
四.python字符编码
1.什么是字符编码
因为计算机也是通电的,我们初中的时候学过物理电路,计算机在设计的时候也是用电路设计的,类似于灯泡的开关,只有通电或者关闭,就是说0代表不通,1代表通。所以计算机只认识0和1。
比如计算机就是个外国人,那么我们怎么和它交流呢,按照惯例,得有个翻译。这个翻译就是把我们想和计算机说的话翻译成0和1告诉计算机。这个翻译的过程就是编码的过程。
2.字符编码分类
由于计算机是美国人发明的,那就意味着只有美国人可以和计算机交流。美国人翻译用的是(ASCII编码),那么我们中国人要怎么和计算机交流呢,按照惯例,得找个中国人和计算机的翻译,如果每个国家都要和计算机交流呢,那就得找很多翻译,这个很多翻译就是字符编码的种类。
后来中国定制了GB2312编码,日本定制了Shift_JIS,韩国定制了Euc-kr,当各国都有各国的标准的时候,当很多国家用计算机进行交流的时候,就会出现冲突,就是我们常常说的乱码,后来为了统一全世界的文字,ISO(国际标准化组织)制定了一种新的编码规范,这种编码规范将全世界的文字放在一张表内,称它为"Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称"UNICODE"。
后来因为unicode常用2个字节代表一个字符,但是有的字符可能不需要2个字节的空间,在这里就造成了极大的浪费。这个时候就衍生出一种编码,根据不同的符号可变长变短,相对于unicode节省了大量的空间,这种编码我们称之为UTF-8编码,也是我们大多数常用的编码。
2.1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2.2 Unicode码
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
2.3 UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
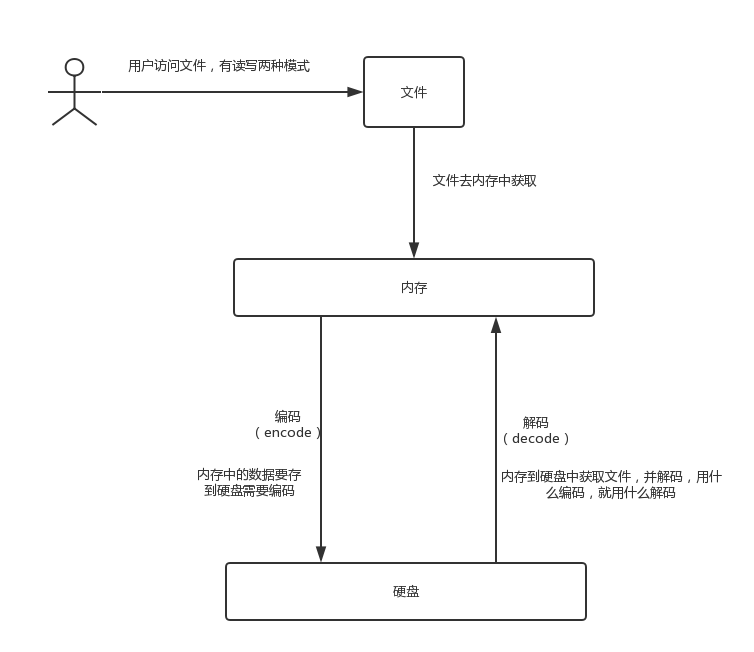
3.编码与解码
- 文件从内存刷到硬盘的操作简称存文件(编码过程)
- 文件从硬盘读到内存的操作简称读文件(解码过程)
- 用什么编码,就用什么解码,不然会出现乱码情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号