

URL编码
URL的特性
可移植性
URL需要通过各种不同的协议来传送,那么组成URL的字符就要求被所有网络协议所识别,只能使用通用的安全字母表中的字符。
URL字符使用的是US-ASCII 字符集,也叫做标准7位ASCII
可阅读性
US-ASCII中有些字符虽然是可移植的,但因为不可见、不可打印,无法阅读,所以也不能在 URL 中使用。7位ASCII共有128个字符,其中33个不可打印字符,95个为可打印字符
完整性
URL 中包含除通用的安全字符以外,有时候还希望包含一些非安全字符,比如汉字。这就需要我们对这些非安全字符进行编码。编码成ASCII码中安全的字符。
另外,ASCII码95个可打印字符中有些在URL中被用于特殊用途或者留待将来用于特殊用途。这些特殊字符往往用来分隔URI组件或者子组件的分隔符。
Url可以划分成若干个组件,协议、主机、路径等。
有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。
还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。
服务器端在解析URL时,就是使用这些具有特殊意义的分割符将URL解析成各个组件(协议,主机,路径,参数字符串)或者子组件(参数字符串中的键和值)
但这些特殊字符用于特殊用途之外时,就会造成歧义,也需要进行编码。比如=用于分割键和值时(如a=eee),不需要进行编码,但如果=作为字符串值中的一个字符时(如a=ee=e, ee=e为一个字符串值),就必须要编码
总结:组成URL的字符只能是7位ASCII码中的95个可打印字符。
当URL中包含有95个可打印字符以外的字符时,则必须对这些字符进行编码
当95个可打印字符中的特殊字符被用于特殊用途时,不能被编码,但如果被用于非特殊用途时也必须要进行编码,如上面=的用途。
当95个可打印字符中没有特殊意义的安全字符,可以编码,也可以不编码
URL中的特殊字符(保留及受限字符)

URL的编码机制
URL的编码机制非常简单。
一个字符在字符集中的编码值就是一个数字。这个数字可能由一个或多个字节组成。
URL编码就是在这个字符对应的编码值的每个字节前加上%,并且用16进制来表示。
比如如果要编码a,a在ASCII字符集中的编码值为97(10进制),ASCII字符集都是单字节字符,那么二进制表示就是 0110 0001,十六进制表示就是61,所以进行编码后就是%61
即使是同一个字符,在不同的字符集中可能具有不同的编码值,而且可能由不同数目的字节组成。所以使用不同的字符集对字符进行的编码也不相同。
比如 "春" 字,在utf-8中的编码值为 "E6 98 A5" ,由3个字节组成,URL编码后就是"%E6%98%A5"。
而在GB2312中,"春" 字的编码值为"B4 BA", 所以URL编码后就是"%B4%BA"
由于历史的原因,有一些Url编码实现并不完全遵循这样的机制
URL的编码的现状
网络标准RFC 1738对URL的字符组成做了硬性规定,没有规定具体的编码方法和编码字符集,而是交给应用程序(浏览器)自己决定。这导致"URL编码"成为了一个混乱的领域。
前辈们的关于浏览器的默认URL编码的结论如下。随着浏览器版本的更新以下结论可能并不适应,仅供参考,了解下现状。
结论1就是,网址路径的编码,用的是utf-8编码。 (测试方法:浏览器中直接输入网址)
结论2就是,查询字符串的编码,用的是操作系统的默认编码。(测试方法:浏览器中直接输入网址)
结论3就是,GET和POST方法的编码,用的是网页的编码。(测试方法:在已打开的网页上,直接用Get或Post方法发出HTTP请求)
这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
结论4就是,在Ajax调用中,IE总是采用操作系统的默认编码,而Firefox总是采用utf-8编码。(测试方法:由Javascript生成HTTP请求,也就是Ajax调用)
由此可见,应用程序自己进行URL编码时,在服务器端无法判断使用了那种字符集进行的编码,所以在解码时就可能使用了错误的字符集进行解码,从而造成乱码。
