


kafka
本文记录一些对kafka的学习总结。
https://zhuanlan.zhihu.com/p/146913653
1.kafka架构
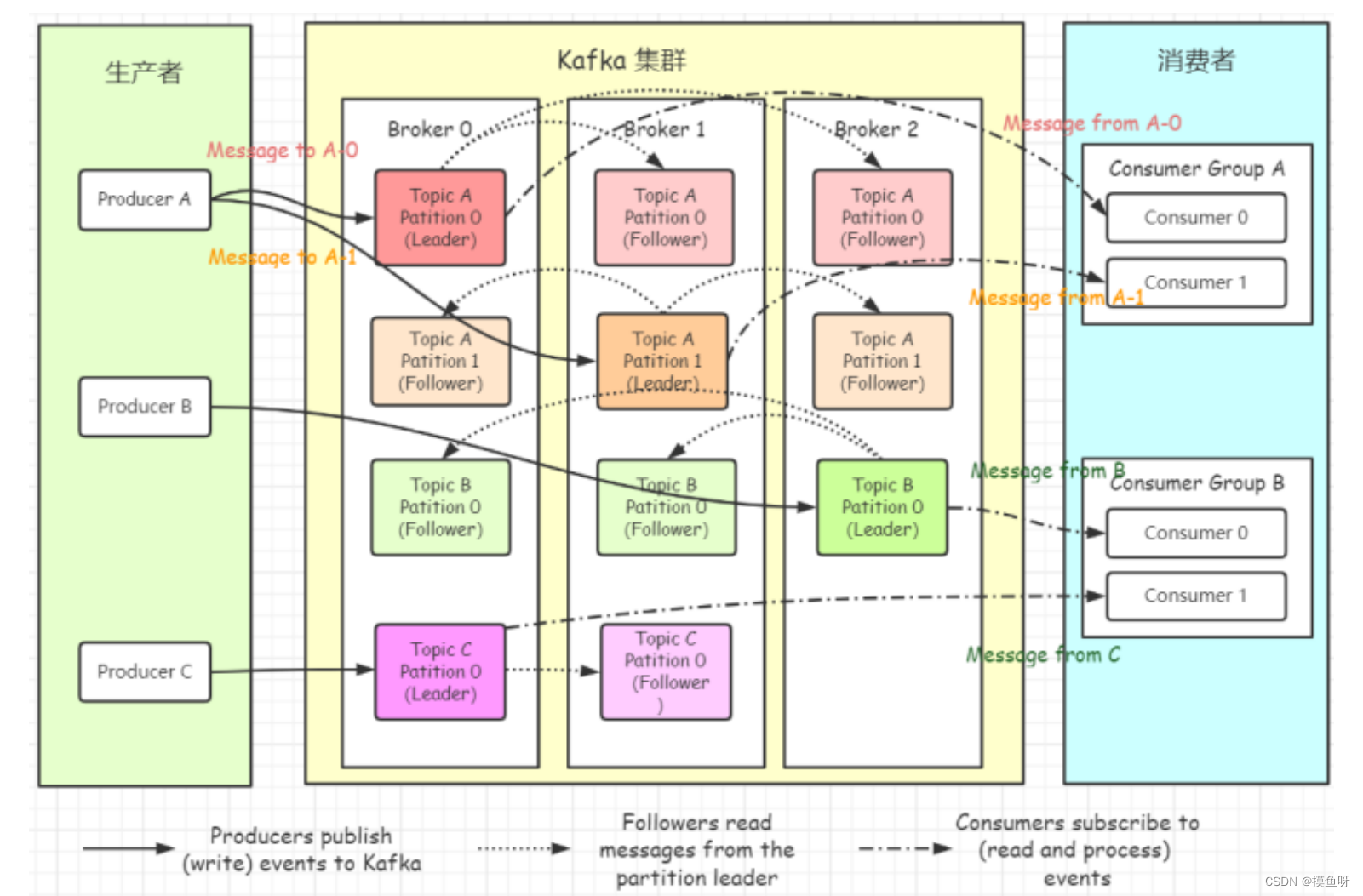
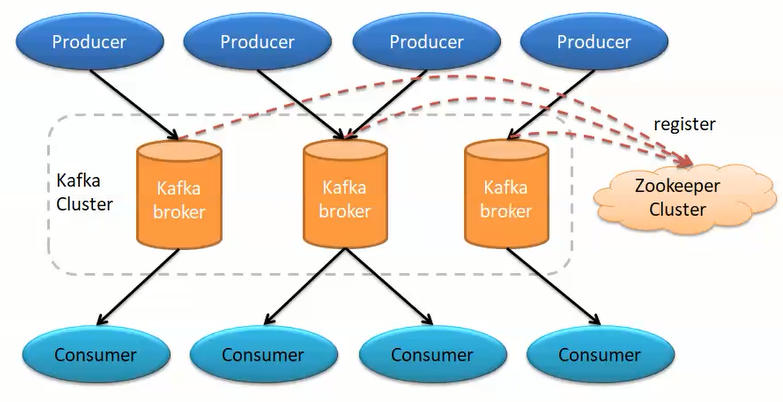
- topic,主题。用于划分消息所属类别。相当于消息的标签。
- partition,分区。topic中消息被划分到一个或者多个partition,是一个物理概念,对应到系统上就是一个或者多个目录。partition本身是一个FIFO队列,消息有序,但是多个partition间无法保证消息的顺序性。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
- replicas of partition,分区副本。副本是分区的一个备份。只是为了防止消息丢失而创建的分区的备份,不好被消费者消费。即消费者不会从follower的分区中消费数据,而是从leader的分区中读取数据。
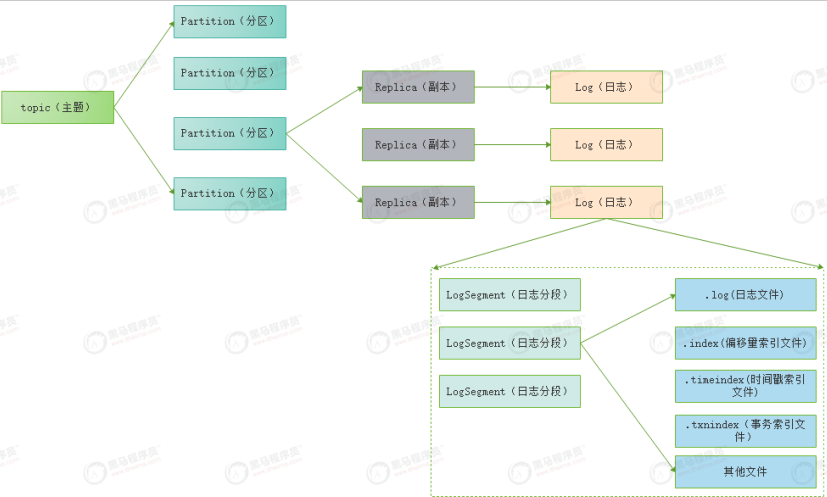
- segment,段。将partition进一步细分了若干个segment,每个segment文件的最大大小相等。
- broker。kafka集群包含一个或者多个服务器,每个服务器节点称为一个broker。topic的partition数量是N,broker的数量是M。若N%M=0,每个broker分N/M个partition,若N%M !=0,或者N<M,则分区在broker上分布不均匀。
- producer,生产者,将某topic消息发布到相应的partition。生产者可以指定数据存储的partition。
- consumer,消费者,从broker中读取消息。可以读多个topic消息,也可以读一个topic下的多个分区内消息。一个分区允许多个无关消费者同时消费。
