
MySQL索引培训01
场景描述
假设表TB1001中有300行记录,ID列数据分布从1递增至300,C1列数据分布从1001至1100,其表结构如下:
CREATE TABLE TB1001(
ID INT NOT NULL PRIMARY KEY AUTOINCREMENT,
C1 INT NOT NULL,
C2 VARCHAR(200),
INDEX IDX_C1(C1)
)
对于主键索引,非叶子节点存放主键索引列(ID)和执行下一级页面的指针,叶子节点存放所有列数据(溢出列除外),假设每个叶子节点数据页(16KB)能存在300条记录,其存储为:
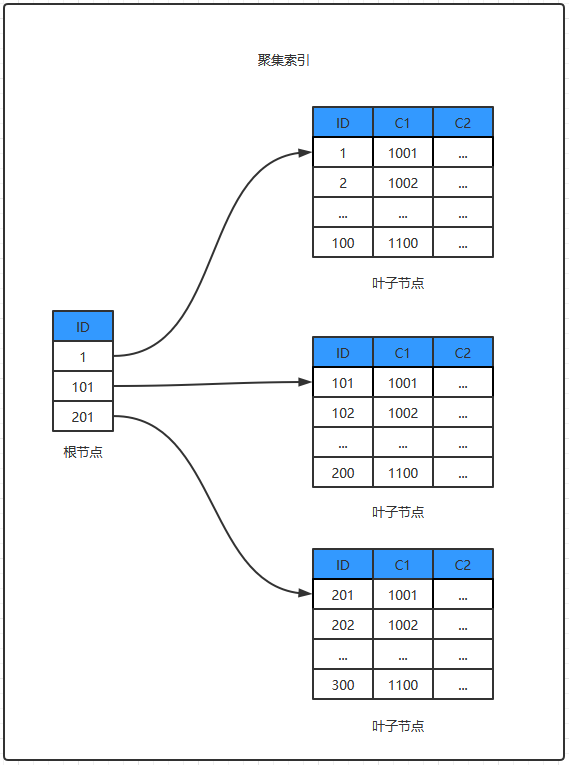
PS:主键索引的叶子节点还存放事务版本号和事务回滚指针,为避免干扰所以上图未展示。
对于非主键索引IDX_C1(C1),非叶子节点存放索引列(C1)和执行下一级页面的指针,叶子节点存放索引列(C1)和主键列(ID),假设每个叶子节点数据页(16KB)能存在500条记录,其存储为:
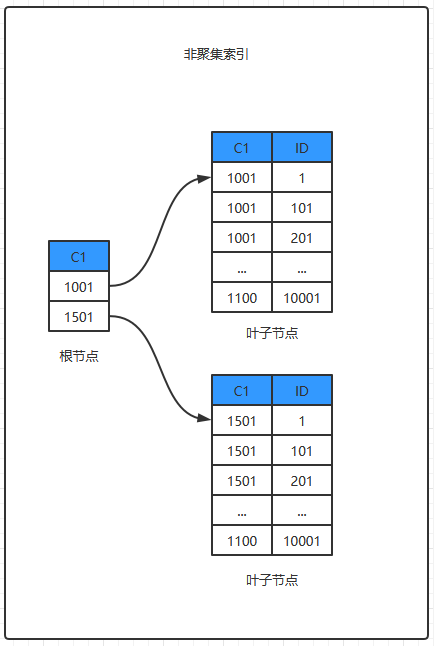
覆盖索引
假设有查询:
SELECT ID,C1
FROM TB1001
WHERE C1=1001
其执行步骤为:
1、解析SQL,生成执行计划(利用索引IDX_C1)
2、访问索引IDX_C1的根节点,找到存放C1=1001的叶子节点
3、根据索引IDC_C1在C1列上有序存储特性,快速找到第一条C1=1001的记录
4、从第一条C1=1001的记录开始顺序扫描到第一条C1!=1001的记录
5、将步骤4中找到记录当做查询结果集返回客户端
由于查询只需要获取ID+C1两列数据,而步骤4中获取的到索引数据包含C1+ID两列数据,因此查询仅需要通过索引IDX_C1即可完成,此索引对该SQL可成为覆盖索引。
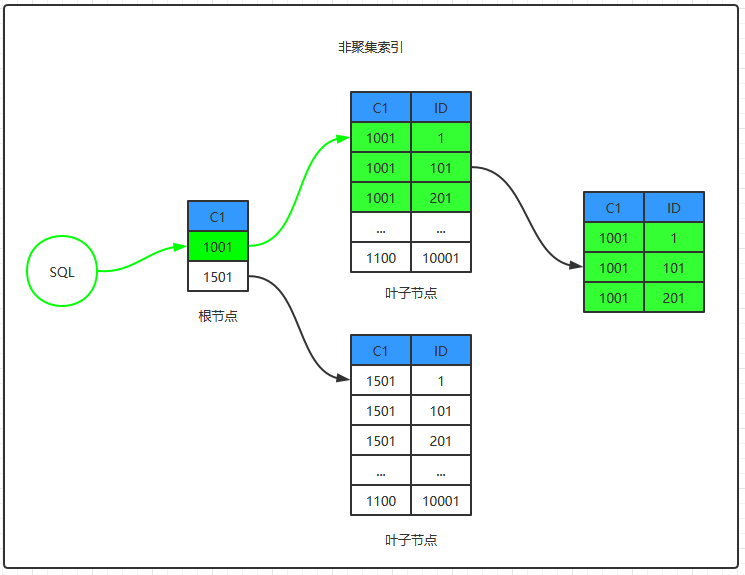
回表查找
假设有查询:
SELECT ID,C1
FROM TB1001
WHERE C1=1001
其执行步骤为:
1、解析SQL,生成执行计划(利用索引IDX_C1)