解决这种问题的方法就是手动对URL用已知的字符集进行编码,不给应用程序插手的机会。如使用javaxcript中的encodeURI和encodeURIComponent等进行编码。
Javascript中的escape, encodeURI和encodeURIComponent的区别
安全字符不同:
- escape(69个):*/@+-._0-9a-zA-Z
- encodeURI(82个):!#$&'()*+,/:;=?@-._~0-9a-zA-Z
- encodeURIComponent(71个):!'()*-._~0-9a-zA-Z
encodeURI比encodeURIComponent多了11个安全字符 # $ & + , / : ; = ? @
对Unicode字符的编码方式不同:
对于ASCII字符,这三个函数的编码方式相同,均是使用百分号+两位十六进制字符来表示。
对于Unicode字符,escape的编码方式是%uxxxx,其中的xxxx是用来表示unicode字符的4位十六进制字符。这种方式已经被W3C废弃了。但是在ECMA-262标准中仍然保留着escape的这种编码语法。encodeURI和encodeURIComponent则使用UTF-8对非ASCII字符进行编码,然后再进行百分号编码。这是RFC推荐的。因此建议尽可能的使用这两个函数替代escape进行编码。
适用场合不同:
encodeURI被用作对一个完整的URI进行编码,而encodeURIComponent被用作对URI的一个组件进行编码。
从上面提到的安全字符范围表格来看,我们会发现,encodeURIComponent编码的字符范围要比encodeURI的大。我们上面提到过,保留字符一般是用来分隔URI组件(一个URI可以被切割成多个组件,参考预备知识一节)或者子组件(如URI中查询参数的分隔符),如:号用于分隔scheme和主机,?号用于分隔主机和路径。由于encodeURI操纵的对象是一个完整的的URI,这些字符在URI中本来就有特殊用途,因此这些保留字符不会被encodeURI编码,否则意义就变了。
组件内部有自己的数据表示格式,但是这些数据内部不能包含有分隔组件的保留字符,否则就会导致整个URI中组件的分隔混乱。因此对于单个组件使用encodeURIComponent,需要编码的字符就更多了。
总结:
escape函数基本上被废弃,尽量不要使用。
encodeURI和encodeURIComponent都是使用utf-8进行URL编码。并且对各自的安全字符不会进行编码。两者的安全字符范围不同,如前面所说。
encodeURI不会对URL中的某些特殊字符进行编码,比如:/?&=@等等。因此可用于对整个URL进行编码。这里说的某些字符就是encodeURI比encodeURIComponent多了的11个安全字符
encodeURIComponent会对URL中的某些特殊字符进行编码,只能对某个URL组件或者子组件进行编码。比如传递参数中的值。
实例
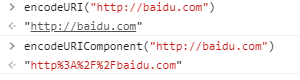
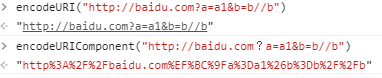
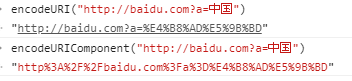
由以上实例可以看出,当URL组件或者子组件内部不包含某些特殊字符时,可以直接使用encodeURI对整个URL进行编码,
如果URL当URL组件或者子组件内部包含某些特殊字符时,则不能使用encodeURI对整个URL进行编码,而是需要使用encodeURIComponent分别对各个组件或者子组件进行编码
另外,很多HTTP监视工具或者浏览器地址栏等在显示Url的时候会自动将Url进行一次解码(使用UTF-8字符集),这就是为什么当你在Firefox中访问Google搜索中文的时候,地址栏显示的Url包含中文的缘故。但实际上发送给服务端的原始Url还是经过编码的。你可以在地址栏上使用Javascript访问location.href就可以看出来了。在研究Url编解码的时候千万别被这些假象给迷惑了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号