- consumer group,消费者组。多个消费者共享一个groupID。组内消费者协调一起平均消费订阅主题的所有分区。组内 consumer 与 partition 的关系 1:n ,partition 与组内 consumer 的关系 1:1。这种设计方式的好处是: 实现简单, 弊端是: 消息分配不均。consumer 只能分配到一个组。
- partition leader ,每个分区有多个副本,其中有且只有一个作为leader,leader 是当前负责消息读写的partition。即所有读写操作只能发生于leader分区上。
- partition follower,所有follower都要从leader上同步消息,与leader是主备关系,只是备份数据。
- partition offset ,偏移量。每条消息都有一个当前partition下唯一的64字节的offset,它是相对于当前分区第一条消息的偏移量,分区内单调递增。
- offset commit ,consumer消费完消息后,自动或者手动将消息的offset提交到broker,让broker记录消费过的消息。提交的offset被写入到一个特殊的主题 _consumer_offsets中,表示消费完成。
- AR(Assigned Replicas) :分区中的所有副本(包含leader副本)统称AR;ISR(In-Sync-Replicas)所有与Leader部分保持一致的副本组成ISR;OSR(Out-Of-Sync-Replicas):与Leader副本同步滞后过多的副本
- zookeeper,负责维护和协调broker,当kafka系统中新增了broker或者某个broker发生故障,由zookeeper通知生产者和消费者。生产者和消费者依据zookeeper的broker状态信息与broker协调数据的发布和订阅任务。负责broker controller的选举。
