
Windows下基于python3使用word2vec训练中文维基百科语料(一)
在进行自然语言处理之前,首先需要一个语料,这里选择维基百科中文语料,由于维基百科是 .xml.bz2文件,所以要将其转换成.txt文件,下面就是相关步骤:
步骤一:下载维基百科中文语料
https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
然后解压文件

文件夹里是一个这个文件

步骤二:安装依赖库
我们需要安装一些依赖库,有numpy、scipy以及gensim,安装gensim依赖于scipy,安装scipy依赖于numpy。我们直接用pip安装numpy,在windows命令行下使用命令:
1 pip install numpy
2 pip install scipy
3 pip install gensim
步骤三:将xml.bz2文件转换成.text文件
注意:我在网上找的代码,通常说会因为python2和python3的版本不同在使用python3进行解压会在output.write(space.join(text) + "\n")这一句出现提示关于byte或str的错误,
但是我用了python3修改的代码,反而出现错误,其实现在下载的语料直接用python2的代码也可以。
*********不过为了有些人可能采用下面代码会出现byte和str的错误,我将之前网上找的对于python3代码的修改依然保留(32-40行)***********************
(1)写代码 命名为process_wiki.py
2 # -*- coding:utf-8 -*-
3 # Author:Gao
4 import logging
5 import os.path
6 import six
7 import sys
8 import warnings
9
10 warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
11 from gensim.corpora import WikiCorpus
12
13 if __name__ == '__main__':
14 program = os.path.basename(sys.argv[0])
15 logger = logging.getLogger(program)
16
17 logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
18 logging.root.setLevel(level=logging.INFO)
19 logger.info("running %s" % ' '.join(sys.argv))
20
21 # check and process input arguments
22 if len(sys.argv) != 3:
23 print("Using: python process_wiki.py enwiki.xxx.xml.bz2 wiki.en.text")
24 sys.exit(1)
25 inp, outp = sys.argv[1:3]
26 space = " "
27 i = 0
28
29 output = open(outp, 'w',encoding='utf-8')
30 wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
31 for text in wiki.get_texts():
32 # if six.PY3:
33 # output.write(b' '.join(text).decode('utf-8') + '\n')
34
35
36
37
38
39 # else:
40 # output.write(space.join(text) + "\n")
41 output.write(space.join(text) + "\n")
42 i=i+1
43 if (i%10000==0):
44 logger.info("Saved " + str(i) + " articles")
45
46 output.close()
47 logger.info("Finished Saved " + str(i) + " articles")
(2)运行代码(在cmd中运行)
首先到自己下载的中文维基百科预料的文件夹下,将自己的语料库和执行文件放在同一个文件夹下,这样方便执行,然后进入放置这两个文件的文件夹下(我的在f盘)
python process_wiki.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text

(3)运行结果(运行时间比较长,耐心等待,后面就出结果啦)
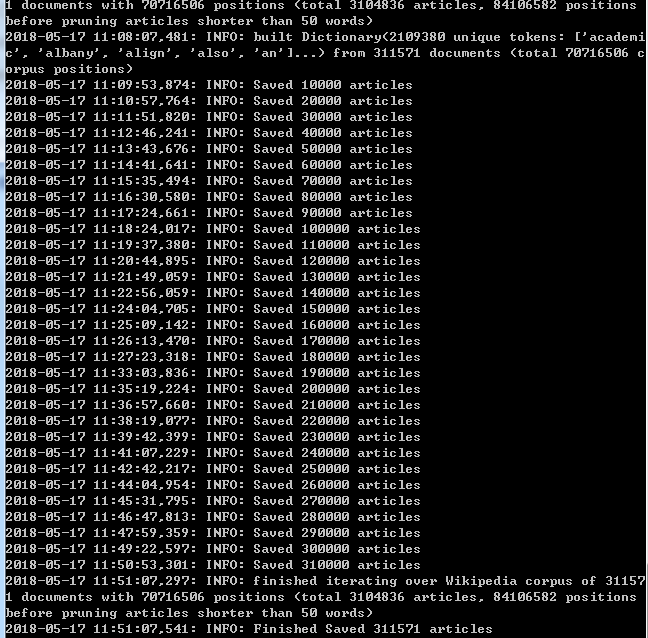
现在我们就得到了处理后的中文维基百科.txt文档,下一篇我们将进一步对文档进行处理
相关参考:https://www.jianshu.com/p/98d84854f7a3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号