Mybatis源码分析
一段独立运行的mybatis代码,将文件读取成流这一步暂时略过。![]()

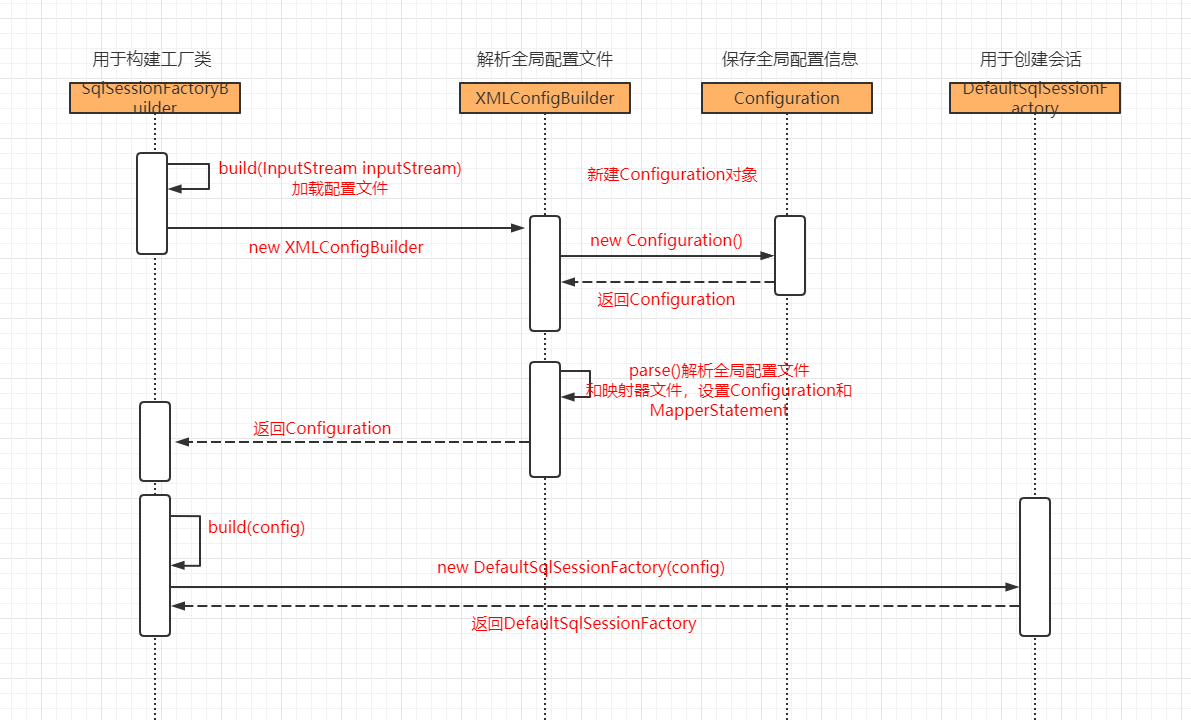
一,创建一个工厂类
完成config配置文件,mapper文件,mapper接口上的注解的解析,得到了一个Configuration对象。最后返回了一个DefaultSqlSessionFactory,里面持有了Configuration的实例。
typeAliasRegistry.registerAlias(alias, clazz); 别名和类的转换
interceptorChain.addInterceptor(interceptor); 加载插件
typeHandlerRegistry.register(javaTypeClass, typeHandlerClass); java类型和数据库类型转换
mappedStatements.put(ms.getId(), ms); 解析Mapper文件,将namespace+"."+statementId拼接作为Id,将statement的参数,sql语句什么的封装为MappedStatement对象