- Rebalance,再均衡。当消费者组中的消费者数量发生变化,或者topic的partition数量发生变化,partition会重新分配,这个过程称为再均衡。好处:给消费者组合broker集群带来高可用性和伸缩性。坏处:期间消费者无法读取消息,即整个broker集群有小段时间不可用,因此要避免不必要的再均衡。
- HW,HighWatermark,高水位,表示consumer可以消费的最高的partition偏移量。HW保证了kafka集群中leader分区与follower分区中消息的一致性。也就是说leader中的消息只有同步到follower后才能被consumer看到,HW就是已经同步到follower的最高的偏移量。对于leader新写入的消息,只有同步到ISR中的所有follower后才会更新HW,此时才能被consumer消费。故障切换的时候会有消息丢失,因为HW后面的还未同步到ISR的想消息就丢失了
- LEO,Log End Offset,日志最后消息的偏移量。最后一个写入partition日志中的消息的偏移量。
- broker controller,kafka集群的多个broker中,有一个被选举为controller,负责管理整个集群中的partition和副本replica的状态。当partitionleader 宕机后,broker controller会从ISR中选举出一个Follower作为新的leader。所谓选举就是从ISR中找到第一个follower,直接让其当选新的leader。broker controller是有zk选举出来的。
- coordinator,一般指的是运行在每个 broker 上的 group Coordinator 进程,用于管理 Consumer Group 中的各个成员,主要用于 offset 位移管理和 Rebalance。 一个 Coordinator 可 以同时管理多个消费者组
2.如何保证可靠性传输?
