示意,可以将图像中的纹理随机化,但是保持目标的整体形状。第二行为取不同大小卷积核时,结果的变化。第三行为把原图像和RandConv结果按不同比例混合时的结果变化。

从图中可以看出,1X1的卷积可以保留形状,相当于改变了目标的颜色。大的卷积核可以对于小于该卷积核尺寸的纹理进行挠动。
作者设计了四种方法:
- \(\textrm{RC}_{img}\): augmenting image with random texture.
- \(\textrm{RC}_{mix}\): Mixing variant. $\textrm\( 的结果可能和原来图像差别很大,这样把原来图像和\)\textrm$ 进行加权混合,可以得到较好的结果
- Multi-scale texture corruption: Filter varying sizes to preserve shapes at various scales.
- Consistency regularization: To learn representations invariant to texture changes, we use a loss encouraging consistent network predictions for the same RandConv-augmented image for different random filter samples.
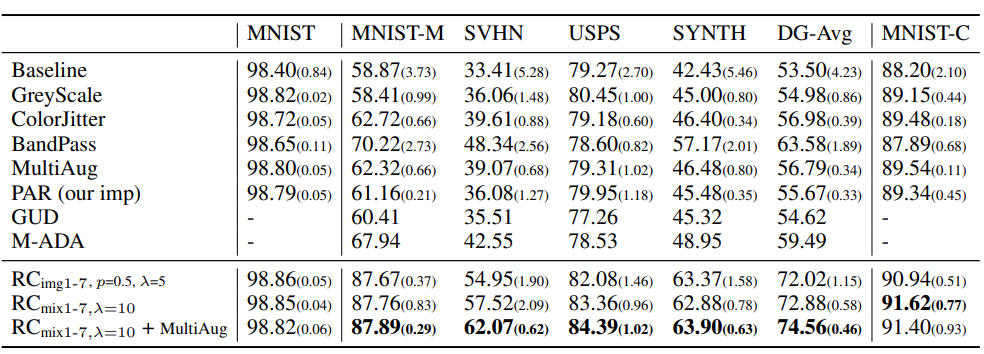
在数字识别任务上,可以看出RandConv比其它方法有显著的性能提升。
同时,作者还做了其它的一些实验,sketch domain,预训练等等,这里不再多说,细节可以参考作者论文。
