
转自:https://www.jianshu.com/p/78989cd553b4
一、Segment
HashMap 在高并发下会出现链表环,从而导致程序出现死循环。高并发下避免 HashMap 出问题的方法有两种,一是使用 HashTable,二是使用 Collections.syncronizedMap。但是这两种方法的性能都能差。因为这两个在执行读写操作时都是将整个集合加锁,导致多个线程无法同时读写集合。高并发下的 HashMap 出现的问题就需要 ConcurrentHashMap 来解决了。
【介绍JDK 1.7】ConcurrentHashMap 中有一个 Segment 的概念。Segment 本身就相当于一个 HashMap 对象。同 HashMap 一样,Segment 包含一个 HashEntry 数组,数组中的每一个 HashEntry 既是一个键值对,也是一个链表的头节点。单一的 Segment 结构如下:
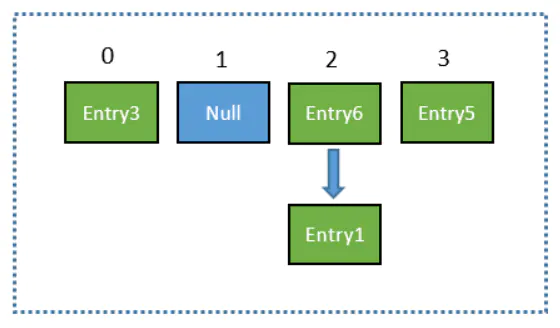
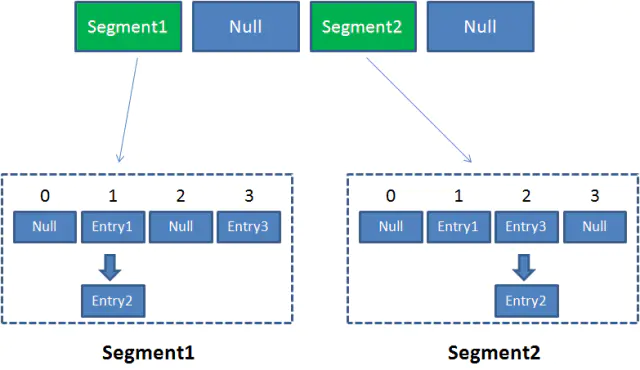
可以说,ConcurrentHashMap 是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。这样的二级结构,和数据库的水平拆分有些相似。
1️⃣ConcurrentHashMap 的优势
采取了锁分段技术,每一个 Segment 就好比一个自治区,读写操作高度自治,Segment 之间互不影响。
Case1:不同 Segment 的并发写入【可以并发执行】
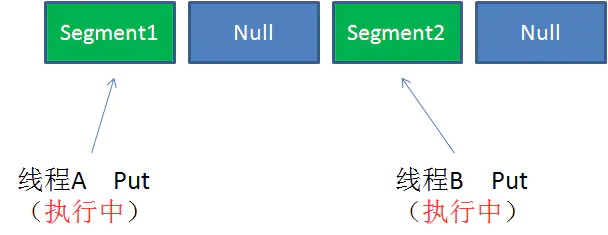
Case2:同一 Segment 的一写一读【可以并发执行】
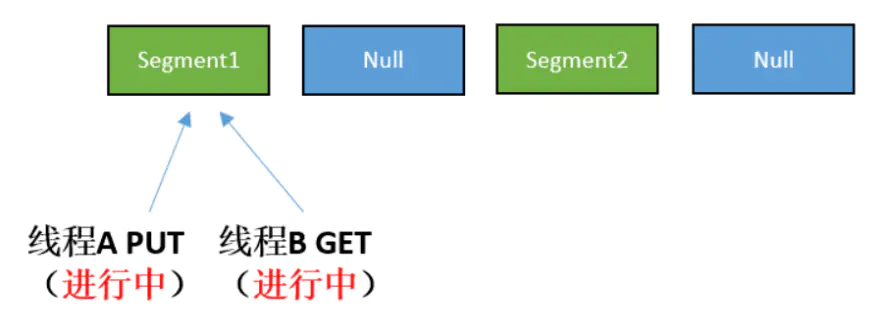
Case3:同一 Segment 的并发写入【需要上锁】
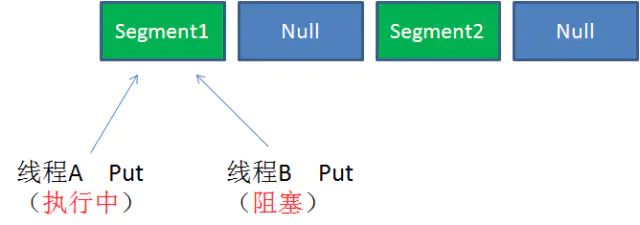
由此可见,ConcurrentHashMap 当中每个 Segment 各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
2️⃣Concurrent 的读写过程
Get方法:
- 为输入的 Key 做 Hash 运算,得到 hash 值。(为了实现Segment均匀分布,进行了两次Hash)
- 通过 hash 值,定位到对应的 Segment 对象
- 再次通过 hash 值,定位到 Segment 当中数组的具体位置。
Put方法:
- 为输入的 Key 做 Hash 运算,得到 hash 值。
- 通过 hash 值,定位到对应的 Segment 对象
- 获取可重入锁
- 再次通过 hash 值,定位到 Segment 当中数组的具体位置。