消费端丢失:
- 自动提交:消费者把poll到的消息消费完成之后需要把消息的offset提交到broker的内部主题 consumer_offset,表示这个消息消费完成。消费者客户端参数enable.auto.commit 默认为true表示自动提交,通过auto.commit.interval.ms配置(默认值为5秒)定期提交时间间隔。自动提交的动作是在poll方法的逻辑里面完成的,每次向服务器拉取请求前检查是否可以进行位移提交,如果可以,就会提交上一次轮询的位移。
- 自动提交造成的问题: 可以通过手动提交解决
- 重复消费:消费者在提交之前宕机了,重启后上次没有提交位移的消息就会被重新拉取进行消费。
- 消息丢失:有可能上次poll到的消息还没有消费完,就全部提交位移了。但是此时还有消息没消费完,如果发生异常或者宕机,就会导致没有消费的消息被自动提交了,造成消息丢失。
- 手动提交:enable-auto-commit设置为false。编写手动提交代码。kafka的客户端 或者springboot整合kafka的客户端。同步提交,异步提交
生产端丢失:
- 生产者客户端发送消息流程
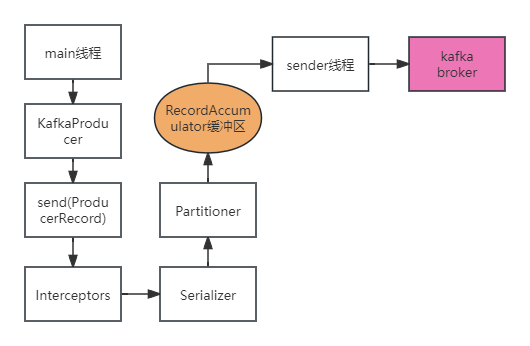
- 在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量—— RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程会根据指定的条件,不断从RecordAccumulator中拉取消息发送到Kafka broker。sender线程拉取消息的条件是:缓冲区大小达到阈值(默认16384字节),或者缓冲区等待时间达到阈值(默认0,可以发送)。分别通过参数spring.kafka.producer.batch-size ,linger.ms设置。哪个条件先达到sender就拉取消息发送。
- KafkaProducer发送消息的方式有三种:
- 发送消息后,不管是否到达,不会等待kafka的响应,其实消息只发送到缓冲区。可能造成消息丢失,可靠性差尤其是不可重试时,但是性能最高。
- 代码:kafkaTemplate.send("itheima" , msg)
- 同步发送消息,阻塞等待kafka消息的响应
- 代码:kafkaTemplate.send("itheima" , msg).get() ;send方法返回的是ListenableFuture。性能差,可靠性好。
- 异步发送,在send方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。性能好,可靠性有保障
- 发送消息后,不管是否到达,不会等待kafka的响应,其实消息只发送到缓冲区。可能造成消息丢失,可靠性差尤其是不可重试时,但是性能最高。
- 生产端可以选择发送消息的可靠级别,通过acks参数设置
- 设置0,异步发送,生产者向 kafka 发送消息而不需要 kafka 反馈成功 ack,也就不会重试。该方式效率最高,但可靠性最低。其可能会存在消息丢失的情况。
- 设置1(默认),同步发送,broker 的 partition leader 在收到消息后 马上发送成功 ack (无需等待 ISR 中的 follower 同步完成),生产者收到后知道消息发送成功, 然后会再发送消息。如果一直未收到 kafka 的 ack,则生产者会认为消息发送失败,会重发 消息。retries可以设置重试次数,一直没有ack,就抛出异常。
- 设置-1或者all,同步发送,生产者发送消息给 kafka, kafka 收到消息后要等到 ISR 列表 中的所有副本都同步消息完成后,才向生产者发送成功 ack。如果一直未收到 kafka 的 ack, 则认为消息发送失败,会自动重发消息。
- 设置0,异步发送,生产者向 kafka 发送消息而不需要 kafka 反馈成功 ack,也就不会重试。该方式效率最高,但可靠性最低。其可能会存在消息丢失的情况。
broker服务器:
- 给topic设置replication.factor参数大于1,要求每个partition必须最少有两个副本
- 搭建Kafka集群,让各个分区副本均衡的分配到不同的broker上
重要参数: max.in.flight.requests.per.connection设置为1,该参数指定了生产者在收到服务器响应之前可以发送多 少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设 为 1 可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。会影响生产端的吞吐量,只有严格要求顺序的时候才这么做。
3.如何保证消费幂等?
