变分贝叶斯推断
变分贝叶斯推断
变分原理
《动态最优化基础》中关于 泛函 和 变分 的推导。





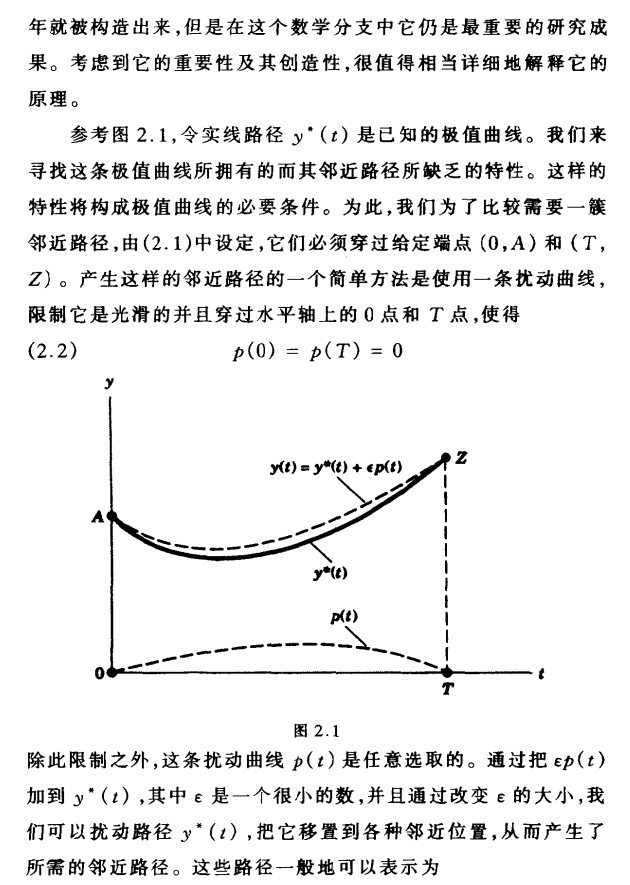






Euler-Lagrange方程:
或者
\(F[t,y(t),y^\prime(t)]\) 表示“弧值”的一般表达式
\(F[t,y(t),y^\prime(t)]dt\) 表示t处的一段微小“弧值”
\(V[y]=\int_0^T F[t,y(t),y^\prime(t)]dt\) 表示“弧值之和”
“弧值”的含义可以是 距离、时间、质量、概率 等等。
例,连接两点间的最短曲线
现在要找到“最短曲线”,意味着我们需要关于弧值为长度的一个泛函。
两点间长度的一般表达式 \(S=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\)
曲线 \(y(x)\) 上任意相邻的两点 \((x,y),(x+dx,y+dy)\) 微小“弧值”为:
设曲线的两端点为 \((a, m)\) 和 \((b, n)\) 则“弧值之和”
由Euler-Lagrange方程: \(\dfrac{\partial F}{\partial y}-\dfrac{d}{dx}\dfrac{\partial F}{\partial y^\prime}=0\)
F中不包含y, 有 \(\dfrac{\partial F}{\partial y}=0\), \(\dfrac{\partial F}{\partial y^\prime}=\dfrac{y^\prime}{\sqrt{1+{y^\prime}^2}}\) 代入欧拉方程:
所以 \(\dfrac{y^\prime}{\sqrt{1+{y^\prime}^2}}=C\)常数,求得 \(y^\prime=C\), 然后对 \(y^\prime\) 求积分有:
变分贝叶斯推断
变分推理的目标是近似潜在变量(latent variables)在观测变量(observed variables)下的条件概率。解决该问题,需要使用优化方法。在变分推断中,需要使用到的一个重要理论,是平均场理论.
平均场理论
来源于物理学,是一种研究复杂多体问题的方法,将数量巨大的互相作用的多体问题转化成每一个粒子处在一种弱周期场中的单体问题。
对于概率模型:
可以找到一个近似模型:
使得 Q 与 P 尽可能相似。
在贝叶斯模型中, 通常需要从已知的样本中推测模型的参数,即 后验概率 \(P(Z|X)\), 然而 直接计算出\(P(Z|X)\)通常比较困难。我们可以利用平均场理论,通过模型 \(Q(Z)=\prod_i Q(z_i)\) 来近似代替 \(P(Z|X)\)。
衡量两个概率密度函数(PDF)的差异,可以利用KL散度(KL-Divergence)。
这里 \(KL(Q(Z)||P(Z|X))\) 即是关于 Q 的泛函。为使 Q 和 P 尽可能相似,则需要KL最小化。
求解KL最小化下,Q 的概率密度函数,即变分问题。其中 Q 的累积分布函数(CDF) \(\int Q(Z)dz =1\) 。
令\(L(Q)=-[\int Q(Z) logP(Z)dZ - \int Q(Z)logP(Z,X)dZ]\), 则有
\(logP(X)\)的下界\(L(Q)\), 称为 ELOB (Evidence Lower Bound), 其中\(logP(X)\)为常数,通过最大化ELOB \(L(Q)\) 使得KL最小化。 求解最大化\(L(Q)\)的过程同样也是一个变分问题。
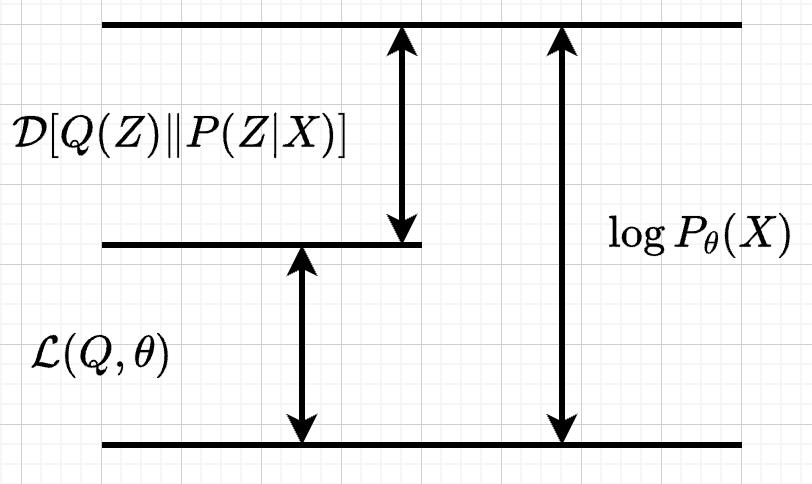
把平均场定理:\(Q(Z)=\prod_i Q(z_i)\) 代入 \(L(Q)\) 中得到:
其中\(Q^*(z_j)=\dfrac{exp(E_{i\neq j}[logP(Z,X)])}{\int exp(E_{i\neq j}[logP(Z,X)])}\), 归一化项 \(\int exp(E_{i\neq j}[logP(Z,X)])\) 使得整体的\(Q^*(z_j)\) PDF积分为1。详细推理过程参考变分贝叶斯推断(Variational Bayes Inference)简介
因为 信息熵\(\prod_{i;i\neq j}H(Q(z_i))\geq 0, 且 KL(Q(z_j)||Q^*(z_j)) \geq 0\)
所以 最大化\(L(Q)\)只需令\(KL(Q(z_j)||Q^*(z_j))=0\), 则有:
至此,变分贝叶斯推断的通用公式求法,如下:
- 循环直到收敛:
- 对于每个\(Q(z_j)\):
- 令\(Q(z_j) = Q^*(z_j)\)
参考文章:
《动态最优化基础》蒋中一

 浙公网安备 33010602011771号
浙公网安备 33010602011771号