
Python爬虫之Lxml库与Xpath语法
Lxml库是基于lbxml2的XML解析库的Python封装。
作用:使用Xpath语法解析定位网页数据。
LXMl库的安装与使用方法
Lxml库的安装
windows系统下的安装:


#pip安装 pip3 install lxml #wheel安装 #下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
linux下安装:
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel pip3 install lxml
Lxml库使用
修正HTML代码
Lxml为XML的解析库,很好的支持了HTML文档的解析功能。
from lxml import etree text=""" one """ html1=etree.HTML(text) print(html1)
etree库把HTML文档解析为Element对象,可以通过以下代码输出解析过的HTML文档
from lxml import etree text=""" one """ html1=etree.HTML(text) print(html1) result=etree.tostring(html1) print(result)
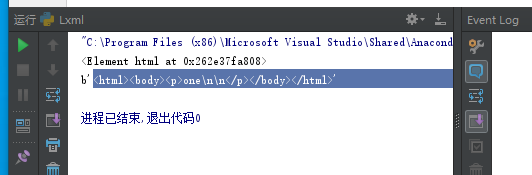
通过运行程序我们可以看出,Lxml库自动补全了HTML代码。
读取HTML文件
通过PyCharm新建一个.html文件
<!DOCTYPE html> <html lang="en"> <head> <title>flower</title> </head> <body> one </body> </html>
from lxml import etree html1=etree.parse('flower.html') result=etree.tostring(html1,pretty_print=True) print(result)
解析HTML文件
import requests from lxml import etree headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362' } res=requests.get('https://book.douban.com/',headers=headers) html=etree.HTML(res.text) result=etree.tostring(html) print(result)
Xpath语法
节点关系
父节点
每个元素及其属性都有一个父节点,例如
<user> <name>xiao ming</name> <sex>JK. Rowling</sex> <id>34</id> <goal>89</goal> </user>
其中user元素为name,sex,id,goal元素的父节点
子节点
元素节点可有0个,一个,或者多个自节点,在上述例子中name,sex,id,goal为user的子节点。
同胞节点
name,sex,id,goal互为同胞节点,即同胞节点有相同的父亲节点
先辈节点
先辈节点为某元素的父节点和父节点的父节点
后代节点
某节点的子节点和子节点的子节点
节点选择
Xpath使用路径表达式在XML文档中选取节点,节点是通过沿着路径或者step来选取的

