极市No. 78 基于卷积神经网络的图像复原
今天在极市平台第78期线上直播听了哈工大田春伟博士的报告《基于卷积神经网络的图像复原研究》,有三个工作比较有趣,记录一下:
1、 基于双路径卷积神经网络的图像去噪
Chunwei Tian, Yong Xu, Wangmeng Zuo. Image denoising using deep CNN with batch renormalization, Neural Networks 2020.
当前方法的不足:问题一,大多数基于CNN的图像去噪方法都通过增加网络深度提升性能,但该操作会增大训练的难度。问题二,大部分方法都通过 batch normalization 来解决训练样本分布不均匀问题,当 batch 较小时,不同块间数据分布差异增大,去噪性能下降。
解决思路: 对于问题一,该论文提出了一种双路卷积的网络,增大了宽度,可以提取互补的特征提升性能;对于问题二,该论文将 batch renormalization (Ioffe, NeurIPS2017) 应用在网络中,解决硬件资源受限时训练数据分布不均匀的问题。
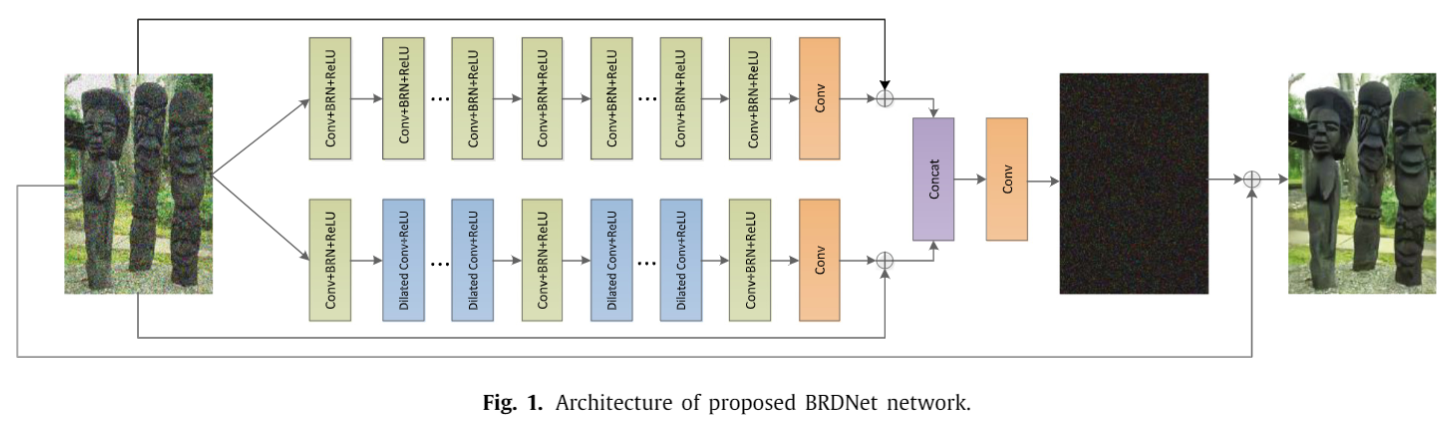
该方法的框架如下图所示。绿色块中是 Conv + batch renorm + ReLU ,蓝色块中是 Dilated Conv + ReLU 。作者的解释是:下面网络使用 Dilated conv,与上层网络的特征形成互补,增大了网络两个 分支的差异,提升去噪性能。
2、 基于注意力机制CNN的图像去噪
Chunwei Tian, Yong Xu, Zuoyong Li, Wangmeng Zuo, Lunke Fei, Hong Liu. Attention-guided CNN for image denoising, Neural Networks 2020.