消息的重复发送或者重复消费会破坏消费幂等性。
- 生产端重复发送消息:生产者发送消息后没有得到broker正确的响应,有可能是broker落盘以后因为网络等原因,生产者得到一个发送失败的响应或者是网络中断,然后producer收到一个可恢复的Exception重试消息导致消息重复。
- 解决方案1:消息重复是由于不稳定网络下的重试造成的,那么retries设置0,不进行重试。不过这样可能丢失消息。适用于一些吞吐量要求高于数据丢失的场景,比如日志收集。
- 解决方案2:生产端启动kafka幂等机制,设置enable.idempotence 为true启动幂等。
- 启动幂等性后,对参数retries,acks,max.in.flight.requests.per.connection的配置是有要求的。否则会抛出异常
- retries的值必须是大于 0 ;max.in.flight.requests.per.connection的值不能大于5;acks的取值需要设置为-1/all
- 幂等性原理:每个生产者初始化一个pid,生产者每发送一条消息就会将<PID , 分区>对应的序列号的值加1,broker端会在内存中为每一对<PID , 分区>维护一个序列号。对比序列号大小判断消息是否重复:SN_new = SN_old + 1时,broker才接收它;SN_new < SN_old + 1,那么说明消息被重复写入,broker可以直接将其丢弃;SN_new > SN_old + 1,出现乱序,暗示可能有消息丢失,对应的生产者会抛出OutOfOrderSquenceException,是一个严重异常
- 根据这个幂等性原理,我们可以知道,kafka的幂等性机制不能跨分区实现,只能保证单生产者单分区的幂等。
- 消费端重复消费消息:消费完成后,还没有及时提交到broker,出现异常或者宕机,导致下次重复消费。
- 解决方案:取消自动提交改成每次消费完手动提交,或者是做幂等处理,不怕重复消费。
5.kafka中的事务机制?
kafka中的幂等性不能保证跨分区的幂等。事务机制可以弥补,保证对多个分区写入操作的原子性,事务中的消息具有事务特性,事务中的多个操作要么全部成功要么全部失败。
为了实现事务,应用程序必须保证唯一transactionalId,通过客户端参数设置事务id前缀,spring.kafka.producer.transaction-id-prefix=order_tx. # 表示开启事务机制
事务机制的使用需要幂等性的支持,所以我们还需要开启幂等性:enable.idempotence = true,不开启会报错。#kafkaTemplate.executeInTransaction()
5.如何保证消息顺序性?
如果topic下有多个分区,且消息分散在多个分区内,是无法保证顺序性的。要想严格保证顺序性:
- 创建topic的时候指定只有一个分区。另外需要保证一个消费者单线程消费。
- 生产者向topic发送消息的时候指定分区id。另外需要保证一个消费者单线程消费。
带原状态更新可以一定程度避免顺序不一致造成的影响。
6.如何保证高可用?
- 搭建消息队列集群架构,且不同副本放在不同的机器上。故障自动迁移,如果leader节点宕机,会从ISR中选择第一个可用节点作为leader节点。
- 使用kafka eagle 搭建集群监控工具,及时发现问题。
-
集群中增加机器了,需要手动对已有主题进行分区分配,或者修改副本数量,实际生产环境用的还是比较多。工具:kafka-reassignpartitions.sh
7.如何处理消息积压?
- 监控和告警:设置合理的告警阈值,当消息积压达到一定程度时及时发出告警,以便快速响应和处理
- 水平扩展消费者:消费者数量增多,则可以并行提升消息消费的速度,从而避免消息积压的问题。
- 优化消费者处理速度:提升消费者的消费速度也可以避免消息积压的问题,它的解决方案有:
- 优化消费者处理消息的逻辑,减少不必要的计算和 I/O 操作。
- 对于可以并行处理的任务,使用多线程或异步处理来提高吞吐量。
- 限流生产者和使用背压机制:
- 在生产者端实施限流策略,确保消息产生的速度不会超过系统的处理能力。
- 使用背压机制,即当消息队列达到某个阈值时,通知生产者降低发送速率或暂停发送。
8.kafka为什么这么快?
kafka消息是被存储到磁盘的,rabbitmq使用内存和磁盘的方式存储消息;按说rabbitmq消息吞吐量应该大于kafka,为啥kafka的消息吞吐量反而大于rabbitmq那么多呢?