2、访问索引IDX_C1的根节点,找到存放C1=1001的叶子节点
3、根据索引IDC_C1在C1列上有序存储特性,快速找到第一条C1=1001的记录
4、从第一条C1=1001的记录开始顺序扫描到第一条C1!=1001的记录
5、步骤4中第一条满足条件记录(C1,ID)的值为(1001,101),没有C2的数据,需要访问主键索引。
6、访问主键索引的根节点,找到存放ID=101的叶子节点
7、从主键索引叶子节点找到ID=101的数据记录,放入临时结果集
8、循环步骤4中匹配的索引记录执行5、6、7步
9、将临时结果集当做查询结果集返回客户端
步骤1-4步如图:
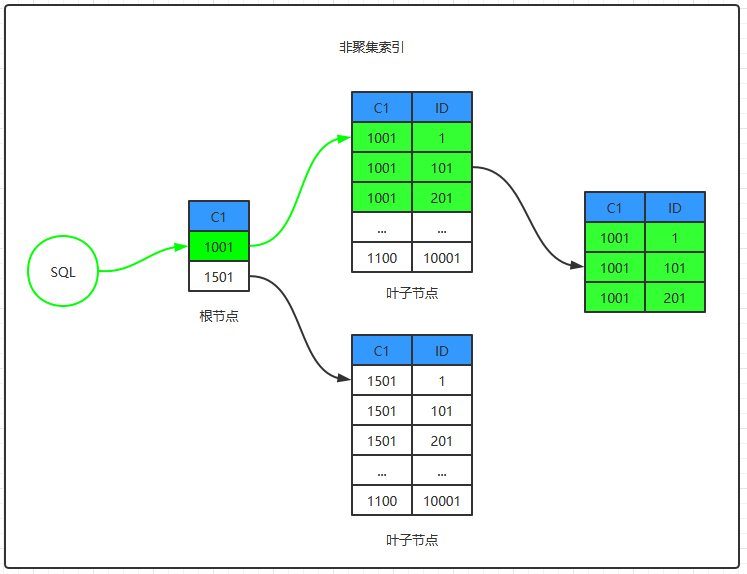
步骤5-9步如图:
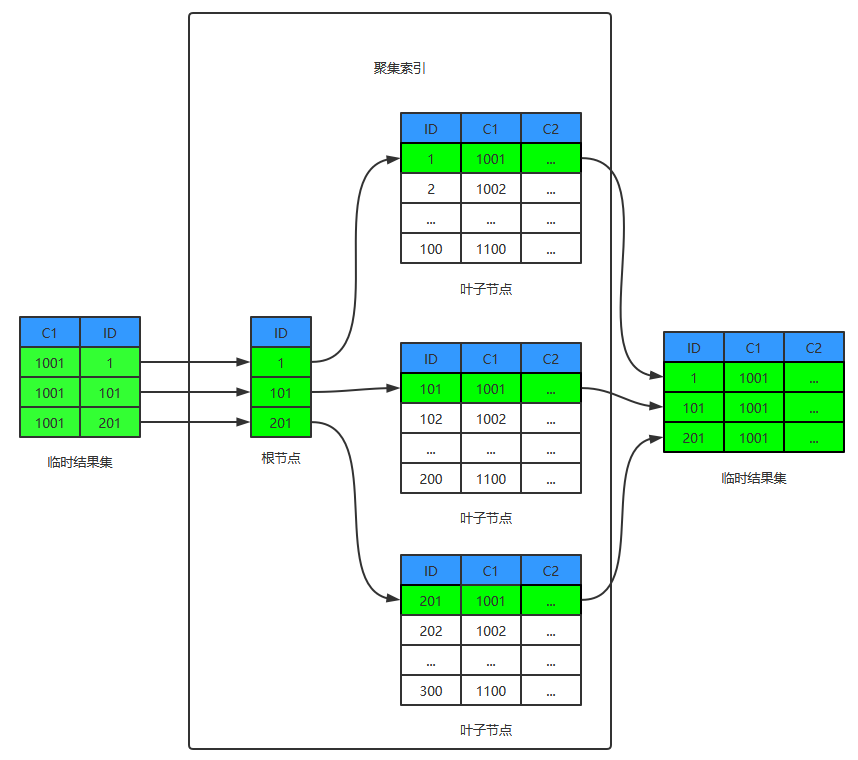
针对扫描非聚集索引得到的每条记录,都需要按照主键值在聚集索引上执行一次主键查找,此过程被称为回表查找。
回表查找的性能影响:
以上面查询为例,通过索引IDX_C1找到满足条件的三条记录,需要循环三次主键查找,每次主键查找访问N(主键索引层数)个数据页。当需要访问的数据页在"数据库缓存(Buffer Pool)"中存在,则无需从物理存储中读取,操作访问速度极快,此类型读取被称为逻辑读取。当需要访问的数据页在"数据库缓存(Buffer Pool)"中不存在,则需要先从物理存储读取并加载到"数据库缓存(Buffer Pool)"中,受限于物理存储性能,操作速度相对较慢,此类型读取被称为物理读取。
在很多业务场景中,回表查找的数据往往分布在不同的主键索引叶子节点上,上面查询的三条记录分别位于三个叶子节点数据页中,当大量需要访问的叶子节点数据页需要被"物理读取"且这些叶子节点分散存放在主键索引上,就会产生大量的随机物理IO操作,严重消耗数据库服务器CPU和IO资源,影响数据库服务器整体性能。
复合索引
在关系型数据库中,将只包含一个索引列的索引称为单列索引,将包含多个索引列的索引称为复合索引。
有100万个学生,50万个班级,每个学生报名学习50至200个课程,每个班级包含100至400个学生,约1亿条学生课程记录,该信息由学生课程表来存储:
