
Windows下基于python3使用word2vec训练中文维基百科语料(二)
在上一篇对中文维基百科语料处理将其转换成.txt的文本文档的基础上,我们要将为文本转换成向量,首先都要对文本进行预处理
步骤四:由于得到的中文维基百科中有许多繁体字,所以我们现在就是将繁体字转换成简体字
opencc工具进行繁简转换,首先去下载opencc:https://bintray.com/package/files/byvoid/opencc/OpenCC
下载完成之后解压即可,随后使用命令:
opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json进行转换
下载完成之后解压即可,随后使用命令:
opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json进行转换
将之前获得的wiki.zh.text和解压后的opencc放在一个文件夹中,然后用上述命令执行,将转换后的简体中文保存在 wiki.zh.jian.text中
步骤五:得到简体中文文档后,对中文首先进行分词,分词采用jieba,代码如下:
1 #文章分词 2 import jieba 3 import jieba.analyse 4 import codecs 5 def cut_words(sentence): 6 #print sentence 7 return " ".join(jieba.cut(sentence)).encode('utf-8') 8 f=codecs.open('wiki.zh.jian.text','r',encoding="utf8") 9 target = codecs.open("wiki.zh.jian.seg.txt", 'w',encoding="utf8") 10 print ('open files') 11 line_num=1 12 line = f.readline() 13 while line: 14 print('---- processing', line_num, 'article----------------') 15 line_seg = " ".join(jieba.cut(line)) 16 target.writelines(line_seg) 17 line_num = line_num + 1 18 line = f.readline() 19 f.close() 20 target.close() 21 exit() 22 while line: 23 curr = [] 24 for oneline in line: 25 #print(oneline) 26 curr.append(oneline) 27 after_cut = map(cut_words, curr) 28 target.writelines(after_cut) 29 print ('saved',line_num,'articles') 30 exit() 31 line = f.readline1() 32 f.close() 33 target.close()
如图:分词完毕
步骤六:分词结束,就可以训练词向量啦
参数说明:
class gensim.models.word2vec.Word2Vec(sentences=None,size=100,alpha=0.025,window=5, min_count=5, max_vocab_size=None, sample=0.001,seed=1, workers=3,min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=<built-in function hash>,iter=5,null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000)
参数含义如下(转自http://blog.csdn.net/szlcw1/article/details/52751314):
· sentences:可以是一个·ist,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
· window:表示当前词与预测词在一个句子中的最大距离是多少
· alpha: 是学习速率
· seed:用于随机数发生器。与初始化词向量有关。
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
· workers参数控制训练的并行数。
· hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
· negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
· hashfxn: hash函数来初始化权重。默认使用python的hash函数
· iter: 迭代次数,默认为5
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
· sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
· batch_words:每一批的传递给线程的单词的数量,默认为10000
· sentences:可以是一个·ist,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
· window:表示当前词与预测词在一个句子中的最大距离是多少
· alpha: 是学习速率
· seed:用于随机数发生器。与初始化词向量有关。
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
· workers参数控制训练的并行数。
· hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
· negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
· hashfxn: hash函数来初始化权重。默认使用python的hash函数
· iter: 迭代次数,默认为5
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
· sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
· batch_words:每一批的传递给线程的单词的数量,默认为10000
具体代码如下:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import logging 4 import os 5 import sys 6 import multiprocessing 7 wiki.zh.text.model wiki.zh.text.vector 8 from gensim.models import Word2Vec 9 from gensim.models.word2vec import LineSentence 10 11 if __name__ == '__main__': 12 program = os.path.basename(sys.argv[0]) 13 logger = logging.getLogger(program) 14 15 logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s') 16 logging.root.setLevel(level=logging.INFO) 17 logger.info("running %s" % ' '.join(sys.argv)) 18 19 # check and process input arguments 20 if len(sys.argv) < 4: 21 print(globals()['__doc__'] % locals()) 22 sys.exit(1) 23 inp, outp1, outp2 = sys.argv[1:4] 24 25 model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, 26 workers=multiprocessing.cpu_count(),iter=100)#向量维度是400维,迭代100次 27 28 # trim unneeded model memory = use(much) less RAM 29 # model.init_sims(replace=True) 30 model.save(outp1) 31 model.wv.save_word2vec_format(outp2, binary=False)
使用命令开始训练
python train_word2vec_model.py wiki.zh.jian.seg.txt wiki.zh.text.model wiki.zh.text.vector
训练过程如下图:
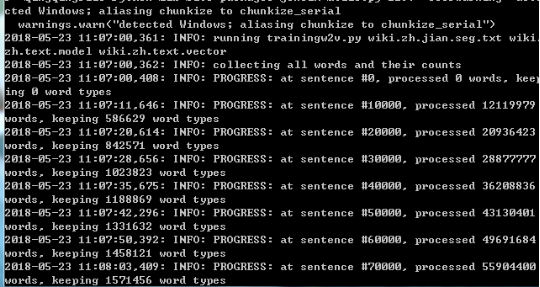
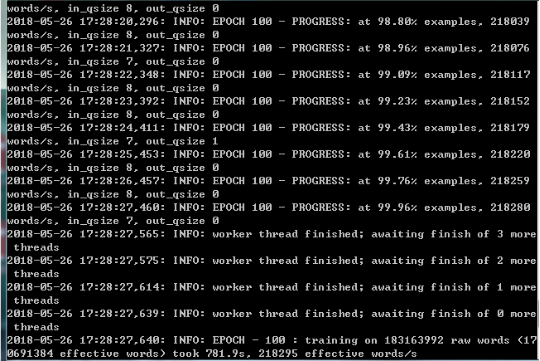
迭代到100轮:
保存结果如图,表示结束:
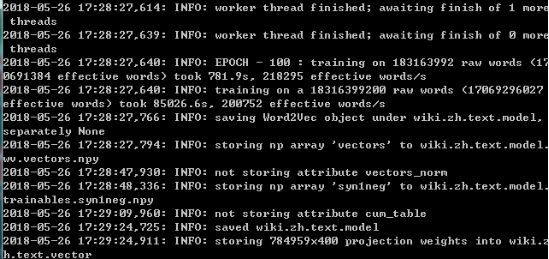
这时候就表示训练好了,现在就可以开始使用啦!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号