1.res.text ---> 将响应对象转化为str类型 --->如果你的响应数据是HTML,可以使用text转化为str
import re
import requests
import pymysql
# 确定url,向服务器发起请求
url = 'https://www.guidaye.com/' #抓包
res = requests.get(url=url) #get请求步及到几个参数
res.encoding = "gbk" #乱码转中文
# 数据解析: res.text就是str
titles = re.findall(r'<li><a title="(.*?)" href="/cp/\d+.html">.*?</a></li>',res.text)
print(titles)
# 数据持久化
conn = pymysql.connect(host = 'localhost',
user = 'root',
password = 'root123',
port = 3306,
charset = 'utf8',
database = 'pachong')
cursor = conn.cursor()
for title in titles:
sql = "insert into gs values ('%s')"%title
try:
cursor.execute(sql)
conn.commit()
print('成功')
except:
conn.rollback()
print('失败')
2.res.json()--->将响应对象转化为python的dict类型,形式(类json):
import json
import requests
url = 'http://you.163.com/xhr/globalinfo//queryTop.json?__timestamp=1594373402392'
res = requests.get(url=url)
ret = res.json()
# ret = json.loads(res.text) #json.loads把长得跟字典一样的字符串转换为字典
# print(ret)
# print(type(ret))
for item in ret['data']['cateList']: print(item['name'])
print(item['name'])
import requests
import json
url = 'https://temp.163.com/special/00804KVA/cm_yaowen20200213.js?callback=data_callback'
res = requests.get(url=url)
res = res.text.replace('data_callback(', '') #替换
res = res.strip(')') #切割
ret = json.loads(res)
for item in ret:
print(item['title'])

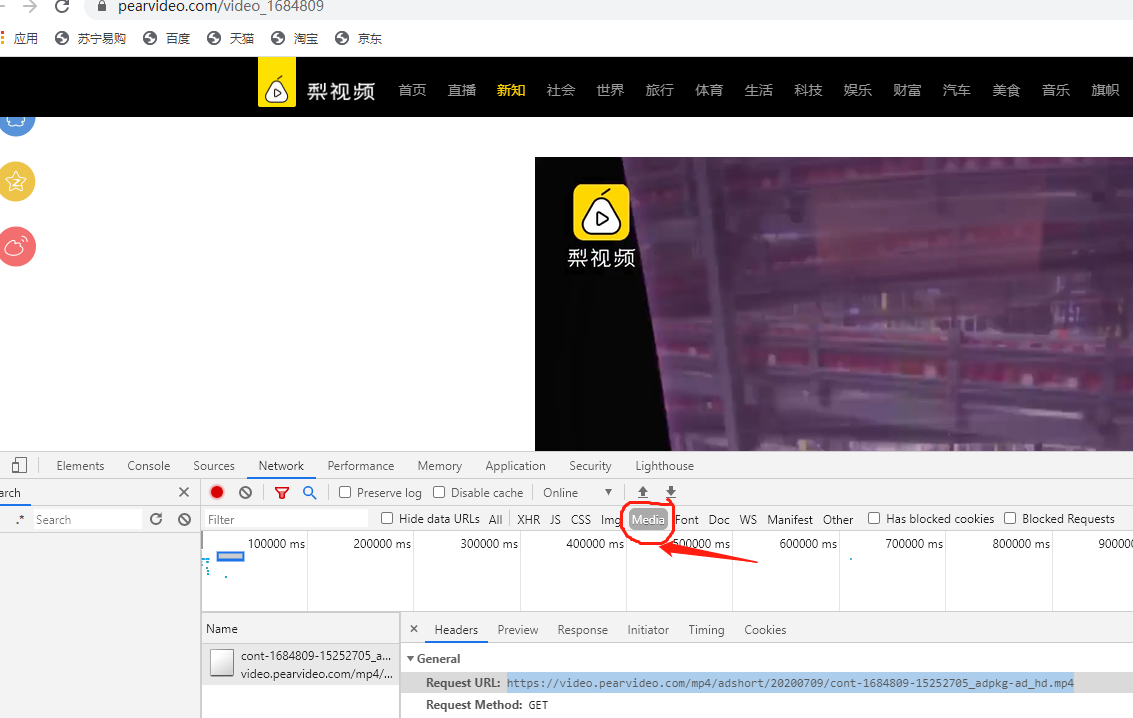
3.res.content--->流行式:图片就是流形式
import requests
url = 'https://video.pearvideo.com/mp4/adshort/20200709/cont-1684809-15252705_adpkg-ad_hd.mp4'
res = requests.get(url=url)
with open('k.mp4','wb')as f:
f.write(res.content) #conteent 流数据
#url 找流播图最长的一个 在播放的时候抓 找不到 到Media里面抓取