
Windows下基于python3使用word2vec训练中文维基百科语料(三)
对前两篇获取到的词向量模型进行使用:
代码如下:
1 import gensim 2 model = gensim.models.Word2Vec.load('wiki.zh.text.model') 3 flag=1 4 while(flag): 5 word = input("Please input the key_word:\n") 6 if word in model: 7 print(model['word']) 8 # 词相似度 9 result = model.most_similar(word) 10 for e in result: 11 print(e[0], e[1]) 12 else: 13 print('单词不在字典中') 14 15 flag=int(input("do you want to input next(yes=1,no=0):\n")) 16 17 #计算两个单词相似度 18 print ("水杯和水瓶的相似度为:",model.similarity('水杯','水瓶')) 19 20 #模型还提供了一个方法,用于寻找离群词: 21 print (model.doesnt_match(u"早餐 晚餐 午餐 中心".split())) 22 #我们还可以根据给定的条件推断相似词,比如下面的代码中,我们找到一个跟篮球最相关,跟计算机很不相关的第一个词: 23 print (model.most_similar(positive=['篮球'],negative=['计算机'],topn=1))
输出结果:
(1)求“漂亮”的向量:

结果:
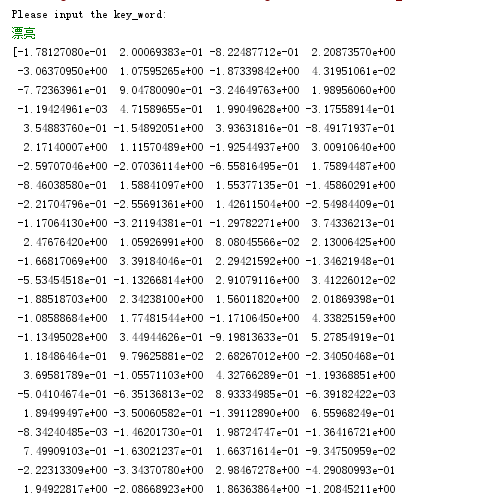
(2)输出“漂亮”的相似词,以及他们之间的相关度:

结果:

(3)输出“水杯”和“水瓶”之间的相似度:

结果:
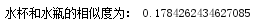
(4)寻找“离群词”

结果:

(5)根据给定的条件推断相似词:

结果:
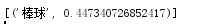
现在所有的工作就都结束啦!!!之后可以根据不同的要求来进行不同的应用啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号