- 分区管理,kafka将主题划分为多个分区,会根据分区规则决定将消息存储到哪个分区中,分区规则合理的话,所有消息都可以均匀的分布到不同的分区,不仅实现了负载均衡和水平扩展,大大提高了消息读写的吞吐量,因为一个主题的消息可以同时写入多个分区,不同订阅者可以从一个或者多个分区中同时消费消息,支持海量数据处理。消息是以追加的方式存储到多个分区,多个分区顺序写磁盘的总效率要比随机写内存的效率高,这是kafka高吞吐率的重要保证之一。
- 存储方式:
- 基于磁盘:kafka支持大数据量的写入写出,kafka服务使用scala和java编写,如果基于内存存储就要JVM分配很大的堆内存支持大量读写,从而导致GC频繁影响性能。kafka基于磁盘顺序读写和MMAP技术实现高性能
- 存储结构:一个topic有一个或者多个分区,每个分区有一个或者多个副本。消息存储在日志文件中,为了防止文件过大,副本中的消息是分段存储的,叫LogSegment,便于消息的维护和清理。分区的消息日志在文件夹 主题名-分区id下。log中的消息是顺序写入的,且只有最后一个logsegment才能执行写入操作,达到一定的大小创建新的logsegment,命名为第一个消息的offset填充至20位,通过配置log.segment.bytes=1073741824:默认为1G
-
消息写入:通过顺序写入。不断的对磁盘进行写入删除,会造成磁盘空间不连续有碎片,存储大文件时就要使用这些不连续的空间,读写数据时,需要不断调整磁道位置,因此就会很慢。kafka的写入是只追加的方式顺序写入,不允许修改和删除。消费者通过offset指定读取消息的位置。
- 日志清理,支持删除和压缩两种策略。一般使用删除策略,当logsegment保留超过设置时间或者log总大小超过设置阈值,就会被日志删除任务检查搜集可删除的日志分段,改成.delete文件,然后通过延迟任务删除。
- MMAP(Memory Mapped Files) ,也被简称为内存映射文件,大大提高kafka的写入速度。工作原理就是直接利用操作系统上的page cache实现文件到物理内存的直接映射,完成映射之后你对物理内存的操作会被同步到磁盘。操作系统自身有page cache,也叫os cache,操作系统自己管理,在写入磁盘的时候只需要写入os cache就行了,后面由操作系统决定什么时候真的把数据写入磁盘(每五秒检查一次是否需要将页缓存数据刷入磁盘)。其实相当于直接写内存了,又加上顺序写。快的飞起。
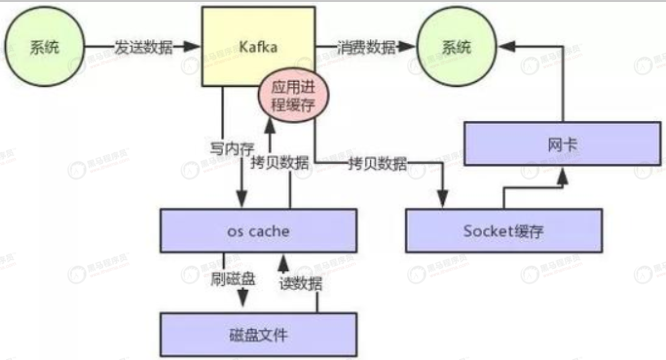
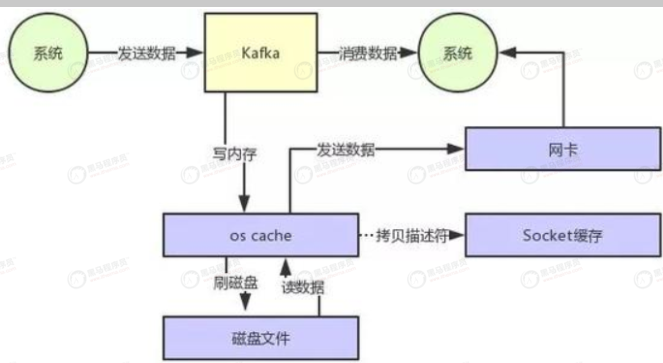
- 零拷贝:如图所示,不做优化时,发生两次数据拷贝,而且从os到应用程序,从应用程序到os,发生两次上下文切换,这样读取数据比较耗时。优化后,两次数据拷贝都没了,oscache直接发数据到网卡,只需要拷贝描述符到socket。大大提升读取性能
-
总结起来就是:发送时:异步发送给多个分区消息;写入存储:broker端进行分区管理,顺序且分段写入,MMAP技术;读取时:消费时使用零拷贝从磁盘读取。
9.kafka消息路由策略
通过API发送消息时,生产者以Record为消息发布的。Record中包含key和value,partition编号,topic。value是要发送的消息,key用于路由到partition。
- 如果指定了partition,直接写入指定的partition
- 否则,如果指定了key,对key进行hash,然后对partition数量取模,取模值就是要发送的partition编号。
- 没有partition和key,轮询发送到所有的partition。
10.生产者把消息写入broker过程
