Mixup Without Hesitation
1、Motivation
论文指出当前 Mixup 算法存在的两个问题:1) Require more epochs to converge. 在ImageNet上训练时,Mixup 需要 200个 epoch 才收敛,但普通算法只需要90个。 2)Different \(\alpha\) values lead to big differences in model accuracy.
在CIFAR10上训练时,loss 在测试集上的误差如下图所示。一个现象:基于原始数据训练时,曲线更加平滑,这表明 mixup introduces higher uncertainty 。另一个现象:训练的初始阶段, mixup 的误差较大,这表明该算法在求解全局的最优,而不是及早的陷于局部最优(it focuses on exploring the energy landscapes and will not fall into local optima prematurely).
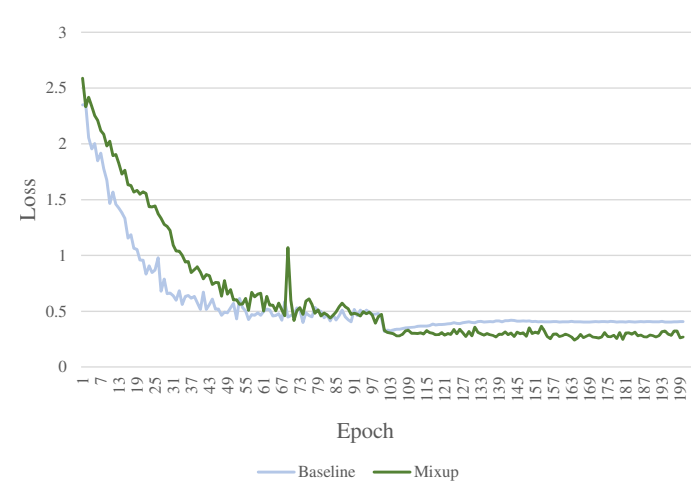
同时,作者还在CIFAR100上进行实验,一共训练 100 个 epoch,只在前50轮应用 mixup 的效果是最好的。因此,作者得出结论: Mixup is effective because it actively explores the search space in the early epochs, while in the later epochs, mixup might be harmful.
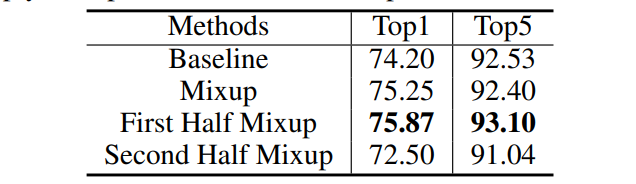
因此, gradully replace mixup with basic data augmentation 应该是比较好的解决方案。
2、Method
论文提出了 mixup Without hesitation (mWh) 算法,假定训练时 mini-batch 的数量为\(m\),定义两个参数 \(p\) 和 \(q\) (\(0\leq p < q \leq 1\))把训练过程分为三个阶段:
- 阶段1,从 1 到 \(pm\) 个 mini-batch,使用 mixup 训练;
- 阶段2,从 \(pm+1\) 到 \(qm\) ,在 mixup 和基础数据增强算法中切换
- 阶段3,run mixup with probability \(\epsilon\) ,where \(\epsilon\) decreases linearly from 1 to 0.
在阶段1,mWh算法使用 mixup 在 large portion of the sample representation space 里搜索。
阶段2 里是 exploration 和 exploitation 的权衡。(作者在论文里用了一个词:exploration-exploitation dilemma,翻译为探索-利用困境。比方说新开一家饭店,每次吃饭点两个菜,一般是点一个以前觉得好吃的菜,再点一个没吃过的菜,这样就不至于每次都吃以前的菜,又能探索没吃过的,这是“探索”与“利用”的权衡,有些扯远了 😂)
阶段3 逐渐从 exploration 模型切换为 exploitation 模式。
在多个任务上做实验,mWh 均取得非常好的效果。具体可以参考作者论文,这里不再多说。