mapperRegistry.addMapper(type); 它里面调用了knownMappers.put(type, new MapperProxyFactory<>(type)); 将mapper类和一个代理对象绑定。
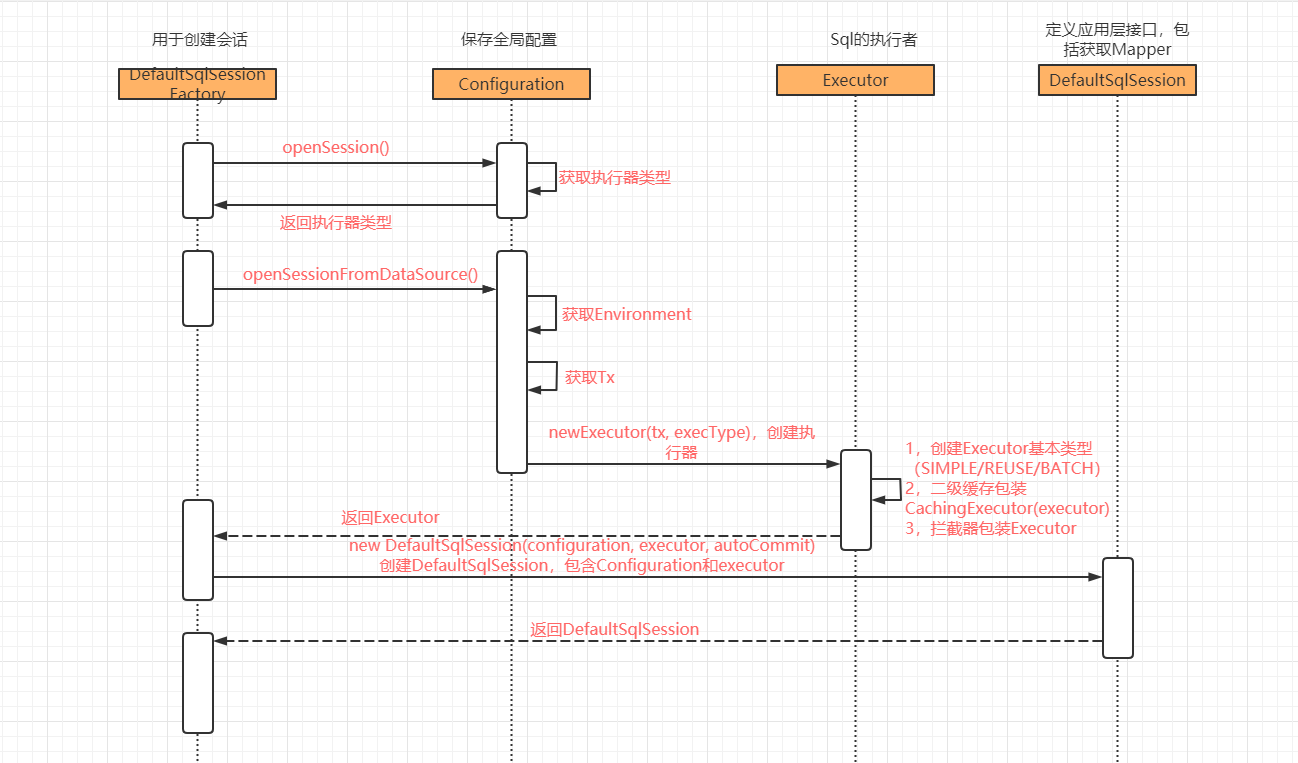
二,创建一个SqlSession
建立一个会话(工厂设计模式),每个会话都有一个Executor用来执行Sql,Executor又要指定事务类型和执行器类型,事务类型有两种:JDBC(交给JDBC事务管理)和MANAGED(交给容器管理)。
执行器有三种:Simple,Batch,Reuse默认是Simple,他们都继承于抽象类BaseExecutor(模板的设计模式)
SimpleExecutor:每执行一次select或者update都开启一个Statement对象,用完就关闭。