当前方法的不足:问题一,当前网络忽略噪声任务属性,不能很好地处理复杂场景的噪声。问题二,大部分方法都通过大幅度增加网络深度提升性能,会增加计算代价,不利于实际应用。
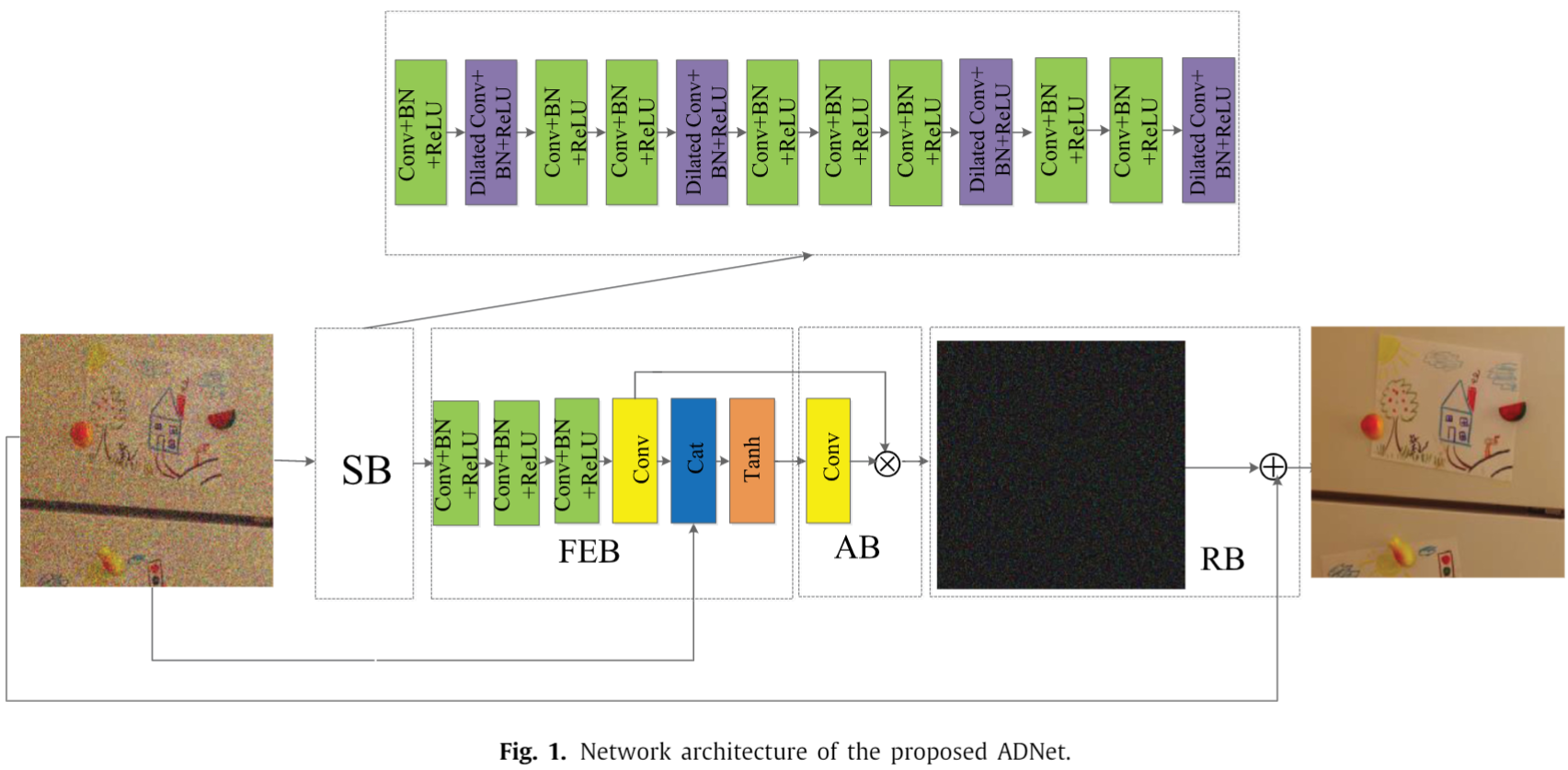
解决思路:
- 对于问题一,提出 attention block (AB),将 FEB 的输出用 1X1 的卷积转化为一个权重向量,然后该权重向量与 FEB 中卷积的结果相乘来实现通道级的 self-attention。这样的作用是 deeply exploit noise information hidden in the complex background.
- 对于问题二,提出 sparse block (SB),只有12层,绿色块是 Conv+BN+ReLU,紫色块是 Dilated conv + BN + ReLU 。作者指出,紫色块用于获取更大感受野,可以理解为 high energy points;绿色块可以理解为 low energy points. The combination of several high energy points and some low energy points can be considered as the sparsity. 作者指出,12层的 sparse block 能够取得较好性能,也就降低了网络深度。
- 此外,作者还构建了一个 feature enhancement block (FEB),将原图像融入网络。这样的作用是 enhance the expressive ability of the model.
3、基于非对称卷积的图像超分辨率
Asymmetric CNN for image super-resolution, IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021.