使用技巧
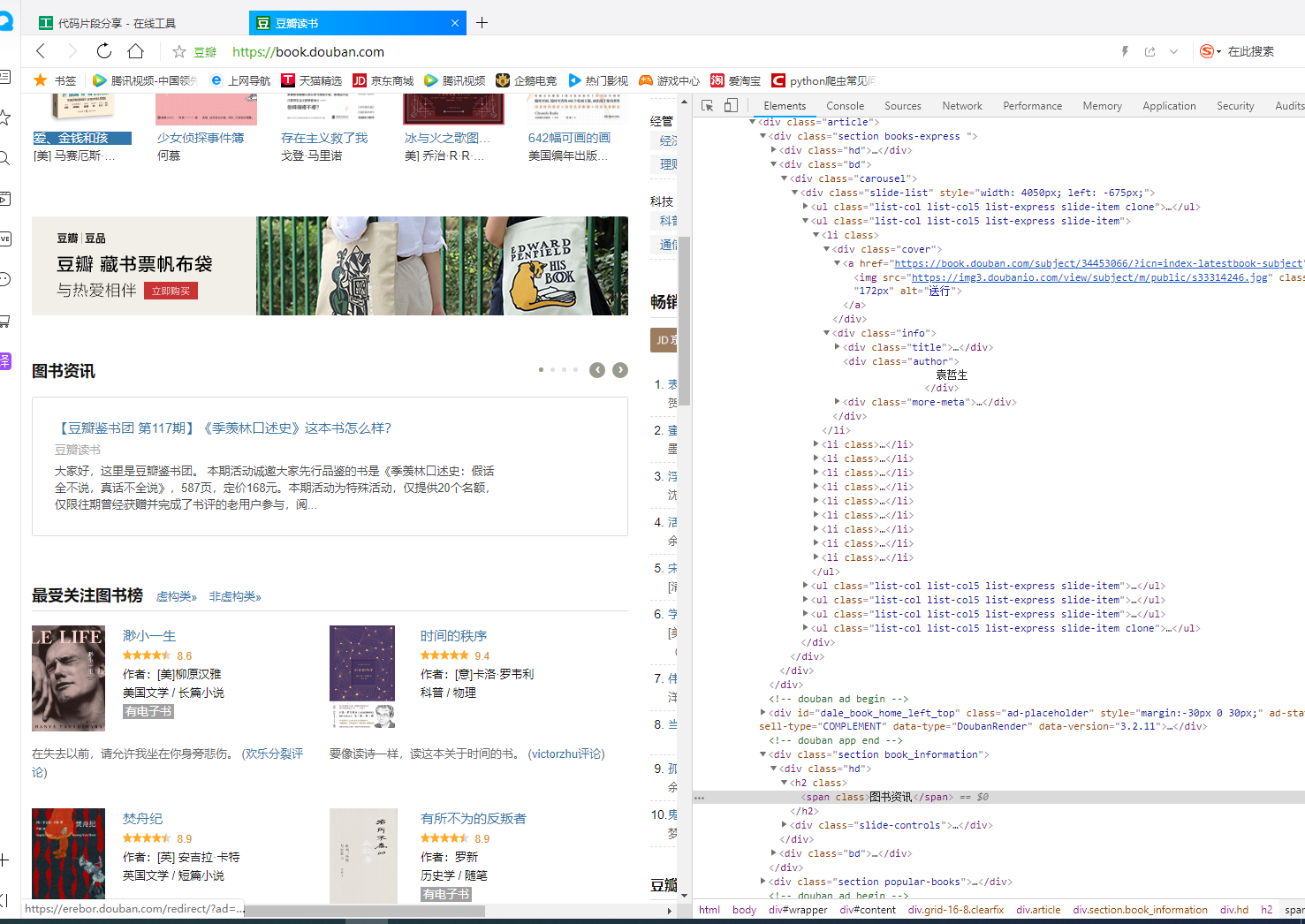

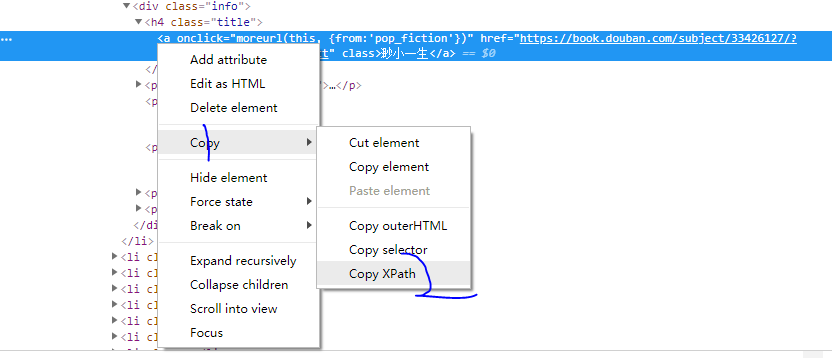
import requests from lxml import etree headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400' } #//*[@id="content"]/div/div[1]/div[1]/div[2]/div/div/ul[2]/li[1]/div[1]/a/img res=requests.get('https://book.douban.com',headers=headers) selector=etree.HTML(res.text) img=selector.xpath('//*[@id="content"]/div/div[1]/div[4]/div[2]/ul/li[1]/div[2]/h4/a/text()')[0] print(img)
通过/text()获取标签内的文字信息

posted on 2019-07-31 15:48 一颗小白杨站在哨所旁 阅读(175) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步