- 插入或覆盖 HashEntry 对象。
- 释放锁。
从步骤可以看出,ConcurrentHashMap 在读写时均需要二次定位。首先定位到 Segment,之后定位到 Segment 内的具体数组下标。
二、每一个 Segment 都各自加锁,那么在调用 size() 的时候,怎么解决一致性的问题
1️⃣调用 Size() 是统计 ConcurrentHashMap 的总元素数量,需要把各个 Segment 内部的元素数量汇总起来。但是,如果在统计 Segment 元素数量的过程中,已统计过的 Segment 瞬间插入新的元素,这时候该怎么办呢?

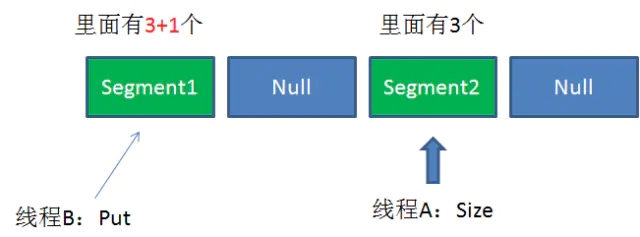

2️⃣ConcurrentHashMap 的 Size() 是一个嵌套循环,大体逻辑如下:
- 遍历所有的 Segment。
- 把 Segment 的元素数量累加起来。
- 把 Segment 的修改次数累加起来。
- 判断所有 Segment 的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
- 如果尝试次数超过阈值,则对每一个 Segment 加锁,再重新统计。
6.再次判断所有 Segment 的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。 - 释放锁,统计结束。
官方源代码如下:


为什么这样设计呢?这种思想和乐观锁悲观锁的思想如出一辙。为了尽量不锁住所有的 Segment,首先乐观地假设 Size 过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有 Segment 保证强一致性。
三、ConcurrentHashMap(线程安全)
- 底层采用分段的数组+链表实现
- 通过把整个 Map 分为N个 Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于 HashEntry 的 value 变量是 volatile 的,也能保证读取到最新的值。)
- Hashtable 的 synchronized 是针对整张 Hash 表的,即每次锁住整张表让线程独占,ConcurrentHashMap 允许多个修改操作并发进行,其关键在于使用了锁分离技术。
- 有些方法需要跨段,比如 size() 和 containsValue(),它们可能需要锁定整个表而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
- 扩容:段内扩容(段内元素超过该段对应 Entry 数组长度的75%触发扩容,不会对整个 Map 进行扩容),插入前检测是否需要扩容,避免无效扩容。
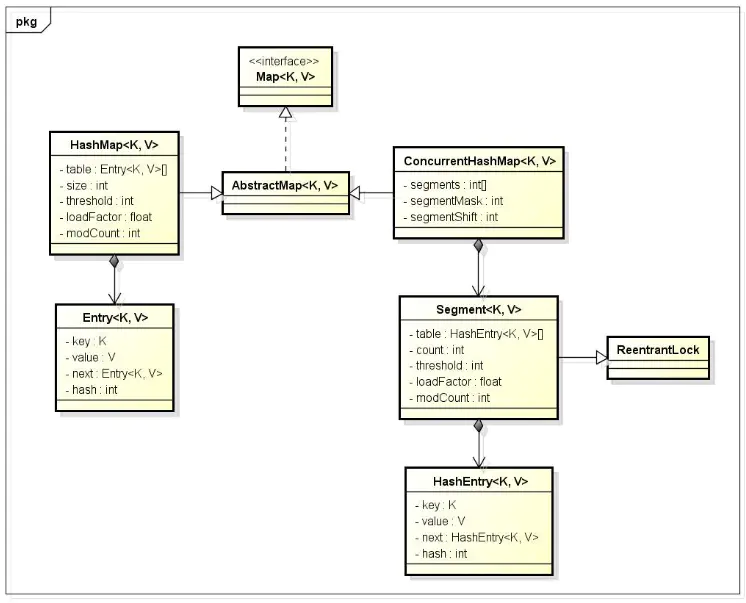