CREATE TABLE class_student(
id bigint primary key auto_increment,
student_id bigint not null comment '学生编号',
class_id bigint not null comment '课程',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间',
is_del tinyint not null comment '是否删除'
)
有业务需要查询某学生时是否报名某课程,查询SQL为:
SELECT *
FROM class_student
WHERE student_id=286375
AND class_id=13357
AND is_del=0
对于此查询,有三种索引创建方案:
- 在学生编号(student_id)上创建索引,根据此索引找到满足student_id条件的记录,再对主键索引进行50至200次回表查询。
- 在班级编号(class_id)上创建索引,根据此索引找到满足class_id条件的记录,再对主键索引进行100至400次回表查询。
- 在班级编号+学生编号上创建索引,根据此索引找到满足class_id+student_id条件的记录,再对主键索引进行0至1次回表查询。
相对"无索引全表扫描"的情况,上面三种方案都能极大提升查询性能,复合索引的方案将回表查询次数降低到最低,使得查询的性能最优。
在实际业务中,学生报名课程又取消的场景较低,大部分的记录都满足is_del=0的条件,且查询需要返回所有列数据,因此将is_del放入符合索引中对查询性能不会有太明显提升,反而会增加索引宽度和索引增删改时的维护成本。
思考问题:假如有业务需要频繁查询某班级的有效学生人数,如每次学生参加课程时都查询该班级的有效学生人数,查询SQL为:
SELECT COUNT(1) AS student_count
FROM class_student
WHERE class_id=13357
AND is_del=0
该如何优化?

