【CVPR2021】Image super-resolution with non-local sparse attention
论文:【CVPR2021】Image super-resolution with non-local sparse attention
代码:https://github.com/HarukiYqM/Non-Local-Sparse-Attention
对于超分辨率应用,non-local attention是非常流行的,因为它可以利用图像中的 self-similarity prior,因为一些小的 pattern 会在图像中重复出现。但是,直接应用 non-local 也会出现一些问题:
-
the receptive field of features in deeper layers tend to be global, thus the mutual-correlation computation among deep features are not accurate.
-
global non-local attention requires the computation of feature mutual-similarity among all the pixel locations. It results in quadratic computational cost with respect to image size.
为了解决上面两个问题,作者提出了 non-local sparse attention (NLSA),主要贡献为:
- NLSA module. The sparsity constraints forces the module to focus on correlated and informative area while ignoring unrelated and noisy contents.
- Feature sparsity是通过特征分组,同时non-local只在组内进行(称为attention bucket)。同时,应用locality sensitive hashing算法给每组进行hash编码,因此显著降低了计算复杂度。
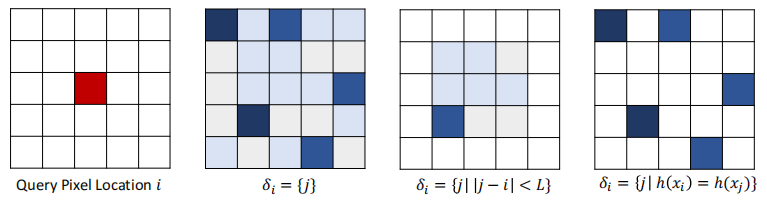
作者提出的Attention Bucket 如下图所示。对于第一个图中的红点像素,普通的non-local要全局计算其它像素和它的相似性。该方法添加了sparsity constraint。通过稀疏性计算一组位置,称为 attention bucket,如第二个图所示。作者指出,中以施加一个距离约束,只取距离较近的点计算相似性,但这样做不能aggregate long-range context. 作者的做法是rank all mutual similarities and then use the top \(k\) entries. 但是,这样就需要首先计算当 query pixel 和所有点间的相似性,计算非常耗时。因此,作者利用了 locality sensitive hashing算法进行快速计算。
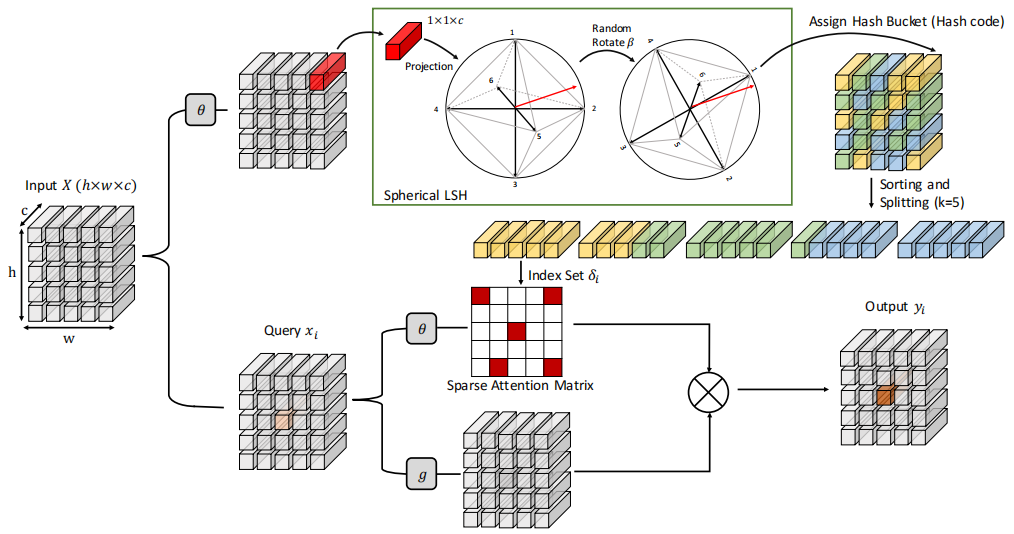
NLSA模块如下图所示。Upper branch partitions the input features into buckets via LSH. The bottom branch computes attention after sorting the buckets by the hash code. 这样的结构结合了 non-local 的优点,也因为稀疏和哈稀保持了计算的高效性)。
网格的整体架构如下图所示,是建立在EDSR算法之上的。包含32个残差块,应用了5个NLSA模块。

实验部分可以参照论文,这里不再多介绍。