ReuseExecutor:执行select或者update的时候以sql作为key去map里面找Statement是否已经存在,存在就使用,不存在新建,不关闭Statement对象,而是放在Map中。
BatchExecutor:执行update(不支持select)的时候,将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象。与JDBC批处理相同。
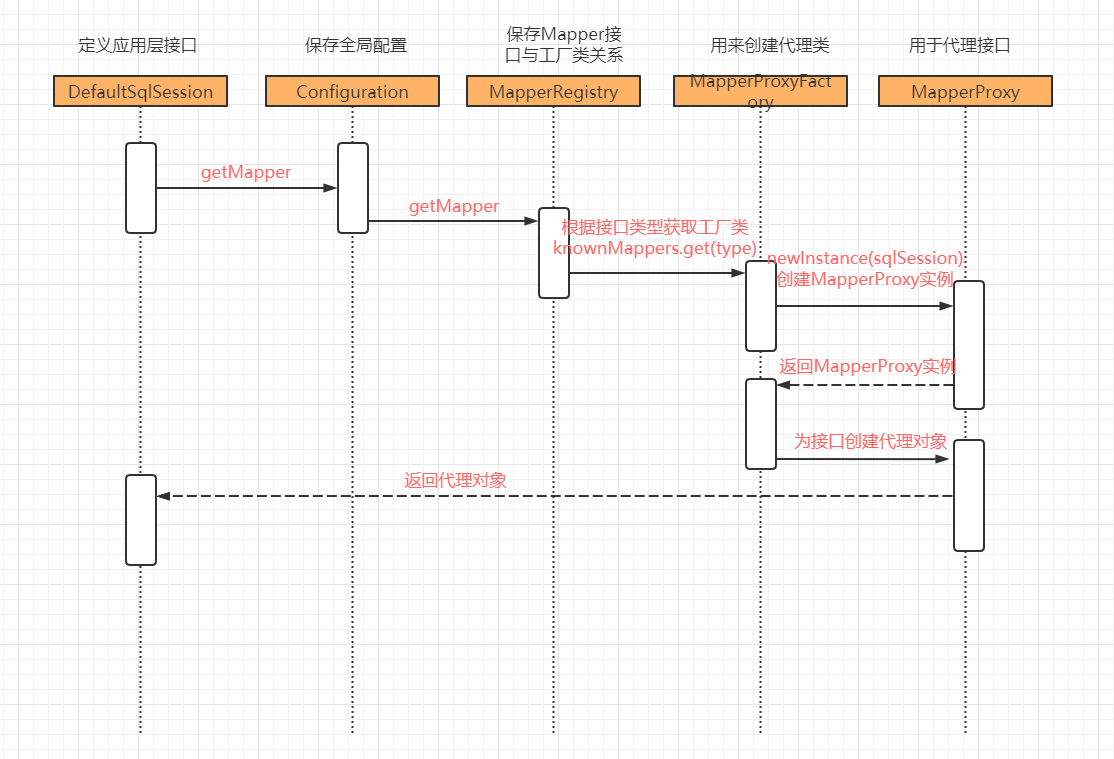
三,获得一个Mapper对象
获取到session之后,那么找到对应的statementId获取到sql就可以执行了,一种是硬编码的方式,我们常用的是Mapper接口的方式。
我们第一步的时候我们将类和代理对象进行了绑定,knownMappers.put(type, new MapperProxyFactory<>(type)); 这一步我们可以获取到接口的代理对象MapperProxy。
MapperProxy中有SqlSession,mapperInterface,methodCache。
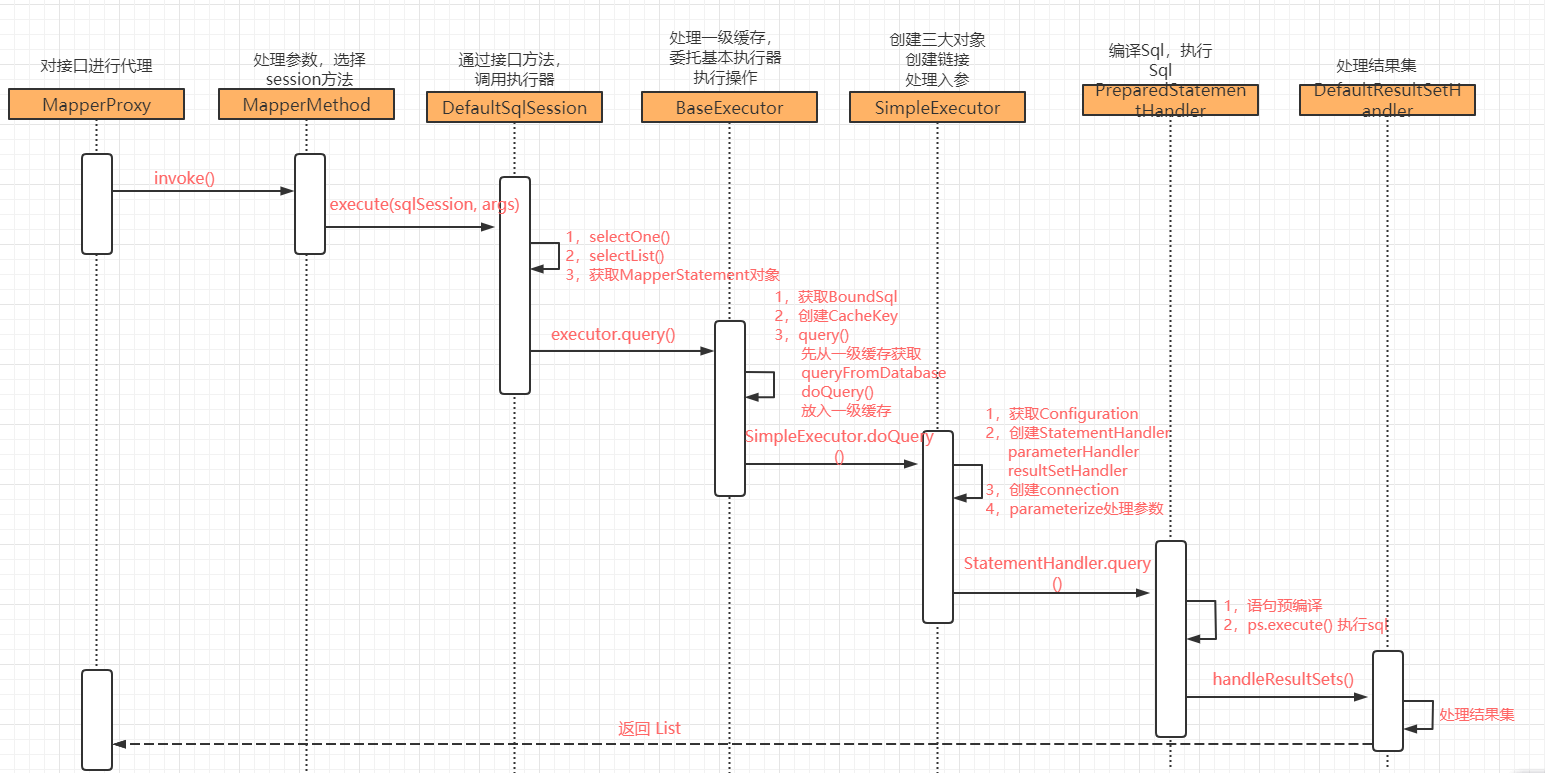
四,调用接口方法
由于所有的Mapper都被MapperProxy对象代理,所以调用Mapper的方法首先执行的是MapperProxy中的invoke()方法。
先从mappedStatements中根据statementid拿到MapperStattement对象,这个对象中包含了sql语句,出参,入参等参数。然后执行query()方法。这时候如果有二级缓存则先调用CachingExecutor中的query,再执行基本类型的执行器。然后BaseExecutor中先从一级缓存中取,取不到数据从数据库中取然后放入一级缓存中。
从数据库中获取的时候,首先会使用默认的SimpleExecutor执行器创建StatementHandler对象,这里面会同时创建parameterHandler和resultSetHandler对象,然后创建Connection,处理参数,最后调用statementHandler中的query方法编译执行sql语句。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号