当前方法的不足:问题一,当前方法大多训练固定缩放因子的模型,但真实世界中收集到低分辨率图像受损程度不同,限制了这些方法的实际应用。问题二,当前方法对所有像素提取特征时同等对待,增大了计算量并造成信息冗余。
解决思路:
- 对于问题一,采用一组自适应的子像素卷积技术把低频特征转化为高频特征,训练固定缩放的模型、可变缩放因子的模型 和 未知类型噪声可变缩放因子的模型,使用户根据需求选择合适的模型
- 对于问题二,采用非对称卷积(ACNet)在竖直和水平方向增强卷积核,扩大局部显著性特征的作用。
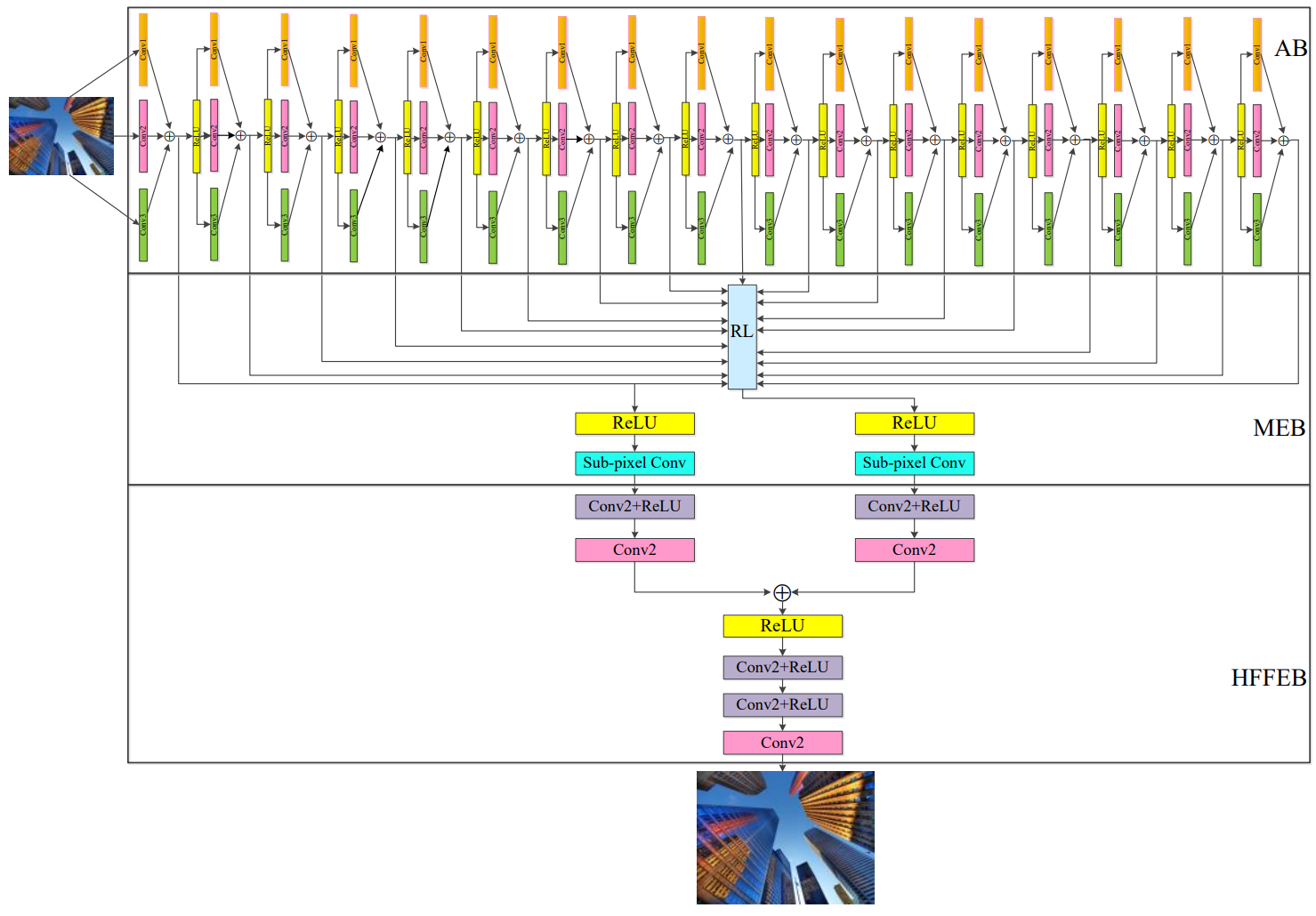
网络架构如图所示。上面是17层的 Asymmetric Block,每层使用 1X3,3X3,3X1 三种卷积核并行,这部分比较容易理解。
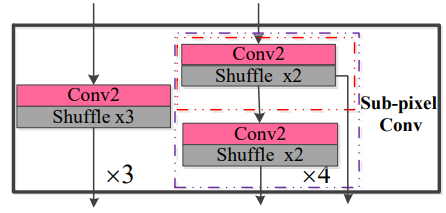
中间是 Memory enhancement block,首先将17层卷积的结果直接求和,然后用 ReLU 激活,作者指出这一步得到的是 low-frequency feature ,然后使用 sub-pixel conv 将 low-frequency feature 转化为 high-frequency feature。sub-pixel conv 如下图所示,可以实现2倍、3倍、4倍的超分辨率,用户可以在训练时进行选择。
最下面是 High-frequency feature enhancement block。为了提高模型稳定性,用两个并行卷积融合低频和高频的特征。融合以后,用3个 conv 得到最终的输出结果。