从类图可看出在存储结构中 ConcurrentHashMap 比 HashMap 多出了一个类 Segment,而 Segment 是一个可重入锁。ConcurrentHashMap 是使用了锁分段技术来保证线程安全的。
锁分段技术:
首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据仍能被其他线程访问。
ConcurrentHashMap 提供了与 Hashtable 和 SynchronizedMap 不同的锁机制。Hashtable 中采用的锁机制是一次锁住整个 hash 表,从而在同一时刻只能由一个线程对其进行操作;而 ConcurrentHashMap 中则是一次锁住一个桶。
ConcurrentHashMap 默认将 hash 表分为16个桶,诸如 get、put、remove 等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
四、ConcurrentHashMap 1.7和1.8的区别
1️⃣整体结构
1.7:Segment + HashEntry + Unsafe
1.8: 移除 Segment,使锁的粒度更小,Synchronized + CAS + Node + Unsafe
2️⃣put()
1.7:先定位 Segment,再定位桶,put 全程加锁,没有获取锁的线程提前找桶的位置,并最多自旋 64 次获取锁,超过则挂起。
1.8:由于移除了 Segment,类似 HashMap,可以直接定位到桶,拿到 first 节点后进行判断:①为空则 CAS 插入;②为 -1 则说明在扩容,则跟着一起扩容;③ else 则加锁 put(类似1.7)
3️⃣get()
基本类似,由于 value 声明为 volatile,保证了修改的可见性,因此不需要加锁。
4️⃣resize()
1.7:跟 HashMap 步骤一样,只不过是搬到单线程中执行,避免了 HashMap 在 1.7 中扩容时死循环的问题,保证线程安全。
1.8:支持并发扩容,HashMap 扩容在1.8中由头插改为尾插(为了避免死循环问题),ConcurrentHashmap 也是,迁移也是从尾部开始,扩容前在桶的头部放置一个 hash 值为 -1 的节点,这样别的线程访问时就能判断是否该桶已经被其他线程处理过了。
5️⃣size()
1.7:很经典的思路:计算两次,如果不变则返回计算结果,若不一致,则锁住所有的 Segment 求和。
1.8:用 baseCount 来存储当前的节点个数,这就设计到 baseCount 并发环境下修改的问题。
作者:日常更新
链接:https://www.jianshu.com/p/78989cd553b4
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号