- 首先要注意:producer 不是zk的客户端,其是不能直接访问zk的producer 向 broker集群提交连接请求,其所连接上的任意 broker 都会向其发送 broker controller的通信 URL,即 broker controller 主机配置文件中的 listeners 地址。broker 是 zk的客户端可以直接访问 zk,从/controller 节点就可以读取到谁是当前 broker集群的 controller。
-
当 producer 指定了要生产消息的 topic后,其会向 broker controller 发送请求,请求当前topic 中所有 partition 的 leader 列表地址。broker 可以从 zk 的/brokers/topics/huike/0/status 节点中可以读取到该0号 partition 的leader.
-
broker controller在接收到请求后,会从zk中查找到指定topic的所有partition的leader,并返回给 producer
- producer 在接收到leader 列表地址后,根据消息路由策略找到当前要发送消息所要发送的 partition leader,然后将消息发送给该 leadere
- leader 将消息写入本地 log,并通知 ISR 中的 followers
- ISR 中的 followers 从 leader 中同步消息后向 leader 发送 ACK
- leader 收到所有 ISR 中的 followers 的 ACK后,增加 HW,表示消费者已经可以消费到该位置了。
- 当然,若leader 在等待的 followers 的 ACK 超时了,发现还有 follower 没有发送 ACK,则会将该 follower 从 ISR 中清除,然后增加 HW。
11.消费者从broker消费消息过程
- consumer 向 broker 集群提交连接请求,其所连接上的任意 broker 都会向其发送 brokercontroller 的通信 URL,即 broker controller 主机配置文件中的 listeners 地址。
- 当 consumer 指定了要消费的 topic 后,其会向 broker controller 发送 poll 请求.broker controller 会为 consumer 分配一个或几个 partition leader,并将该 partitioin 的当前 offset 发送给 consumer
- consumer 会按照 broker controller 分配的 partition 对其中的消息进行消费
- 当消费者消费完该条消息后,消费者会向 broker 发送一个该消息已被消费的反馈,即该消息的 offset
- 当 broker 接到消费者的 offset后,会更新到相应的 consumer offset 中。
- 以上过程一直重复,直到消费者停止请求消息
- 消费者可以重置 offset,从而可以灵活消费存储在 broker 上的消息
12.HW消息截断机制
如果 partition leader 接收到了新的消息, ISR 中其它 Follower 正在同步过程中,还未同步完毕时leader挂了。此时就需要选举出新的leader。若没有HW截断机制,将会导致partition
中 leader 与 follower 数据的不一致。
HW 机制解决的是 broker 集群正常运转过程中 partition的leader 与 follower 的一致性问题。而 HW 截断机制解决的是 broker 集群运行异常情况下,partition 的leader 与follower 的
一致性问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix